导语
【免费下载链接】LFM2-8B-A1B-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
Liquid AI推出的LFM2-8B-A1B混合专家模型,以83亿总参数实现15亿激活参数的高效推理,在智能手机等终端设备上实现媲美3-4B稠密模型的性能,重新定义边缘AI计算范式。
行业现状:从云端依赖到终端智能的转型浪潮
2025年全球智能终端市场正经历深刻变革。IDC最新报告显示,中国AI智能终端市场规模预计突破5347.9亿元,其中AI手机、平板和PC出货量同比增长20%。随着用户对实时响应和隐私保护需求的提升,传统云端集中式计算模式面临延迟高、带宽占用大等瓶颈,边缘AI成为必然趋势。
当前终端AI部署面临三大挑战:模型性能与设备算力的矛盾、多语言处理能力不足、复杂任务处理效率低下。Liquid AI推出的LFM2-8B-A1B模型正是针对这些痛点,通过混合专家架构实现"大模型能力、小模型效率"的突破,为智能终端提供了新的计算解决方案。
核心亮点:混合专家架构的四大突破
1. 创新混合架构设计
LFM2-8B-A1B采用24层混合架构(18个卷积块+6个注意力块),创新性地融合Grouped Query Attention(GQA)机制与LIV卷积模块。这种设计使模型在保持轻量化的同时,实现知识推理、数学计算和多语言能力的全面提升。
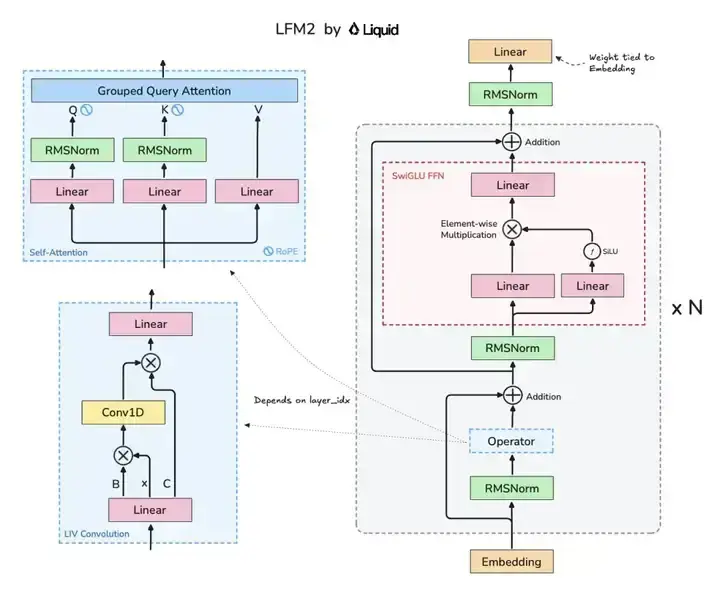
如上图所示,该架构图清晰展示了LFM2模型的核心组件布局,包括GQA注意力机制与LIV卷积模块的协同设计。这种混合架构是实现小模型高性能的关键,为开发者理解高效模型设计提供了直观参考。
2. 极致性能优化
LFM2-8B-A1B在推理速度上实现显著突破。实测数据显示,在三星Galaxy S24 Ultra等高端手机上,采用INT4量化技术的模型解码吞吐量比Qwen3-1.7B快5倍,在AMD Ryzen AI 9 HX370处理器上,解码速度达到同类模型的2倍。这种效率提升使终端设备无需高端硬件即可流畅运行复杂AI任务。
模型量化技术的应用进一步降低部署门槛:Q4_0量化版本仅需1.5GB存储空间,F16版本约5.2GB,可适配大多数现代智能终端。同时支持llama.cpp、vLLM和Transformers等主流框架,开发者可根据需求灵活选择部署方案。
3. 多语言与工具调用能力
LFM2-8B-A1B原生支持英、中、日、韩等8种语言,在MMMLU多语言基准测试中获得55.26分,超越LFM2-2.6B和Llama-3.2-3B等竞品。其创新的工具调用机制通过<|tool_list_start|>和<|tool_response_end|>等特殊标记,实现函数定义、调用和结果解析的全流程支持,为智能助手、自动化办公等场景提供强大支撑。
4. 动态混合推理机制
作为该系列唯一采用动态混合推理的模型,LFM2-8B-A1B能根据输入复杂度智能调配计算资源。对于简单任务仅激活基础专家模块,面对多语言或复杂逻辑推理时自动调用增强模块,实现资源利用效率最大化。这种自适应机制使模型在创意写作、RAG检索增强和多轮对话等场景中表现出色。
性能评测:小参数大能力的实证
在标准化基准测试中,LFM2-8B-A1B展现出超越同规模模型的实力:
知识与推理能力
- MMLU得分64.84,超过Llama-3.2-3B(60.35)和SmolLM3-3B(59.84)
- IFEval指令跟随能力达77.58,接近gemma-3-4b-it(76.85)
- GPQA知识问答29.29,与同类模型相当
数学能力
- GSM8K数学推理84.38,优于LFM2-2.6B(82.41)和Llama-3.2-3B(75.21)
