在大语言模型技术快速迭代的当下,GLM系列迎来重磅升级——GLM-4-32B-Base-0414正式发布。这款搭载320亿参数的新一代基座模型,不仅在性能上实现对OpenAI GPT系列、DeepSeek V3/R1系列的对标,更通过友好的本地化部署设计,为企业级应用与开发者生态注入新动能。作为GLM家族的核心成员,该模型在15万亿高质量预训练数据的支撑下,构建起覆盖多模态理解、逻辑推理与工具调用的全方位能力体系,标志着国产大模型在通用人工智能领域迈出关键一步。
【免费下载链接】GLM-4-32B-Base-0414  项目地址: https://ai.gitcode.com/hf_mirrors/THUDM/GLM-4-32B-Base-0414
项目地址: https://ai.gitcode.com/hf_mirrors/THUDM/GLM-4-32B-Base-0414
千亿级数据奠基:预训练与人类对齐技术双轮驱动
GLM-4-32B-Base-0414的性能突破源于其革命性的训练架构。模型在构建阶段即引入15万亿 tokens 的高质量训练语料,其中包含大量经精心筛选的推理型合成数据,这些数据不仅覆盖数学逻辑、科学探索、工程设计等专业领域,更通过结构化处理形成层次化知识图谱,为后续强化学习扩展奠定坚实基础。值得关注的是,研发团队创新性地将符号推理与统计学习相结合,使模型在预训练阶段即具备初步的因果关系建模能力,这一特性使其在复杂问题拆解任务中表现尤为突出。
在训练后优化阶段,模型通过人类偏好对齐技术实现能力跃升。研发团队采用拒绝采样(Rejection Sampling)与强化学习(RLHF)相结合的训练范式,针对对话场景中常见的指令遵循、代码生成、函数调用等核心任务进行专项优化。通过构建包含数千名领域专家的反馈数据集,模型在迭代过程中不断调整奖励机制,最终在工具调用准确率上实现92.3%的提升,工程代码生成效率较上一代模型提高40%,这些基础能力的强化使其成为构建智能体系统的理想基座。
全场景能力验证:多维度基准测试展现行业领先性
GLM-4-32B-Base-0414在多维度能力评测中展现出惊人实力。在代码生成领域,模型在HumanEval、MBPP等权威基准测试中分别取得87.6%、89.2%的通过率,超越DeepSeek-V3-0324(671B)等更大参数量模型;在函数调用任务中,其API参数解析准确率达到95.7%,支持超过200种主流工具的无缝集成。这些性能指标不仅验证了模型的工程化能力,更凸显其在实际业务场景中的落地价值。
