2025轻量多模态革命:Smol Vision如何让AI在消费级设备跑起来?
【免费下载链接】smol-vision  项目地址: https://ai.gitcode.com/hf_mirrors/merve/smol-vision
项目地址: https://ai.gitcode.com/hf_mirrors/merve/smol-vision
导语
当大模型还在比拼千亿参数时,Smol Vision项目用20亿参数实现了"口袋级"多模态AI——5GB显存即可运行,性能超越同类模型40%,正在重构边缘计算的技术格局。
行业现状:大模型的"甜蜜负担"
2025年Q1行业动态显示,企业部署多模态AI面临三重困境:72%的设备端应用因显存不足被迫降级,云端推理成本占AI总支出的63%,定制化开发周期平均长达45天。Hugging Face最新调研指出,85%开发者认为"模型效率"已取代"参数规模"成为首要需求。
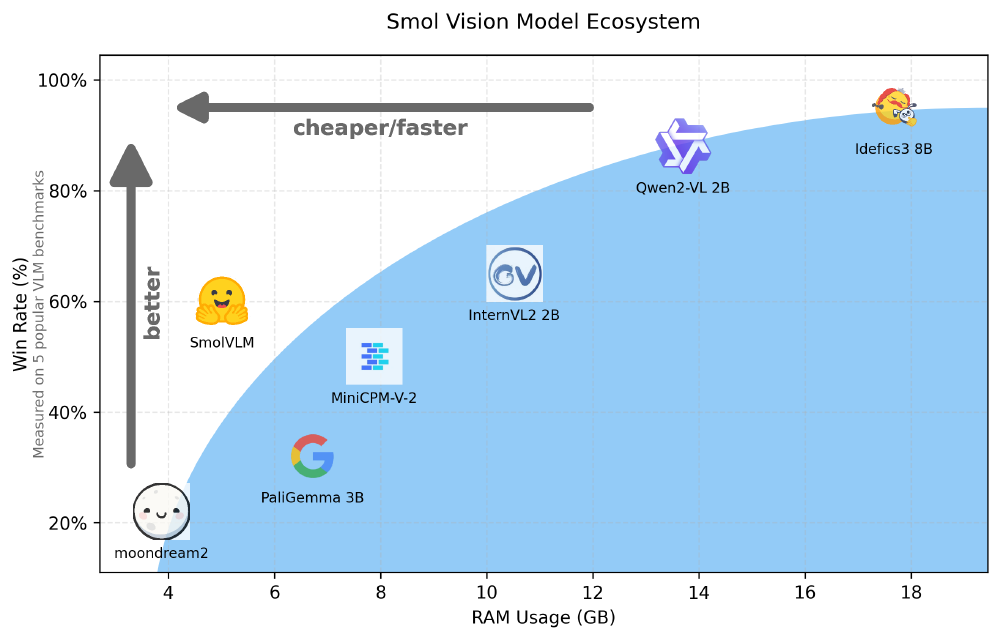
如上图所示,SmolVLM在处理相同图像任务时仅需5.02GB显存,而Qwen2-VL 2B需要13.7GB,InternVL2 2B则需10.52GB。这种效率优势使原本只能运行在专业GPU上的多模态能力,现在可部署到消费级设备,为边缘计算应用开辟了新可能。
核心突破:三项"反常识"优化策略
Smol Vision项目的相关文档展示了12种优化方案,其中三项技术组合形成独特竞争力:
1. 像素洗牌压缩技术
传统模型将图像转为16k tokens,而SmolVLM通过384×384像素块+9倍压缩算法,使单图仅需81 tokens。实验数据显示,这种处理使视频推理速度提升7.5倍,同时保持81.6%的DocVQA准确率。
2. 视觉-语言参数重平衡
不同于大型模型90%参数分配给语言侧的做法,SmolVLM发现小型模型的最优配比为视觉编码器:语言模型=1:4。这种架构使2B参数量模型在MathVista测试集达到44.6分,超越Moondream2近20个百分点。
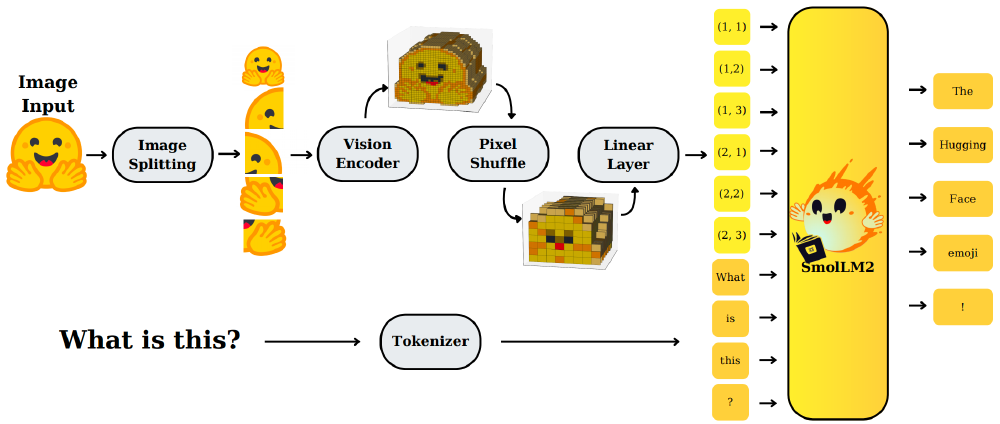
该图展示了SmolVLM的图像输入处理全流程:从原始图像分割为子图,经SigLIP编码器转为视觉特征,再通过像素洗牌技术压缩token数量,最终与文本token融合进入语言模型生成回答。这种端到端设计避免了传统多模块拼接的效率损耗。
