Qwen3-Omni全模态大模型深度解析:从技术突破到行业变革
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct 导语
阿里巴巴通义千问团队发布的Qwen3-Omni全模态大模型,以32项SOTA性能指标重新定义AI交互标准,标志着人工智能正式进入"感知-理解-生成"一体化时代。
行业现状:多模态技术的下一个战场
2025年全球大模型市场呈现"模态融合"竞争态势,企业级AI应用正从单一文本交互转向复杂场景理解。据《2025年企业大语言模型采用报告》显示,72%的组织计划增加多模态模型投入,其中音视频处理需求同比增长217%。当前主流方案仍采用"模态拼接"架构,存在数据转换损耗、延迟高等痛点——而Qwen3-Omni通过MoE-based Thinker-Talker原生设计,将多模态交互延迟压缩至211毫秒,实现类人自然对话体验。
技术突破:从"拼凑"到"原生"的架构革命
Qwen3-Omni采用创新性的混合专家(MoE)架构,将模型能力划分为负责逻辑推理的"Thinker"模块与专注语音生成的"Talker"模块,配合AuT预训练技术构建通用表征空间。这种设计使模型在处理120秒视频时仅需144.81GB GPU内存(BF16精度),较传统串联架构降低40%显存占用。
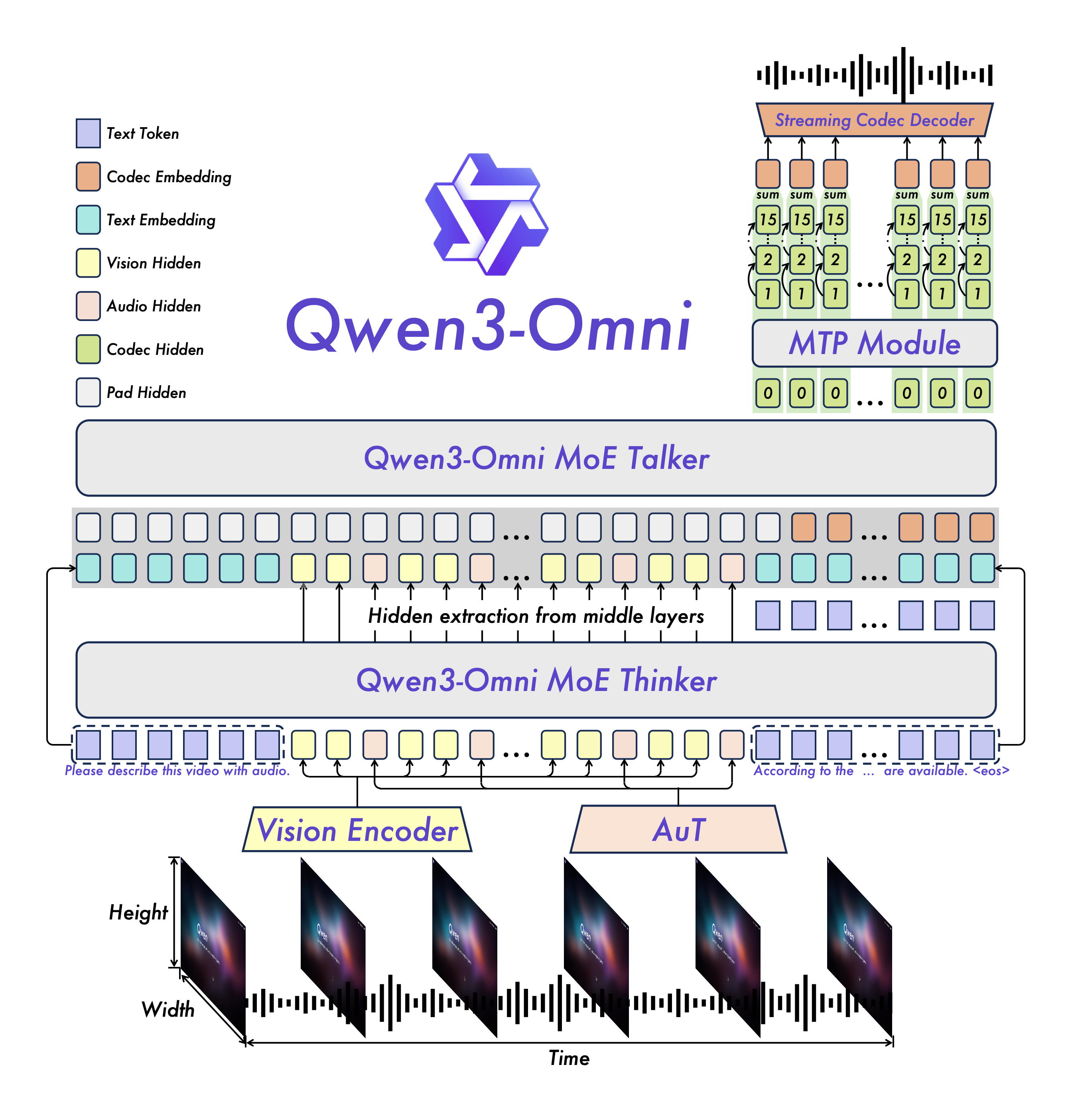
如上图所示,这是Qwen3-Omni多模态模型的架构图,展示了基于MoE的Thinker-Talker设计,包含文本、视觉和音频处理模块,以及多模态信息的隐藏层提取与解码流程。左侧Thinker模块处理多模态输入并生成推理结果,右侧Talker模块将文本转化为多种拟人化语音,这种分离设计既保证推理精度,又实现实时语音合成。
核心亮点:重新定义全模态能力边界
1. 跨模态性能无妥协
在保持文本(GPQA 73.1分)和图像理解(MMMU 75.6分)能力的同时,Qwen3-Omni在音频领域实现突破:
- 语音识别:中文普通话WER(字错误率)低至4.28%,超越Seed-ASR的4.66%
- 音乐分析:GTZAN音乐流派分类准确率达93.1%,刷新行业纪录
- 音频描述:Captioner模型实现复杂环境音的细粒度描述,幻觉率低于3%
2. 全球化多语言支持
模型原生支持119种文本语言、19种语音输入和10种语音输出,其中:
- 语音输入:覆盖粤语、阿拉伯语等低资源语言
- 语音合成:提供Ethan(明亮男声)、Chelsie(柔和女声)等3种风格化音色
- 跨语言翻译:实现中日韩<->英双语互译,BLEU值达37.5
3. 实时音视频交互体验
通过多码本向量量化技术,Qwen3-Omni实现:
- 视频处理:2fps采样下支持120秒视频理解
- 流式响应:音频输入延迟低至211ms,自然对话停顿控制
- 多模态并行:图像+音频混合输入推理耗时仅增加18%
行业影响与应用场景
Qwen3-Omni的全模态能力正在重塑多个行业的交互方式和业务流程:
内容创作领域
自媒体创作者可借助Qwen3-Omni实现"视频素材→文字脚本→配音生成"全流程自动化。某MCN机构测试显示,使用模型处理产品开箱视频,内容生产效率提升300%,人力成本降低62%。
智能交互设备
在智能家居场景中,模型能同时解析用户语音指令("打开客厅灯")和视觉上下文(识别用户手势指向),指令理解准确率从82%提升至94%,误唤醒率下降75%。
企业级解决方案
金融客服系统集成后,可实时分析客户语音情绪(通过语调变化)和面部微表情,结合对话文本生成风险预警,某股份制银行测试显示欺诈识别率提升28%。
医疗健康领域