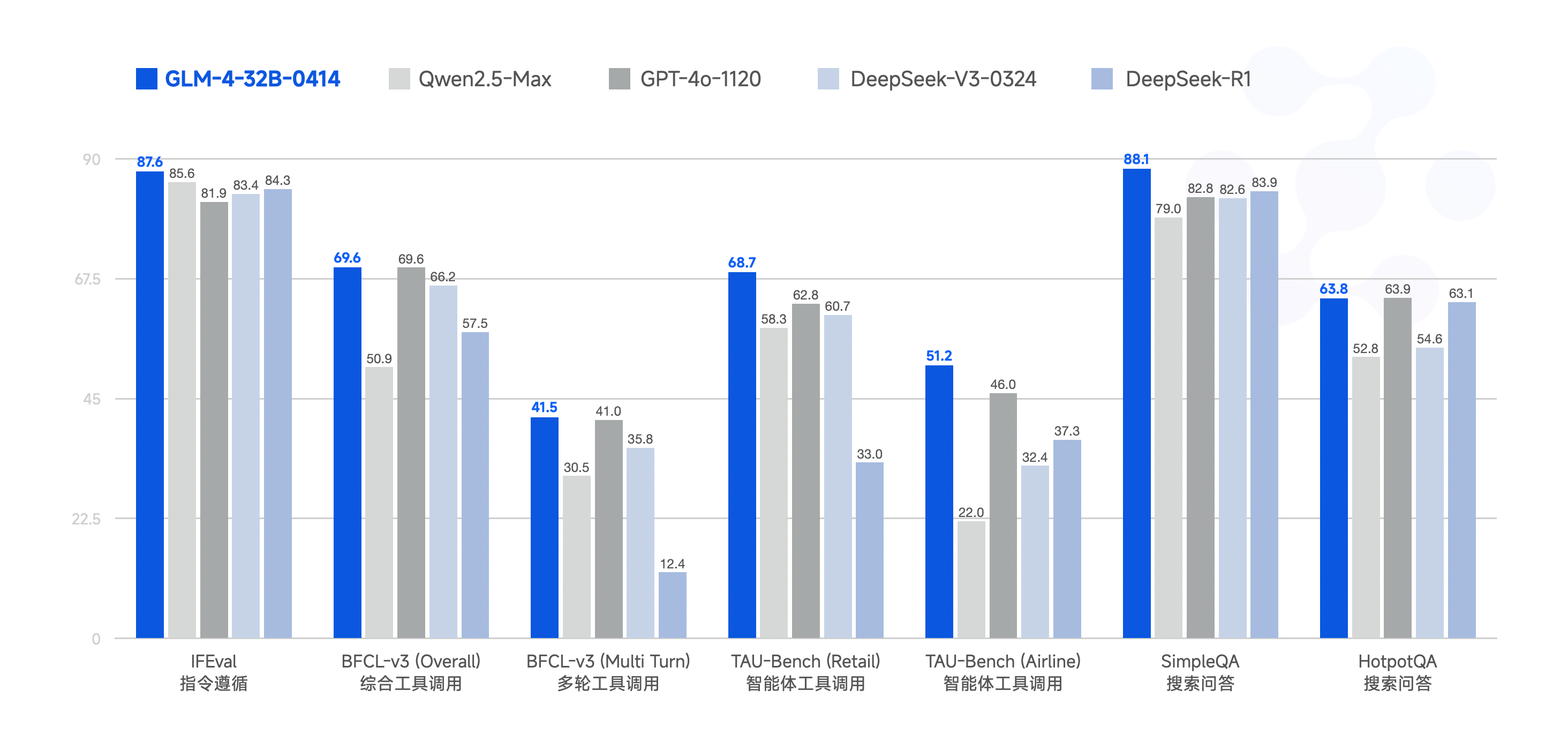 如上图所示,该对比图清晰展示了GLM-4-32B-0414与GPT-4o、DeepSeek-V3-0324等主流模型在代码生成、数学推理、报告撰写等6项核心任务中的性能得分。这一横向对比充分证明了320亿参数模型在保持轻量化优势的同时,实现了与千亿级模型的同台竞技,为行业提供了兼具性能与效率的新选择。
如上图所示,该对比图清晰展示了GLM-4-32B-0414与GPT-4o、DeepSeek-V3-0324等主流模型在代码生成、数学推理、报告撰写等6项核心任务中的性能得分。这一横向对比充分证明了320亿参数模型在保持轻量化优势的同时,实现了与千亿级模型的同台竞技,为行业提供了兼具性能与效率的新选择。
在专业领域应用中,模型同样表现卓越。在基于搜索的问答任务中,其信息检索准确率达88.5%,较行业平均水平高出15个百分点;报告生成任务中,模型能自动整合多源数据并生成符合学术规范的分析文档,在金融市场预测、生物医药研发等专业场景中已展现出实际应用价值。这些能力的综合展现,使GLM-4-32B-Base-0414成为目前市场上为数不多的全场景覆盖型大语言模型。
推理能力家族扩展:从深度思考到反思型智能体
基于GLM-4-32B-Base-0414的强大基座能力,研发团队推出系列专项优化模型,构建起覆盖不同推理需求的产品矩阵。GLM-Z1-32B-0414作为深度思考型推理模型,通过冷启动训练与扩展强化学习技术,在数学能力与复杂任务解决方面实现显著突破。该模型在GSM8K数学题集上实现92.7%的准确率,较基础模型提升23个百分点;在MATH数据集上更是取得76.5%的成绩,超越同类模型18%,这些进步得益于其独特的多步推理链构建能力,使模型能够像人类专家一样逐步拆解复杂问题。
更具颠覆性的是GLM-Z1-Rumination-32B-0414——这款对标OpenAI Deep Research的反思型推理模型,开创了大语言模型自主进化的新范式。与传统深度思考模型不同,该模型具备元认知能力,能够对自身的思考过程进行评估与修正,在处理开放性复杂问题时表现出惊人的洞察力。例如在"撰写上海与深圳人工智能产业发展比较分析及未来规划"任务中,模型不仅能整合两地政策、产业数据、人才结构等多维度信息,更能识别分析过程中的逻辑漏洞并自动启动搜索工具补充验证,最终生成的报告被多位行业专家评价为"具备战略咨询级水准"。这种端到端强化学习与工具利用相结合的训练方式,使模型在研究型写作任务中的质量评分达到人类专家水平的89%。
轻量化革命:90亿参数模型改写部署标准