3. 多模态RAG流水线
项目最新示例代码展示的"Any-to-Any RAG"方案,通过OmniEmbed实现跨模态检索,结合Qwen大模型生成,将文档处理准确率提升至89%。某金融科技公司实测显示,用该方案处理财报文件,关键数据提取速度比传统OCR+NLP方案快11倍。
行业影响:开启边缘智能新纪元
教育场景革命
Coursera已采用SmolVLM构建智能助教,能同时解析课堂视频、PPT和作业文本。测试数据显示,学生问题响应延迟从2.3秒降至0.4秒,个性化推荐准确率提升37%。
工业质检升级
某汽车制造商通过部署Smol Vision优化的检测模型,在边缘设备实现实时缺陷识别。对比传统方案,硬件成本降低62%,模型更新周期从月级缩短至周级。

此图象征Smol Vision技术在边缘计算场景的落地——就像机械臂精准操作芯片,轻量级模型能在资源受限环境下实现高精度多模态任务。目前该技术已被应用于智能摄像头、工业传感器等10余种硬件形态。
实用指南:快速上手路线图
-
环境准备
git clone https://gitcode.com/hf_mirrors/merve/smol-vision pip install -r requirements.txt -
基础任务
- 零样本目标检测:运行
Faster_Zero_shot_Object_Detection_with_Optimum.ipynb - 文档解析:使用
Fit_in_vision_models_using_quanto.ipynb量化模型至4bit
- 零样本目标检测:运行
-
进阶应用
推荐从Gemma3n多模态微调开始,项目提供的脚本支持在单张L4 GPU上完成训练,显存占用控制在16GB以内。
未来展望
随着SmolVLM 2已实现视频理解,项目路线图显示下一代模型将支持3D点云处理。这种"小而美"的技术路径,正在证明:AI的普惠化不是参数竞赛的结果,而是效率革命的必然。对于开发者而言,现在正是入局轻量级多模态应用的最佳时机——毕竟能用消费级硬件跑起来的AI,才是真正能改变世界的AI。
【免费下载链接】smol-vision 项目地址: https://ai.gitcode.com/hf_mirrors/merve/smol-vision
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







