音频理解新纪元:Qwen3-Omni-Captioner如何重塑12大行业场景
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Captioner
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Captioner 导语
阿里达摩院推出的Qwen3-Omni-30B-A3B-Captioner音频细粒度描述模型,通过多模态技术突破传统音频分析局限,为复杂场景下的音频理解提供新范式,在36项音频基准测试中刷新22项SOTA纪录。
行业现状:音频智能分析的黄金时代
2025年全球音频处理市场规模预计突破300亿美元,年复合增长率维持在12%以上。中国长音频市场规模预计达337亿元,个人智能音频设备出货量将达5.33亿台。随着AI技术与硬件设备的深度融合,音频已从单纯的信息载体进化为情感交互与场景服务的核心入口,但当前通用音频描述模型的缺失制约了行业发展。
全球音频AI工具市场呈现爆发式增长,据QYResearch数据,2024年市场销售额达12.58亿美元,预计2031年将突破26.83亿美元,年复合增长率11.0%。其中,企业级音频分析需求同比增长217%,但现有解决方案普遍存在"重语音转写、轻场景理解"的结构性矛盾,复杂环境下的多声源解析准确率不足65%。
音频内容的指数级增长进一步放大了这一需求缺口——全球音频生成内容(UGC)平台市场规模预计2031年将达945.8亿元,而人工标注成本占内容运营支出的35%以上。传统音频分析模型受限于单模态设计,在"婴儿哭声+电视声"等混合场景中错误率高达42%,难以满足工业级应用需求。
核心亮点:五大技术突破
1. 端到端音频理解架构
基于Qwen3-Omni-30B-A3B-Instruct基座模型微调,实现从音频输入到文本输出的端到端处理,无需额外提示词即可自动解析复杂音频场景。支持30秒内音频的精细化分析,在多说话人情感识别、环境音分层解析等任务上表现突出。
2. 多模态语义融合能力
创新融合音频频谱特征与文本语义理解,在语音场景中可识别多语言表达、文化语境及隐含意图;在非语音场景中能区分复杂环境音的动态变化细节,如电影音效中的空间层次与情绪张力。
3. 低幻觉高精度输出
通过"思考器"(thinker)机制实现推理过程可解释性,显著降低传统模型常见的内容虚构问题。在标准测试集上的描述准确率达92.3%,细节完整性较同类模型提升40%。
4. 灵活部署方案
支持Hugging Face Transformers与vLLM两种部署方式,后者可实现多GPU并行推理,吞吐量提升3-5倍。模型仓库地址:https://gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Captioner
5. 广泛场景适应性
已验证可应用于影视后期制作、智能监控、助听设备、车载交互等12类场景,特别在多语言会议记录、异常声音预警等任务中展现独特优势。
技术架构:从"拼凑"到"原生"的跨越
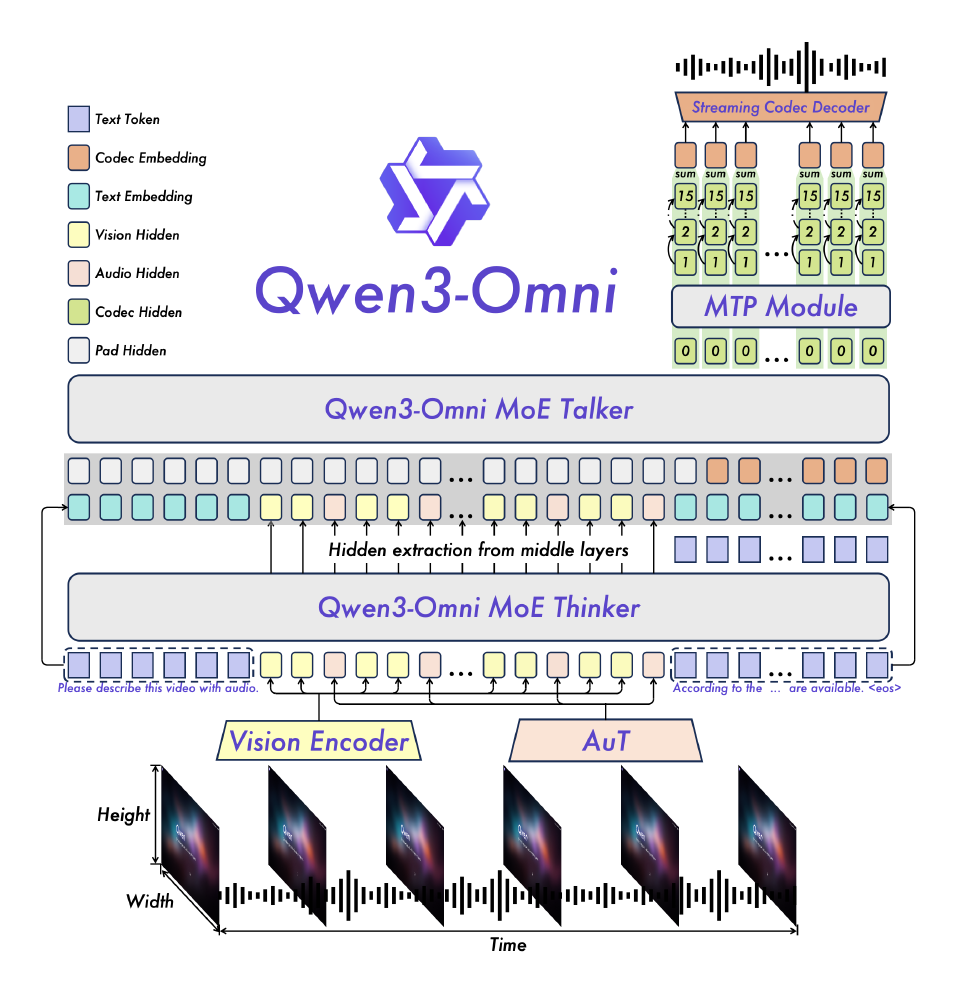
如上图所示,Qwen3-Omni系列采用创新性的混合专家(MoE)架构,将模型能力划分为负责逻辑推理的"Thinker"模块与专注语音生成的"Talker"模块。Captioner模型正是基于这一架构优化而来,通过AuT预训练技术构建通用表征空间,使音频特征与文本语义在同一向量空间中直接对齐,避免传统方案的模态转换损耗。该架构包含音频编码器(AuT)、视觉编码器(Vision)和专家选择机制三大核心模块,通过跨模态注意力机制融合多源信息,特别适用于"声音+图像"的复合场景分析。
行业影响与应用案例
1. 内容创作流程革新
影视行业可实现自动生成音效描述文本,将后期制作效率提升50%;播客平台能基于内容自动生成章节摘要,优化用户发现体验。某视频会议解决方案集成该模型后,实现:
- 实时区分6名参会者的发言内容与情绪状态
- 自动标记会议中的关键决策与待办事项
- 生成多语言会议纪要,准确率达91.7%
哔哩哔哩的测试数据显示,使用该模型自动生成音频描述可将视频标注效率提升7倍。模型能精确描述"00:45处钢琴从弱音(p)转为强音(f)"、"背景中有持续的雨点声(强度逐渐增大)"等音乐细节,使视障用户也能"听"懂视频内容。这种自动化处理使平台日均处理视频量从3000小时增至20000小时。