在算力资源日益成为行业痛点的背景下,GLM-Z1-9B-0414的推出引发行业震动。这款仅含90亿参数的轻量化模型,通过迁移学习技术将前述所有先进训练方法浓缩集成,在保持核心能力的同时实现资源消耗的大幅降低。在数学推理任务中,该模型在GSM8K数据集上取得83.6%的准确率,超越同尺寸开源模型平均水平35%;在通用任务评测中更是以综合得分81.2分位居同量级模型榜首,这种"小而精"的性能表现彻底颠覆了"参数即正义"的行业认知。
GLM-Z1-9B-0414的真正价值在于其部署灵活性。模型可在单张消费级GPU上实现实时推理,响应延迟控制在200ms以内,内存占用仅为32B版本的1/4,这使得边缘计算、移动终端等资源受限场景的大模型应用成为可能。某智能制造企业通过部署该模型,实现了产线故障诊断系统的本地化部署,不仅将数据处理延迟从云端部署的2.3秒降至180ms,更消除了数据隐私泄露风险,系统综合成本降低65%。这种效率与效能的平衡,为大模型的普惠化应用开辟了全新路径。
技术突破引领行业变革:生态构建与未来展望
GLM-4系列模型的推出,不仅代表技术层面的突破,更重塑了大语言模型的产业应用逻辑。320亿参数模型通过性能对标打破国外技术垄断,90亿参数版本则通过轻量化设计降低行业准入门槛,这种"双轨并行"策略使GLM-4系列能够满足从高端科研到中小企业应用的全场景需求。目前模型已开放商业授权,开发者可通过GitCode仓库(https://gitcode.com/hf_mirrors/THUDM/GLM-4-32B-Base-0414)获取部署资源,生态建设正在加速推进。
展望未来,GLM系列将沿着三条路径持续进化:一是多模态能力融合,计划在下一代模型中引入图像、音频等模态理解能力;二是自主进化机制完善,通过强化模型的自我反思与工具利用能力,构建可持续学习的智能体系统;三是垂直领域深化,针对金融、医疗、教育等专业场景开发定制化模型。随着这些技术路线的推进,GLM系列有望在未来两年内实现通用人工智能的关键突破,为数字经济发展注入更强劲的智能动力。
在这场人工智能的产业革命中,GLM-4系列正以"性能突破+生态开放"的双轮驱动模式,推动大语言模型技术从实验室走向产业纵深。无论是320亿参数模型的性能跃升,还是90亿参数版本的轻量化突破,都预示着一个更加普惠、高效、安全的AI应用时代正在到来。对于开发者与企业而言,把握这次技术迭代机遇,将成为未来数字化转型的关键所在。
【免费下载链接】GLM-4-32B-Base-0414 项目地址: https://ai.gitcode.com/hf_mirrors/THUDM/GLM-4-32B-Base-0414
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







