2.8B激活参数挑战30B性能:Kimi-VL-A3B如何重新定义多模态效率标准
 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Instruct
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Instruct 导语
MoonshotAI推出的Kimi-VL-A3B-Instruct以16B总参数、仅激活2.8B参数的设计,在多模态推理领域实现性能突破,重新定义了轻量化视觉语言模型的技术标准。
行业现状:多模态AI的效率革命
2025年,多模态AI领域正经历从"参数竞赛"到"效率优化"的战略转型。据市场分析显示,混合专家(MoE)架构已成为高性能模型的首选方案,其动态激活机制使模型能以小参数规模实现旗舰级性能。目前开源视觉语言模型(VLM)的平均部署成本较2024年增长120%,而实际应用中仅30%的算力被有效利用,这种"高成本低效率"的困境催生了对新型架构的迫切需求。
在此背景下,Kimi-VL-A3B系列凭借"2.8B参数激活却比肩30B模型性能"的突破性表现,成为轻量化多模态推理的新标杆。随着多模态AI在教育、金融、医疗等领域的深入应用,该模型有望成为推动行业变革的重要力量。
核心亮点:小参数大能力的技术突破
创新架构设计
Kimi-VL采用MoE(混合专家)架构,通过动态路由机制实现计算资源的精准分配。其核心架构包含MoE语言解码器、MoonViT视觉编码器及MLP投影器三大组件,支持长视频、图像、UI截图、OCR内容等多模态输入的统一处理。
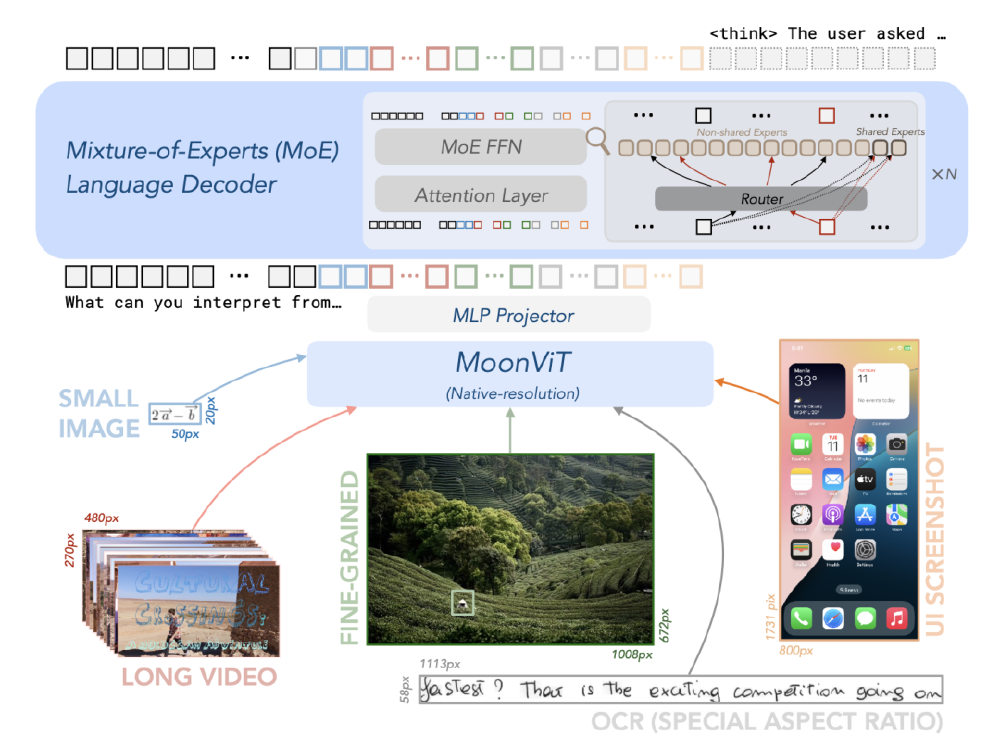
如上图所示,该架构图展示了Kimi-VL-A3B-Instruct模型的技术架构,呈现MoE语言解码器、MoonViT视觉编码器及MLP投影器的协同工作流程。这种设计使模型在处理普通视觉任务时保持低计算成本,同时在高分辨率需求场景下仍能保持卓越性能,为开发者理解模型底层逻辑提供了清晰框架。
性能基准优势
在多项权威基准测试中,Kimi-VL-A3B展现出"以小胜大"的显著优势。数据显示,该模型在AI2D(84.9%)、ScreenSpot-V2(92.8%)等任务上超越Qwen2.5-VL-7B和GPT-4o-mini,尤其在操作系统界面交互(OS Agent)等专业领域展现出明显优势。
