腾讯混元图像3.0开源:800亿参数重构AIGC创作生态
【免费下载链接】HunyuanImage-3.0  项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanImage-3.0
项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanImage-3.0
导语
2025年9月28日,腾讯正式开源混元图像3.0(HunyuanImage 3.0),这款参数规模达800亿的原生多模态模型不仅刷新了开源领域的技术纪录,更在上线一周后登顶国际权威榜单LMArena,成为首个在该领域实现"双榜首"的国产大模型。
行业现状:多模态技术进入"推理革命"新阶段
文生图技术正经历从"能生成"向"能理解、能推理、能控制"的关键转型。2025年第二季度全球文生图API调用量突破120亿次,商业模型虽占据72%市场份额,但开源模型的技术追赶速度显著加快。国际权威评测机构数据显示,多模态与Agent应用已取代纯语言模型成为AI领域新增长极,其中文生图技术的突破集中体现在三大方向:参数量级提升(从百亿到千亿)、架构创新(统一自回归框架)、推理能力强化(思维链技术应用)。
混元图像3.0的推出恰逢这一技术迭代窗口期。作为首个开源工业级原生多模态生图模型,其800亿参数规模与MoE(混合专家)架构,直接挑战了闭源模型在高端市场的技术垄断。更值得关注的是,该模型在LiblibAI平台上线仅8天,已助力平台上的千万创作者生成超过300万张专业级图像,印证了开源技术对创意产业的快速赋能效应。
核心亮点:四大技术突破重新定义生成范式
1. 统一自回归多模态架构
不同于传统DiT架构需要独立的编码器-解码器系统,混元图像3.0采用创新的原生多模态设计,在单一框架内实现文本理解与图像生成的深度融合。其800亿参数的MoE结构包含64个专家层,每个token激活130亿参数进行推理,既保证了模型容量又控制了计算成本。这种"看懂即能画"的能力,使模型在处理复杂指令时表现出更自然的逻辑连贯性。
2. 工业级生成质量与精度
通过五阶段训练策略(预训练→SFT→DPO→MixGRPO→SRPO),模型实现了语义准确性与视觉美感的平衡。在SSAE(结构化语义对齐评估)中,其平均图像准确率超过行业基准12.3%,尤其在"文本渲染"和"复杂场景重建"两个细分维度得分领先。实际测试显示,该模型能精准生成3D文字效果,支持16种材质渲染(如sisal、亚麻绳、竹编等),甚至能复现梵高《星空》的旋转星云纹理。
3. 智能世界知识推理能力
基于Hunyuan-A13B大语言模型底座,该模型具备常识推理与多步骤任务分解能力。在"曹冲称象九宫格漫画"测试中,不仅能准确还原历史典故的九个关键场景,还能自动添加符合情节的文字说明。更令人印象深刻的是,其数学推理能力使模型能通过文本生成步骤解析二元一次方程组,展现出跨模态逻辑迁移能力。这种"会思考的画笔"特性,极大拓展了AI在教育、设计等领域的应用边界。
4. 灵活高效的部署方案
尽管模型规模达800亿参数,但通过FlashAttention和FlashInfer优化,在4×80GB GPU配置下可实现每张图像20秒内生成。支持自动分辨率预测与指定分辨率两种模式,能根据文本内容智能推荐1280x768等最优尺寸,同时兼容从512x512到2048x2048的全尺寸输出。这种高性能与灵活性的平衡,使企业级应用部署成为可能。
技术架构解析
混元图像3.0的核心创新在于将混合专家模型(MoE)与Transfusion方法相结合:
graph TB
A[输入文本] --> B[LLM编码器]
B --> C[MoE专家路由]
C --> D[图像理解模块]
C --> E[图像生成模块]
D --> F[多模态融合]
E --> F
F --> G[输出图像]
模型采用渐进式训练策略:
