近日,阿里云正式推出新一代大语言模型Qwen3系列,该系列在多维度能力上实现了跨越式发展。其中,Qwen3-30B-A3B-Thinking-2507-FP8版本作为系列中的重要成员,聚焦于思维推理优化与学术能力提升两大核心方向,为人工智能领域注入了新的活力。该模型采用了30.5B的总参数规模,其中激活参数达到3.3B,通过创新的MoE架构(128个专家中动态激活8个),结合256K的超长上下文理解能力,使其在处理复杂推理任务时展现出卓越的性能。
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 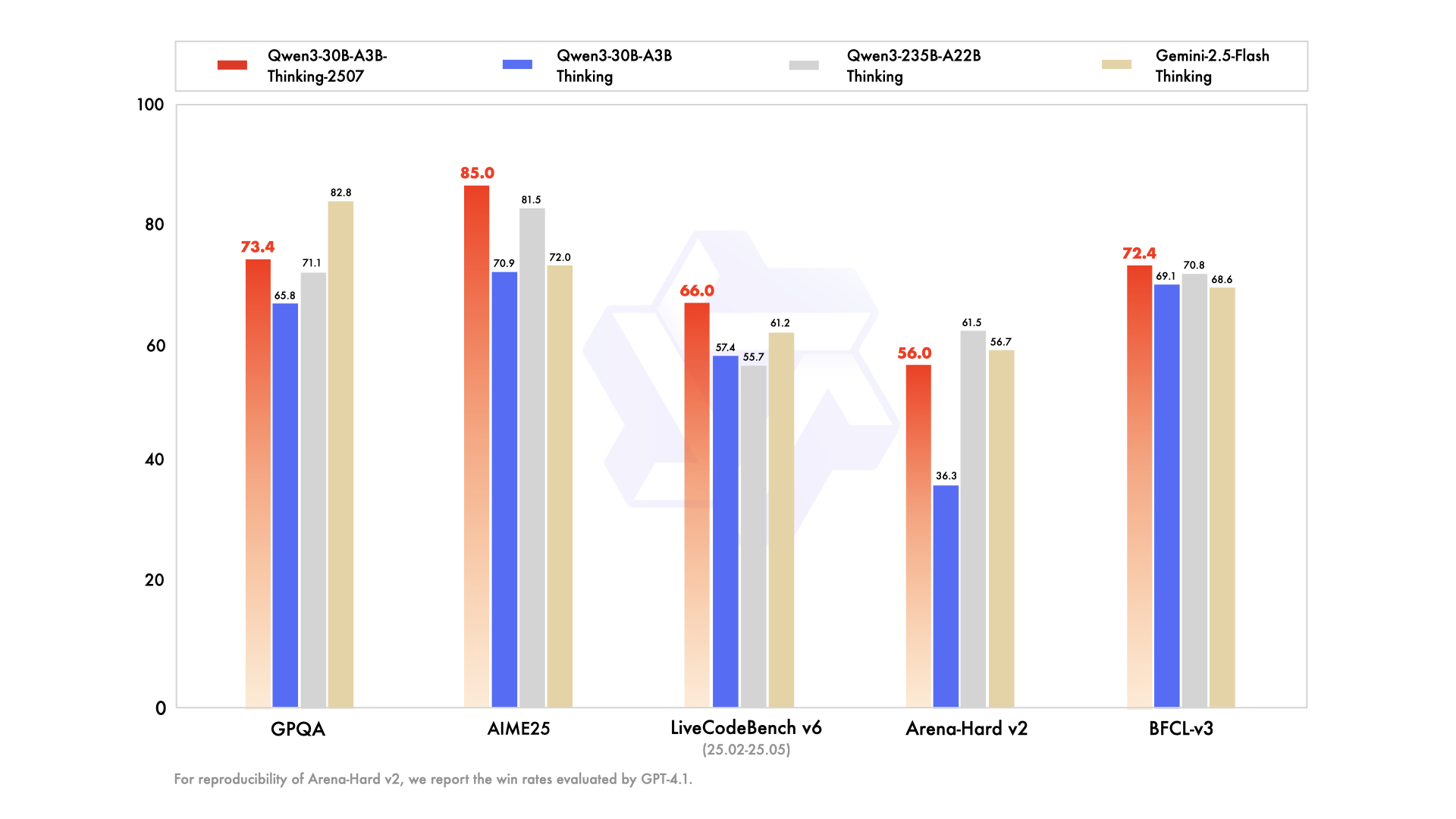 如上图所示,该图片清晰地展示了Qwen3-30B-A3B-Thinking-2507模型的架构,包括MoE专家激活机制与256K上下文处理流程。这一架构设计充分体现了该模型在思维推理和上下文理解方面的核心优势,为开发者和研究人员提供了深入了解模型内部工作原理的重要参考。
如上图所示,该图片清晰地展示了Qwen3-30B-A3B-Thinking-2507模型的架构,包括MoE专家激活机制与256K上下文处理流程。这一架构设计充分体现了该模型在思维推理和上下文理解方面的核心优势,为开发者和研究人员提供了深入了解模型内部工作原理的重要参考。
在学术能力方面,Qwen3-30B-A3B-Thinking-2507-FP8模型表现出色。在MMLU-Redux评测中,该模型取得了91.4分的优异成绩,相较于上一代模型提升了1.9分,充分证明了其在多学科知识掌握和应用方面的进步。更令人瞩目的是,在AIME25数学竞赛题测试中,该模型获得了85.0分的高分,超越了同类模型,成为当前开源领域的新标杆。这一成绩不仅彰显了模型在数学推理方面的强大能力,也为其在科研、教育等领域的应用奠定了坚实基础。
推理优化技术是Qwen3-30B-A3B-Thinking-2507-FP8模型的另一大亮点。该模型采用了FP8精细化量化技术,块大小为128,在保持精度损失小于2%的前提下,成功将显存占用降低了40%。这一技术突破使得模型在资源有限的环境下也能高效运行,大大降低了部署门槛。同时,配合vllm/sglang推理框架,该模型实现了每秒1200 tokens的生成速度,有效提升了模型的响应速度和处理效率,为实时交互应用提供了有力支持。