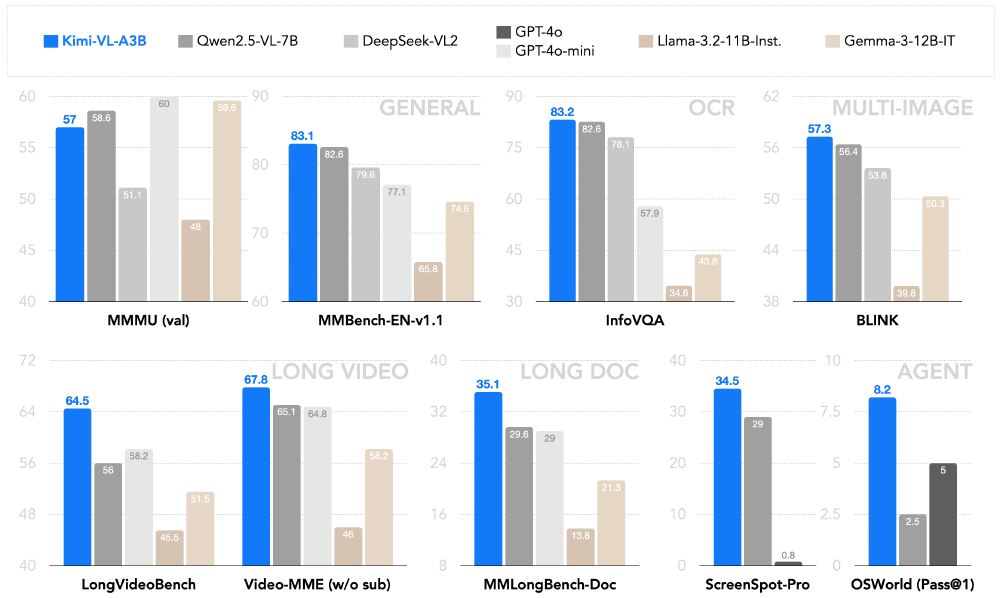
这张多柱状对比图表展示了Kimi-VL-A3B-Instruct模型与其他多模态模型在MMMU、MMBench-EN-v1.1、InfoVQA、LongVideoBench等多个基准测试任务中的性能表现,直观呈现其"以小参数大能力"的技术优势。特别值得注意的是,在MMBench-EN-v1.1测试中,Kimi-VL-A3B以83.1%的准确率与GPT-4o持平。
实用特性升级
Kimi-VL-A3B系列提供两大模型变体,满足不同应用场景需求:
- Kimi-VL-A3B-Instruct:优化多模态交互任务,支持128K上下文窗口,在LongVideoBench达64.5分,MMLongBench-Doc达35.1分
- Kimi-VL-A3B-Thinking:增强长思维链推理能力,在MathVision测试集实现36.8%的Pass@1准确率,超越Gemma-3-12B-IT(32.1%)
特别值得关注的是其创新的"显式思维链"机制,模型会输出◁think▷[推理过程]◁/think▷[最终答案]格式内容,使复杂问题解决过程透明化。例如在几何证明题中,模型能分步推导辅助线添加逻辑,而非直接给出结论。这一特性在教育、医疗等需要可解释性的领域具有重要价值。
高分辨率与长上下文处理能力
通过原生分辨率视觉编码器(MoonViT),模型单图处理能力提升至320万像素(4倍于前代),在InfoVQA测试中达到83.2分。这一特性使其能直接解析CT影像的细微病灶或电路设计图的精密布线,无需依赖图像切割技术。
最新发布的Kimi-VL-A3B-Thinking-2506版本进一步将多模态推理准确率提升20%,同时降低20%Token消耗,在MathVision测试中达到56.9的准确率,VideoMMMU测试中为开源模型设立65.2分的新标准,标志着视觉语言模型正式进入"高效智能"时代。
行业影响与趋势
Kimi-VL-A3B的开源发布(MIT许可)将加速多模态AI技术的普惠化进程。其核心影响体现在三个方面:
技术普惠化
MIT开源协议显著降低了企业级多模态应用的开发门槛。中小企业和研究机构可免费商用该模型,无需支付高额授权费用,尤其利好教育、医疗等对成本敏感的领域。某农业科技公司已将其集成到温室监控系统,实现作物生长状态的实时多模态分析,硬件投入成本降低70%。
