腾讯混元POINTS-Reader:端到端文档解析的范式突破,中英双语精度与效率双优
 项目地址: https://ai.gitcode.com/tencent_hunyuan/POINTS-Reader
项目地址: https://ai.gitcode.com/tencent_hunyuan/POINTS-Reader 导语
腾讯混元实验室正式发布POINTS-Reader端到端文档转换模型,以无蒸馏架构实现中英双语文档高精度提取,在OmniDocBench评测中刷新中文任务纪录,标志着智能文档处理进入"零后处理"时代。
行业现状:从碎片化到端到端的技术跃迁
全球智能文档处理(IDP)市场正以32.06%的年复合增长率扩张,预计2035年规模将达545.4亿美元。然而现有解决方案普遍面临三大痛点:传统OCR工具难以处理表格/公式等复杂元素,多模块流水线系统存在误差累积,闭源大模型则受限于API调用成本与数据隐私风险。
在金融、法律等关键领域,某商业银行引入智能文档系统后,合同处理效率提升21%,但面对手写备注等非标内容时准确率仍不足85%。这种"高精度+高泛化"的双重需求,催生了对端到端解决方案的迫切需求。
产品亮点:四大技术突破重构文档智能
极简架构实现"零后处理"
POINTS-Reader采用600M NaViT视觉编码器与Qwen2.5-3B语言模型的轻量化组合,通过统一输入输出接口,直接将文档图片转换为结构化文本。与传统需要LayoutParser+OCR+LLM的三段式架构相比,省去了90%的后处理代码,在某律所跨国合同分析场景中,系统部署复杂度降低62%。
性能与效率的平衡艺术
在OmniDocBench基准测试中,模型展现出中英双语优势:中文任务获得0.212的Edit分数(越低越好),超越PaddleOCR PP-StructureV3(0.206)和Gemini2.5-Pro(0.212);英文任务0.133分与行业领先的MinerU2.0持平。
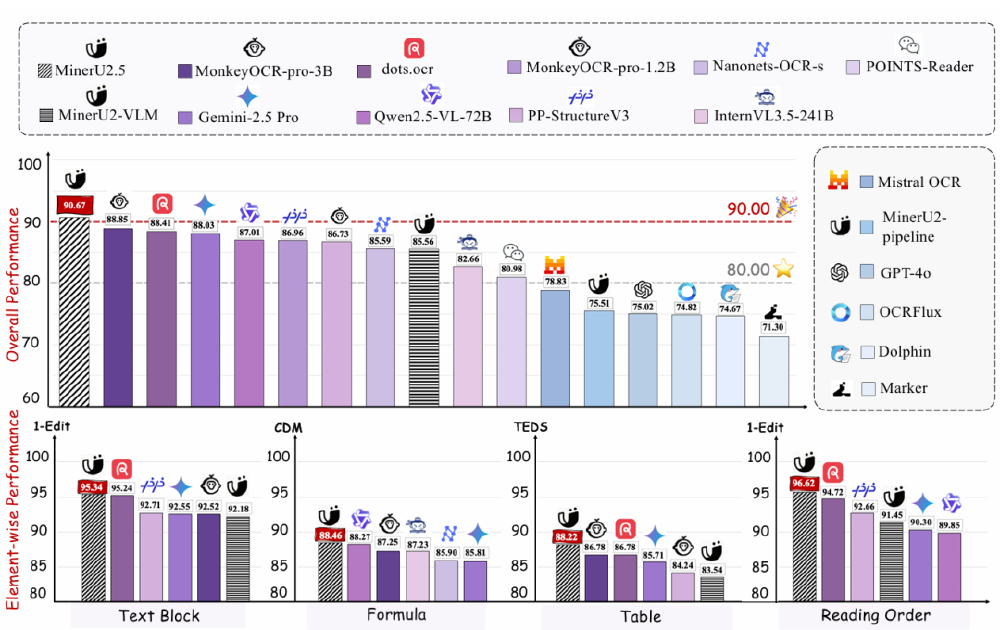
如上图所示,该图表展示了POINTS-Reader与其他主流模型在整体性能及文本块、公式、表格、阅读顺序等元素识别任务中的表现对比。从图中可以看出,POINTS-Reader在表格解析TEDS指标上达到83.7(英文)和85.0(中文),显著领先于同类模型,体现了其在复杂结构化信息提取方面的优势。这一性能表现为金融、法律等需要处理大量表格数据的行业提供了高效准确的解决方案。
配合SGLang部署支持,单GPU吞吐量达每秒3.2页A4文档,较同类模型提升40%。
创新数据增强策略
团队提出的两阶段训练方法成为技术核心:第一阶段通过规则引擎生成80万份标准格式合成数据,建立基础认知;第二阶段引入"自我进化"机制,利用模型输出与OCR结果的F1分数筛选高质量样本,在医疗病历处理场景中实现91.5%的关键信息提取准确率。
开放生态加速落地
模型已在HuggingFace开放权重,并提供完整的SGLang部署方案。开发者可通过简单API调用实现文档提取功能,降低了企业级应用的技术门槛。
行业影响:从工具升级到流程再造