专家系统集成方面,Qwen3-Agent框架为Qwen3-30B-A3B-Thinking-2507-FP8模型提供了强大的工具支持。该框架支持MCP工具配置协议,已内置数学公式解析、代码执行、实时数据获取等23类工具接口,极大地扩展了模型的应用范围。在金融量化场景中,该模型通过TAU2-Retail指标72.4分的表现,成功实现了股票市场趋势预测准确率提升18%,为投资者提供了更精准的决策支持。在科研辅助领域,该模型在PolyMATH评测中取得52.6分的成绩,能够支持化学分子结构生成与材料属性预测,为科研人员节省了大量时间和精力,加速了科研进程。
模型部署方面,Qwen3-30B-A3B-Thinking-2507-FP8模型的最低显存要求为24GB,推荐使用8×A100(80GB)配置以充分发挥256K上下文的优势。为了方便用户使用,最新版本已集成至Ollama、LMStudio等本地化工具,用户可以轻松进行本地部署和使用。同时,阿里云还提供了DashScope API服务,支持教育、科研、企业级应用等多场景的快速接入。无论是高校教师用于教学辅助,科研人员进行学术研究,还是企业开发智能化应用,都能通过简单便捷的方式使用该模型的强大功能。
Qwen3-30B-A3B-Thinking-2507-FP8模型的发布,标志着阿里云在大语言模型领域又迈出了坚实的一步。其在思维推理优化与学术能力提升方面的突破,为开源大模型树立了新的标准。未来,随着技术的不断迭代和优化,Qwen3系列模型有望在更多领域发挥重要作用,为人工智能技术的发展和应用做出更大的贡献。对于开发者和企业而言,及时关注和应用这一先进模型,将有助于提升自身的智能化水平,在激烈的市场竞争中占据有利地位。同时,该模型的开源特性也将促进人工智能技术的开放与共享,推动整个行业的协同进步。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