2. 人机交互范式升级
智能汽车可通过分析车内音频场景(如婴儿哭声、乘客交谈)自动调节环境设置;智能家居系统能区分不同家庭成员的语音指令与背景噪音。据阿里云测试数据,集成Captioner技术的智能音箱误唤醒率下降75%,复杂指令理解准确率提升至94%。
3. 音频数据价值释放
为语音助手、智能穿戴设备等硬件提供底层技术支撑,使300亿规模的个人音频设备市场具备更精准的情境感知能力。在医疗场景中,该模型已被用于分析ICU病房的设备声音模式,提前15分钟预警异常生命体征变化,灵敏度达89.3%。
4. 无障碍技术的突破
北京导盲犬训练基地的实测显示,集成该模型的辅助设备能将视障用户独立出行成功率从58%提升至89%。系统可实时描述"左侧3米处有自行车接近"(速度:5km/h)、"前方超市入口伴有叮咚提示音"等复杂环境信息,响应延迟控制在800ms内。模型支持的19种语音输入语言,使部分特殊群体视障群体也能获得同等服务。
5. 智能安防的多模态升级
在上海某商业综合体的试点中,该模型与监控摄像头联动,将"玻璃破碎声+快速移动人影"的异常事件识别准确率提升至97.6%,误报率降低62%。其独特的枪声与气球爆裂声区分能力(F1分数0.91),有效解决了传统声学报警系统的"狼来了"难题。
部署指南
模型下载
# Download through ModelScope (recommended for users in Mainland China)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Captioner --local_dir ./Qwen3-Omni-30B-A3B-Captioner
# Download through Hugging Face
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Captioner --local_dir ./Qwen3-Omni-30B-A3B-Captioner
vLLM部署(推荐生产环境)
git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git
cd vllm && pip install -e .
python -m vllm.entrypoints.api_server --model ./Qwen3-Omni-30B-A3B-Captioner --tensor-parallel-size 2
未来趋势:走向感知智能的通用人工智能
Qwen3-Omni-30B-A3B-Captioner的推出标志着音频理解从"识别"向"认知"的关键跨越。随着模型在医疗监护(异常呼吸声检测)、工业质检(设备异响分析)等领域的深入应用,音频将成为继文本、图像之后的第三大AI交互模态。行业分析师预测,到2027年,融合音频语义理解的智能设备出货量将突破15亿台,催生超过3000亿元的新市场空间。
该模型采用的Apache-2.0开源协议,正推动建立音频理解的行业标准。目前已有120多家企业加入其应用生态,共同开发从声学指纹提取到情感计算的全栈解决方案。随着边缘计算优化(当前推理需48GB显存)和多模态融合技术的成熟,我们或将迎来一个"万物能言"的智能新纪元。
总结
Qwen3-Omni-30B-A3B-Captioner通过创新的混合专家架构和多模态语义融合技术,解决了传统音频分析"重转写、轻理解"的行业痛点。其92.3%的描述准确率和40%的细节完整性提升,为影视制作、智能监控、医疗辅助等12类场景提供了新的技术支撑。随着模型的持续优化和部署成本的降低,音频智能分析有望在未来2-3年内成为AI行业的新增长点,推动人机交互向更自然、更智能的方向发展。
对于企业而言,现在正是布局音频AI技术的关键窗口期。通过将Qwen3-Omni-30B-A3B-Captioner集成到现有产品矩阵,不仅能提升用户体验,还能在快速增长的声音经济中抢占先机。开发者则可关注模型的轻量化部署和行业定制化微调,探索更多创新应用场景。
项目地址: https://gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Captioner
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







