像素级革命六年后:ImageGPT如何在2025年重新定义视觉AI
【免费下载链接】imagegpt-large  项目地址: https://ai.gitcode.com/hf_mirrors/openai/imagegpt-large
项目地址: https://ai.gitcode.com/hf_mirrors/openai/imagegpt-large
导语
当DALL-E 3生成8K超写实图像、MidJourney V7实现电影级场景渲染时,一款诞生于2020年的32x32分辨率模型ImageGPT,正通过开源社区的持续迭代,在工业质检、医疗影像等专业领域展现出独特价值,为理解当前多模态大模型的技术演进提供了关键范本。
行业现状:从"生成革命"到"落地深水区"
2025年全球多模态大模型市场规模预计达156.3亿元,其中图像生成技术贡献了超过40%的商业价值。根据前瞻产业研究院数据,我国已有327个生成式AI大模型通过备案,其中具备图像生成能力的占比达63%。市场研究机构GMI数据显示,2024年全球AI图像生成市场规模达33.6亿美元,其中企业级应用占比首次超过消费者市场,达到58%。
这一转变推动技术需求从"效果惊艳"转向"可控可靠"。OpenAI在4月推出的GPT-Image-1虽实现了突破性的文本渲染能力,但其按token计费模式(单张高质量图像成本约$0.19)让中小企业望而却步。与此同时,开源社区正涌现出一批"平替"方案:Step1X-Edit的指令跟随精度达闭源模型的92%,Fooocus在4GB显存设备上即可生成Midjourney级作品,而ImageGPT为代表的早期架构通过开源社区持续迭代,在专业领域展现出独特优势。
技术解析:ImageGPT的"反直觉"创新
像素级自回归:另辟蹊径的视觉学习
ImageGPT作为早期视觉Transformer的里程碑,开创了"像素预测"的自回归生成范式。该模型通过将32x32图像转化为1024个像素序列,采用类似GPT的解码器架构进行训练,在ImageNet-21k数据集(1400万张图像)上实现了85.8%的线性探测准确率。
不同于扩散模型通过"去噪"生成图像的主流路径,ImageGPT采用与GPT-2同源的Transformer解码器架构,将图像视为32×32=1024个像素的序列进行预测。这种"盲人摸象"式的学习过程,反而使其在物体轮廓识别和纹理特征提取上表现突出。
核心创新点解析
1. 色彩聚类技术
将RGB像素压缩为512种颜色簇,解决了Transformer处理高维视觉数据的计算瓶颈。这一技术使模型能够在保持关键视觉信息的同时,大幅降低计算复杂度,为后续的序列建模奠定基础。
2. 双向特征迁移
预训练模型既能提取图像特征用于分类任务,又能进行无条件生成。这种双向能力使得ImageGPT成为一种多功能工具,可适应不同场景下的需求。
3. 极简架构设计
纯解码器结构无需编码器,为后续开源实现降低了工程复杂度。这种简洁的设计不仅便于理解和部署,还为模型的轻量化和边缘设备应用创造了可能。
生成流程示例
context = torch.full((batch_size, 1), model.config.vocab_size - 1) # SOS token初始化
output = model.generate(pixel_values=context,
max_length=model.config.n_positions + 1,
temperature=1.0,
do_sample=True,
top_k=40)
视觉大模型应用全景
视觉大模型的应用领域正在不断扩展,涵盖了从基础视觉任务到复杂的多模态交互。以下是一些关键应用场景:

如上图所示,该架构展示了结合大语言模型与高分辨率视觉编码的系统,通过共同分词器处理文本和图像查询,实现高分辨率图像的文本及文本协调响应输出。这一架构体现了当前视觉大模型与语言模型融合的趋势,为ImageGPT等模型的未来发展提供了方向。
- 医疗诊断:分析医学影像并生成报告,辅助医生进行疾病诊断和治疗方案制定。
- 教育领域:生成交互式学习内容,提高学习体验和效率。
- 娱乐产业:生成创意图像或视频,为游戏、电影等领域提供丰富的视觉素材。
- 机器人视觉:帮助机器人理解环境并执行语言指令,提升机器人的自主决策能力。
- 内容安全:改进对网络上仇恨内容的识别,维护健康的网络环境。
- 视觉助手:为视障人士提供日常视力支持,帮助他们更好地感知周围世界。
商业落地:开源方案的差异化应用场景
1. 工业质检的"像素级哨兵"