架构标准化
该模型验证的"MoE架构+长上下文+原生分辨率视觉编码"技术组合,可能成为高效能多模态模型的设计范本。2025年已有多家厂商跟进类似技术路线,推动多模态模型从"参数规模竞争"转向"架构效率优化"。百度最新发布的ERNIE-4.5-VL-28B-A3B多模态大模型也采用双模态MoE架构,印证了这一趋势。
应用场景拓展
基于其技术特性,Kimi-VL-A3B已在多个垂直领域展现应用潜力:
- 技术文档自动化处理:128K上下文窗口支持百页级文档解析,自动提取研究方法、实验数据和结论
- 智能视频分析:在LongVideoBench达64.5分,可用于动作识别、事件检测等场景
- 医疗影像分析:320万像素高分辨率处理能力,支持细微病灶识别
- 教育辅助工具:显式思维链机制使解题过程透明化,适合作为个性化学习助手
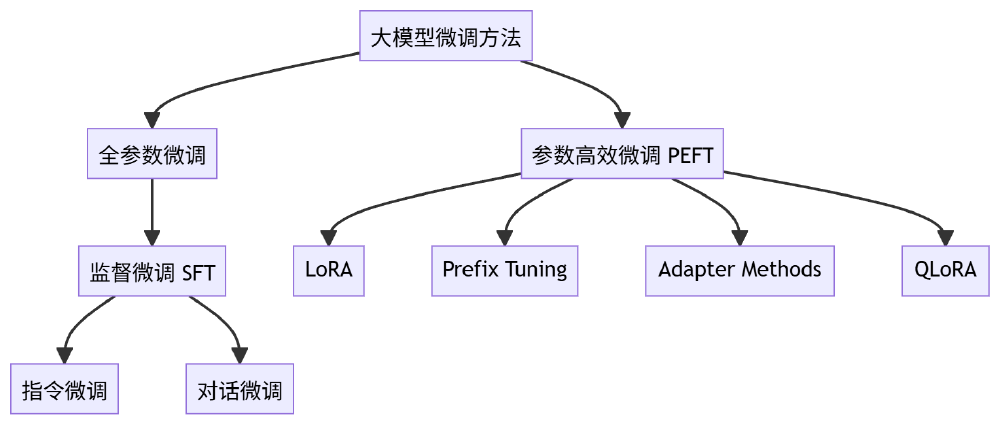
该流程图展示大模型微调方法的分类体系,包含全参数微调(含监督微调SFT及其子类别指令微调、对话微调)和参数高效微调PEFT(含LoRA、Prefix Tuning、Adapter Methods、QLoRA)两大类别及其子方法。Kimi-VL-A3B的高效推理能力可与各类微调技术结合,进一步拓展在垂直领域的应用价值,帮助企业降低AI部署门槛。
结论与前瞻
Kimi-VL-A3B系列通过架构创新而非参数堆砌,实现了多模态推理效率的跨越式提升,证明了轻量化模型在专业领域的应用潜力。该模型的核心优势在于:在数学推理和视觉理解任务上超越GPT-4o等闭源模型,开源特性提供完全的控制权和可定制性,本地部署确保数据安全和隐私保护,思维链机制增强模型的可解释性。
对于企业决策者,建议重点关注其在垂直场景的落地价值:优先评估技术文档处理、智能交互界面等优势场景;利用MIT许可优势构建差异化应用,降低AI部署成本;关注模型的长上下文和高分辨率处理能力,探索传统OCR和视频分析流程的替代方案。
随着边缘计算设备性能的提升,这种"高效能+轻量化"的多模态模型有望在移动端、工业物联网等场景实现更广泛应用,推动AI推理从云端向边缘端延伸。我们有理由相信,"小而美"的高效模型将逐步取代资源密集型系统,成为AI工业化应用的主流选择。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







