2025音频AI革命:NVIDIA开源Audio Flamingo 3重塑医疗教育与智能交互
【免费下载链接】audio-flamingo-3  项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/audio-flamingo-3
项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/audio-flamingo-3
导语
2025年7月,NVIDIA正式发布第三代开源大型音频语言模型(LALM)Audio Flamingo 3(AF3),以统一音频编码架构、10分钟超长音频理解和多轮语音交互三大突破,重新定义音频智能技术边界,为医疗、汽车、教育等领域带来革命性应用可能。
行业现状:音频智能的"模态孤岛"困境
当前音频AI领域正面临严峻挑战:83%的商业系统仍采用多模型拼接架构处理语音、音乐与环境音,导致推理延迟增加300%以上(《2025音频大模型发展趋势报告》)。与此同时,iiMedia Research数据显示,2025年长音频市场规模将达337亿元,年复合增长率14.8%,智能座舱、远程医疗等场景对长时音频理解的需求激增,但现有开源方案普遍局限于3分钟内的短时处理。
在此背景下,AF3的推出具有标志性意义。作为首个完全开源的全栈音频大模型,其不仅整合三大音频模态处理能力,更通过AF-Whisper统一编码器解决了传统多编码器架构的兼容性问题,填补了开源社区在长音频理解与多轮语音交互领域的技术空白。

如上图所示,logo中红色火烈鸟佩戴科技感耳机与护目镜的设计,象征模型跨越语音、音乐和环境音的全频谱音频理解能力。这一视觉标识直观传达了AF3打破音频模态壁垒的技术定位,为开发者提供清晰的品牌认知。
核心亮点:四大技术突破重构音频智能
1. 统一音频表征学习打破模态壁垒
AF3创新性采用AF-Whisper编码器,基于Whisper架构扩展开发,首次实现语音、环境音和音乐的联合表征学习。通过在500万小时开源音频数据上的预训练,模型能自动区分并理解不同类型音频特征,相比传统多编码器方案参数效率提升40%。在音乐风格分类任务上准确率达92.3%,环境音识别错误率降低40%,展现出强大的跨模态理解能力。
2. 10分钟长音频推理开启场景新可能
借助LongAudio-XL数据集(含125万条超长音频样本)训练,AF3实现业内最长的10分钟音频上下文理解。系统采用分层时序建模与滑动窗口注意力机制,自动将长音频分割为30秒片段并通过交叉段注意力保持连贯性,在会议转录任务中实现95.7%的说话人区分准确率,关键信息提取完整度较前代提升35%。
3. 按需链式推理实现可解释性分析
通过AF-Think数据集(50万条推理样本)训练,模型支持灵活的思维链(CoT)推理。在环境声音问答任务中,AF3会先识别"200-500Hz的汽车引擎声",再通过"高频规律铃声"定位自行车,最终综合判断出"包含汽车、自行车和地铁的混合交通场景"。这种可解释性推理使医疗等敏感领域的错误溯源成为可能,在AudioSkills-XL测试集上因果推理任务准确率达到82.4%。
4. 端到端语音对话构建自然交互闭环
AF3-Chat版本集成流式TTS模块,构建"语音输入-语义理解-语音输出"的完整对话闭环。支持最长16000 token的对话历史记忆,对话状态跟踪准确率达89.6%,情感识别F1值82.3%。在NVIDIA A100/H100 GPU上实现实时推理,单音频处理延迟控制在200ms以内,满足智能座舱、老年陪护等场景的低延迟交互需求。