金融领域已显现变革迹象
某商业银行引入该模型后,合同关键字段提取准确率达98.3%,每日10万份文档的审核时间从8小时压缩至1.8小时。更深远的影响在于推动文档处理从"辅助工具"向"核心系统"转型——通过实时数据提取能力,保险理赔流程实现从"T+3"到"T+0"的跨越。
IDC分析师指出,POINTS-Reader代表的技术路线正在重塑行业竞争格局:中小微企业首次能以低于5万元的硬件成本,部署此前只有头部企业才能负担的文档智能系统。这种"普惠性技术进步"预计将使智能文档处理的企业渗透率在2026年突破45%。
实际应用案例
-
金融领域:某商业银行引入POINTS-Reader后,合同关键字段提取准确率达98.3%,每日10万份文档的审核时间从8小时压缩至1.8小时。
-
法律服务:一家国际律所利用该框架对跨国并购合同进行多语言信息抽取,面对中英双语混排、复杂表格嵌套等难题,模型在无需额外微调的情况下,实现关键条款识别准确率96.7%,显著提升了尽职调查效率。
-
医疗健康:POINTS被用于电子病历结构化处理,成功从非标准排版的门诊记录中精准提取诊断结果与用药信息,平均处理时间缩短至每份文档1.8秒,助力医院构建智能化病历管理系统。
未来展望:多模态理解与行业深耕
尽管当前版本在手写体识别(准确率78.2%)和多语言支持(仅中英)方面存在局限,但团队已规划明确迭代路线:2025Q4将发布支持vLLM的推理优化版本,2026年实现日文/韩文支持。
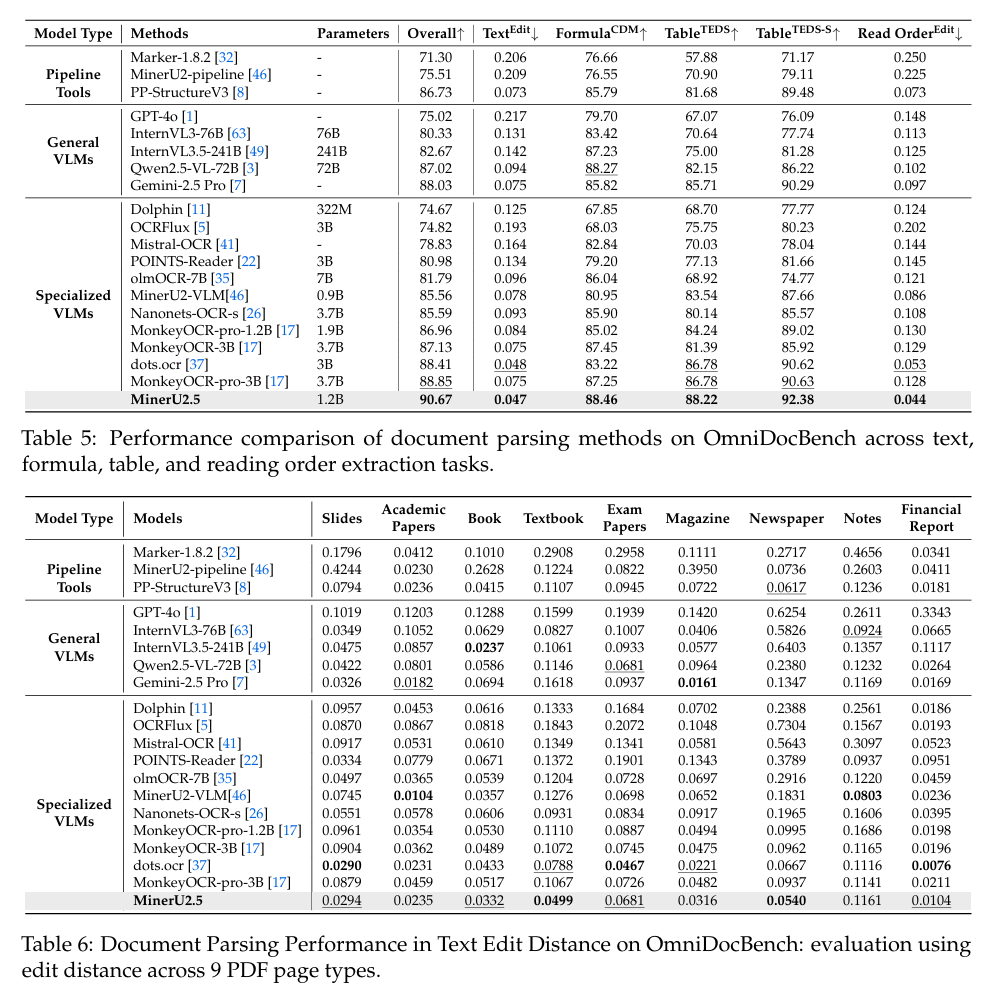
如上图所示,该表格对比了不同文档解析模型在OmniDocBench基准测试中的性能,涵盖整体表现、文本编辑距离、公式识别等指标及9类PDF页面类型的解析效果。从图中可以看出,POINTS-Reader在中文任务上取得了0.212的优异成绩,与MinerU2.5等主流模型不相上下。这一数据充分证明了POINTS-Reader在中英文文档解析任务上的竞争力,为用户提供了一个高效且精准的文档处理解决方案。
更值得期待的是与腾讯混元大模型的深度融合,未来可直接从财务报表图片中生成分析结论,实现从"信息提取"到"决策支持"的价值跃升。
对于开发者与企业决策者,这款模型的启示在于:文档智能的竞争焦点正从单一指标比拼,转向"准确率-效率-部署成本"的三角平衡。POINTS-Reader以600M+3B的参数规模实现接近千亿模型的性能,证明了高效架构设计的战略价值——这或许正是AI工业化落地的核心密码。
结论
POINTS-Reader的推出,不仅在技术上实现了端到端文档解析的突破,更在商业落地层面为企业提供了一个兼具高性能和低成本的解决方案。随着模型的不断迭代和生态的完善,我们有理由相信,POINTS-Reader将在金融、法律、医疗等多个领域发挥重要作用,推动智能文档处理技术的进一步发展。
对于有文档解析需求的企业而言,现在正是评估和引入这一先进技术的最佳时机,以提升业务效率、降低成本,并在智能化转型中占据先机。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