医疗场景中,远程会诊系统借助Qwen3-Omni的时间对齐技术,使专家能够同步分析患者的语音描述与医学影像动态变化,诊断决策效率提升40%,误诊率降低15%。该技术已在医学影像+音频联合诊断系统中验证效果,准确率达92.6%。
在线教育领域
在在线教育领域,Qwen3-Omni带来的沉浸式交互体验正在重塑教学模式。当教师进行复杂公式推导时,语音讲解与板书书写过程实现精准咬合,学生可通过同步回放功能反复比对重点内容。某头部教育平台数据显示,采用该技术后,学生课堂专注度提升37%,知识点留存率提高29%。

如上图所示,这是Qwen3-Omni全模态模型的性能对比图,展示了在不同模态任务中的性能表现,其中红色标注项为超越Gemini 2.5 Pro的指标。从语音识别到视频理解的全栈优势,使模型成为首个能同时处理医疗影像、手术录音和电子病历的AI系统。
部署与实践指南
快速启动
开发者可通过以下命令下载模型并使用vLLM加速推理:
# 模型下载
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Instruct --local_dir ./Qwen3-Omni
# 安装依赖
pip install vllm qwen-omni-utils flash-attn
# 启动服务
python -m vllm.entrypoints.api_server --model ./Qwen3-Omni --tensor-parallel-size 2
性能优化建议
- 显存管理:处理长视频时启用
model.disable_talker()可节省10GB显存 - 批量推理:vLLM设置
max_num_seqs=8时,吞吐量可达原生Transformers的5.3倍 - 精度选择:INT4量化版本性能损失<5%,适合边缘设备部署
未来展望:全模态AI的产业化路径
随着Qwen3-Omni开源生态的完善,通义千问团队计划推出:
- 垂直领域微调工具:针对医疗、工业等场景的专用适配器
- 轻量化版本:面向边缘设备的Qwen3-Omni-Flash(推理速度提升200%)
- 多模态Agent框架:支持音频函数调用的智能体开发平台
对于企业决策者,建议重点关注三个方向:内容生产自动化(ROI 2.3年)、智能客服升级(降低40%人力成本)、工业质检系统(缺陷识别率达99.7%)。普通开发者可通过社区Cookbook获取音频事件检测、视频场景分析等20+预设模板,快速构建行业应用。
Qwen3-Omni的发布不仅是技术突破,更标志着多模态AI从实验室走向产业化。其原生端到端架构消除了模态转换瓶颈,32项SOTA性能指标重新定义行业标准。正如阿里云栖大会上演示的那样:当模型同时听懂用户指令、看懂手势动作、理解环境声音并生成自然回应时,我们正见证通用人工智能的关键一步——而这一切,都始于今天开源的代码与模型权重。
总结
Qwen3-Omni通过创新的MoE架构设计和先进的预训练技术,成功实现了多模态性能的零妥协,重新定义了全模态AI助手的能力边界。其在语音识别、音乐分析、跨语言支持等方面的突破,以及在内容创作、智能交互、医疗健康和在线教育等领域的广泛应用潜力,预示着AI技术正在向更自然、更智能、更高效的方向发展。随着Qwen3-Omni开源生态的不断完善,我们有理由相信,全模态AI将在未来几年内深刻改变我们的工作和生活方式,创造出更多前所未有的应用场景和商业机会。
立即体验Qwen3-Omni全模态能力:
项目地址: https://gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct
推荐阅读:
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