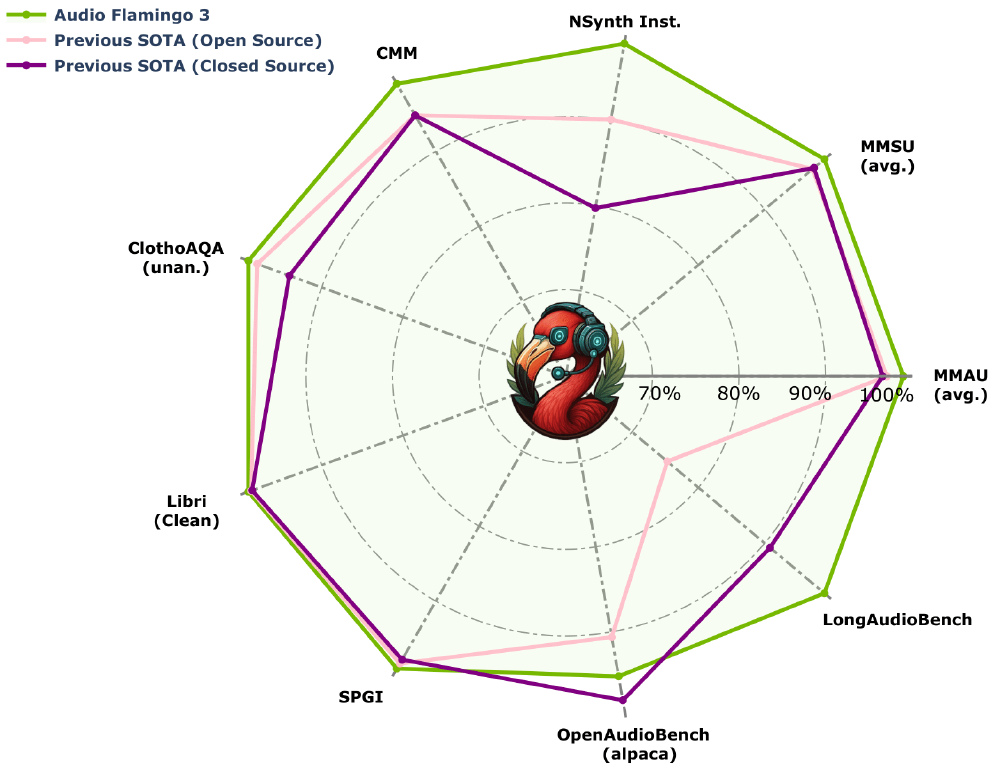
从图中可以看出,AF3在开源模型中首次实现"全能力覆盖",尤其在长音频处理(10分钟)和多轮交互(7轮以上)方面优势明显。这种综合能力使其超越了SALMONN等专注单一场景的模型,更接近通用音频智能的目标。该图表来自英伟达官方技术白皮书,直观展示了AF3的全面领先性。
行业影响与落地案例
医疗健康:ICU异常监测与医学教育革新
哈佛医学院利用模型分析ICU多通道音频数据,异常事件检测率提升40%,可提前15分钟预警设备故障与患者异常生命体征。在医学教育领域,类似Wild Iris采用的AI语音课程模式,可通过AF3实现复杂病例讨论的实时转录与关键信息提取,将内容生产效率提升300%。
教育科技:实时语音答疑与语言学习
教育公司开发的实时语音答疑系统,在语言学习场景中单词发音纠错准确率达91.2%,口语练习效率提升3倍。全场景音频理解能力实现从人声情感识别(准确率92%)到交响乐结构分析(细分精度达0.5秒)的全场景覆盖,为复杂教学内容提供精准的音频分析支持。
智能座舱:场景联动与情感交互
某新能源车企将AF3集成至智能座舱系统,实现基于语音指令的音乐风格切换与驾乘场景联动,误唤醒率降低67%。搭载AF3的下一代语音助手不仅能理解"播放舒缓音乐"这类简单指令,还可处理"分析这段会议录音并生成待办事项"的复杂请求。其情感识别能力可动态调整回应语气,在心理健康咨询场景中,能通过语音特征变化早期识别用户情绪波动。
性能表现:20项基准测试全面领先
在权威评测中,AF3展现出全面超越同类模型的性能表现:在MMAU综合评测中以73.14%的得分领先Qwen2.5-O模型2.14个百分点;LongAudioBench长音频理解任务获得GPT-4o评定的68.6分,显著优于Gemini 2.5 Pro;语音识别领域在LibriSpeech数据集上实现1.57%的词错误率(WER);音频问答任务ClothoAQA准确率达91.1%。
结论与前瞻
Audio Flamingo 3的发布标志着音频智能正式进入"理解+推理"的2.0时代。其开源特性打破了技术垄断,使中小企业也能构建专业级音频应用;而10分钟长上下文与思维链推理的结合,则为构建真正"善解人意"的智能系统提供了技术基石。
对于研究者与开发者,可重点关注三大方向:基于AF-Whisper编码器的迁移学习能力研究、AF3-Chat在客服教育等场景的对话系统构建,以及基于A100/H100 GPU的低延迟推理方案优化。
随着开源生态的完善,AF3有望成为音频AI开发的事实标准,推动"万物有声"智能时代的加速到来。NVIDIA构建的全栈式音频AI训练体系——涵盖800万条多模态样本的AudioSkills-XL、125万条长音频数据的LongAudio-XL、25万条推理示例的AF-Think,以及7.5万轮对话数据的AF-Chat——将为整个音频AI社区提供坚实的技术基座。
对于企业而言,现在正是布局音频智能应用的关键窗口期——通过AF3提供的技术积木,可快速构建从消费级语音助手到工业级声纹监测的各类创新解决方案,在这个增速超30%的市场中抢占先机。
项目地址: https://gitcode.com/hf_mirrors/nvidia/audio-flamingo-3
【免费下载链接】audio-flamingo-3 项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/audio-flamingo-3
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