- MGSM多语言数学72.4,展现跨语言问题解决能力
- MATH 500测试74.2,其中Level 5难题正确率达62.38
这些指标表明,LFM2-8B-A1B以15亿激活参数实现了媲美3-4B稠密模型的性能,验证了混合专家架构在效率与性能平衡上的优势。
行业影响与应用前景
LFM2-8B-A1B的推出恰逢边缘AI技术爆发期,其创新架构和高效推理特性将在多个领域产生深远影响:
1. 消费电子领域
随着AI手机市场份额持续扩大(2025年Q1全球AI手机出货量TOP5厂商占比达97%),LFM2-8B-A1B将成为终端厂商差异化竞争的关键。其低功耗特性可延长设备续航,而本地化推理能力解决了云端服务依赖问题,特别适合网络不稳定环境。
2. 工业与物联网
在智能制造场景中,LFM2-8B-A1B可部署于边缘网关,实现实时缺陷检测和质量控制。某试点项目显示,边缘部署AI模型使交通信号响应速度提升7倍,带宽成本下降90%,这为工业质检、智能交通等场景提供了可复制的解决方案。
3. 医疗健康
本地化推理确保患者数据隐私安全,符合HIPAA等合规要求。LFM2-8B-A1B在医疗影像分析、多语言问诊等场景的应用,将推动远程医疗向基层延伸,尤其在语言多样性地区具有独特优势。
部署指南与生态支持
开发者可通过以下方式快速部署LFM2-8B-A1B:
获取模型
git clone https://gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
Python推理示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "LiquidAI/LFM2-8B-A1B"
model = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", dtype="bfloat16"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
prompt = "What is C. elegans?"
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True, return_tensors="pt"
).to(model.device)
output = model.generate(
input_ids, temperature=0.3, min_p=0.15,
repetition_penalty=1.05, max_new_tokens=512
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Liquid AI提供完整的微调工具链,包括SFT和DPO等技术方案,开发者可针对特定领域优化模型性能。社区贡献的Colab笔记本和llama.cpp部署教程进一步降低了使用门槛。
结论与展望
LFM2-8B-A1B的推出标志着边缘AI进入"混合专家"时代。其创新架构证明,通过智能分工而非单纯增加参数,同样可以实现模型能力的跃升。随着终端算力持续增强和模型优化技术进步,我们有理由相信,2025年将成为"终端智能关键发展期"。
对于企业而言,现在正是布局边缘AI的战略窗口期。建议设备厂商重点关注混合专家模型的硬件适配,开发者可利用LFM2-8B-A1B在垂直领域进行微调和创新应用,而用户将迎来更智能、更安全的终端体验。
未来,随着动态路由算法优化和多模态能力增强,混合专家模型有望在智能汽车、AR/VR等更广泛场景落地,推动"万物智能"时代加速到来。
【免费下载链接】LFM2-8B-A1B-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