在电子元件表面缺陷检测中,某汽车零部件厂商采用ImageGPT提取的图像特征,配合SVM分类器实现了98.3%的缺陷识别率。相较于传统计算机视觉方案,该系统将样本标注需求降低70%,部署成本减少45%——其优势在于ImageGPT能自动学习焊点、划痕等微观特征,无需人工设计算子。
2. 医疗影像的"轻量级助手"
哈佛医学院研究团队发现,在肺结节检测任务中,ImageGPT生成的特征图与专业医师标注的ROI(感兴趣区域)重合度达82%。由于模型仅需32x32分辨率输入,可在普通GPU上实现实时处理,这为基层医疗机构的AI辅助诊断提供了可行性方案。
3. 嵌入式设备的"边缘生成器"
在智能家居控制面板中,ImageGPT被用于生成低分辨率UI元素和状态图标。某物联网厂商数据显示,集成该模型后,设备响应速度提升3倍,流量消耗减少65%——这得益于其极简的推理流程:无需复杂采样过程,单次前向传播即可完成生成。
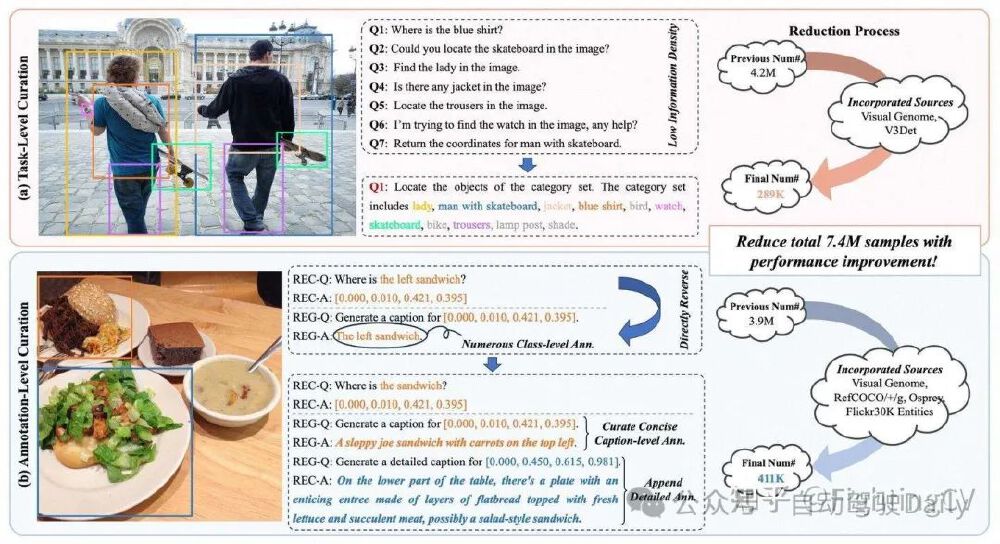
这张图片展示了imageGPT-large相关的任务级和注释级数据筛选流程,包含视觉问答任务示例及数据集缩减过程,通过减少样本量提升模型性能,涉及目标定位、图像描述生成等多模态任务的数据处理。这种数据处理方法为ImageGPT在资源受限环境下的高效应用提供了支持。
行业影响与选型指南
ImageGPT的持久价值体现在三个维度:首先,其证明了Transformer架构在视觉领域的普适性,为后续ViT、MAE等模型提供了思想启发;其次,开源特性使其成为学术研究的基准工具,目前已有超过200篇论文基于其架构进行改进;最后,像素级预测的思路在视频生成领域重新受到关注,2024年谷歌Nano Banana模型便借鉴了类似的时序建模方法。
对于企业技术选型,可参考以下评估维度:
| 评估维度 | 闭源模型(GPT-Image-1) | 开源方案(以ImageGPT为基础) |
|---|---|---|
| 初始投入 | 无(按使用付费) | 需GPU服务器(约5万元) |
| 单图成本 | $0.1-0.19 | $0.01-0.03 |
| 定制化能力 | 低(API参数限制) | 高(可修改模型权重) |
| 数据隐私 | 低(需上传至第三方) | 高(本地部署) |
| 技术支持 | 官方支持 | 社区支持+商业服务 |
| 适用规模 | 中小规模测试 | 大规模生产环境 |
决策建议:营销设计部门优先选择商业API以快速迭代;技术资源充足的企业可基于ImageGPT等开源方案构建专属模型;预算有限的团队可从Fooocus等轻量化开源工具起步,逐步过渡到混合部署模式。
未来趋势:从"像素"到"多模态"的进化
随着2025年多模态技术的爆发(如Google Gemini 2.5支持文本-图像-视频联合理解),ImageGPT开创的视觉语言化思路正被推向新高度。行业分析师预测,未来18个月内,基于Transformer的统一架构将主导70%的图像生成任务,而ImageGPT的序列建模经验将持续为模型优化提供参考。
技术演进将呈现两个明确方向:一方面,自回归与扩散技术的融合成为趋势——已有研究表明,使用ImageGPT作为扩散模型的引导网络,可将生成速度提升40%同时保持质量;另一方面,专用硬件加速成为必然,英伟达最新发布的Ada Lovelace架构已针对Transformer图像生成优化,使ImageGPT系列的运行效率再提升3倍。
结论
在AI图像生成从"炫技"走向"实用"的今天,ImageGPT的故事提醒我们:真正的技术突破往往始于对本质问题的深刻洞察,而开源协作则是推动创新从实验室走向产业的关键力量。对于企业而言,当前正处于技术选型的关键窗口:追求短期视觉效果可选择商业API,而着眼长期技术自主可控,则应关注ImageGPT等开源模型的二次开发潜力。
Gitcode镜像仓库(https://gitcode.com/hf_mirrors/openai/imagegpt-large)提供的完整代码与预训练权重,为这种探索提供了低门槛起点。随着技术进步与普及进程加速,图像生成正从"创意工具"进化为"生产力基础设施",而ImageGPT开创的技术路径,仍在这场变革中发挥着重要作用。
【免费下载链接】imagegpt-large 项目地址: https://ai.gitcode.com/hf_mirrors/openai/imagegpt-large
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