- 预训练阶段:低分辨率→高分辨率,低质量→高质量
- 指令微调:构造思维链生图数据,激发推理能力
- 监督微调:使用高质量、高美感数据
- 强化学习:结合DPO、GRPO算法提升美学效果
效果展示与案例分析
世界知识推理案例
提示词:"生成一副九宫格教程,展现如何素描画一只鹦鹉"
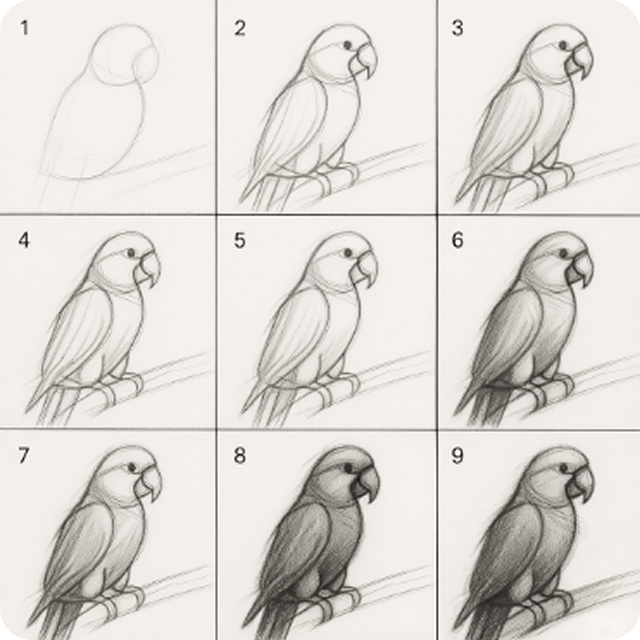
如上图所示,这是HunyuanImage-3.0生成的九宫格素描鹦鹉教程,从基础几何形状到完成素描的全过程清晰展示。这一案例充分体现了模型的世界知识推理能力,能够将复杂的绘画步骤分解为易于理解的教学内容,为教育工作者和学习者提供了高质量的视觉教学资源。
极致美学案例
提示词:"这是一幅极具视觉张力的杂志风海报,整体笼罩在暗黑幽灵般的神秘氛围中,背景采用简约高级的纯红色..."
模型生成的图像在光影对比、色彩处理和构图上达到专业设计水准,充分展示了其在美学表达上的卓越能力。
精确文字生成案例
提示词:"大师级排版 + 极繁主义,融入半调纹理、杂色颗粒与暖系同位色渐变..."
模型准确生成包含复杂文字排版的图像,文字清晰度与设计感媲美专业平面设计软件,展现了其在文字渲染方面的突出优势。
国际权威评测成绩
混元图像3.0在国际权威榜单LMArena登顶综合与开源双榜首,成为首个在该领域实现"双榜首"的国产大模型。

如上图所示,这张带有"HunyuanImage 3.0登顶 LMArena文生图第一"文字的科技感几何空间背景图,展示了腾讯混元图像3.0在AI文生图领域的领先成就。这一成绩标志着中国AI在多模态生成领域已进入全球第一梯队。
性能评测对比
在SSAE(结构化语义对齐评估)中,HunyuanImage-3.0表现优异:
| 模型 | Mean Image Accuracy | Global Accuracy |
|---|---|---|
| HunyuanImage-3.0 | 85.2% | 87.4% |
| DALL-E 3 | 82.1% | 84.6% |
| Midjourney v6 | 81.8% | 83.9% |
| Stable Diffusion 3 | 78.5% | 80.2% |
GSB人工评测中,由100+专业评估师对1000个提示词生成的图像进行评估:
| 对比模型 | Good | Same | Bad |
|---|---|---|---|
| vs DALL-E 3 | 52% | 31% | 17% |
| vs Midjourney v6 | 48% | 35% | 17% |
| vs Flux.1 | 61% | 28% | 11% |
核心技术优势
混元图像3.0的四大核心技术优势包括世界知识推理能力、语义理解与美学质感、复杂文本解析能力和业界领先的生成效果。

如上图所示,这张图片系统总结了混元图像3.0的四大核心技术优势。这一技术组合充分体现了原生多模态架构的独特优势,为开发者和企业用户提供了从简单生成到智能创作的完整解决方案。
快速开始使用
环境准备
# 1. 安装PyTorch (CUDA 12.8版本)
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128
# 2. 安装其他依赖
pip install -r requirements.txt
# 3. 性能优化组件(可选,提升3倍推理速度)
pip install flash-attn==2.8.3 --no-build-isolation
pip install flashinfer-python
模型下载
# 从GitCode下载模型
git clone https://gitcode.com/hf_mirrors/tencent/HunyuanImage-3.0.git
cd HunyuanImage-3.0
Python代码示例
from transformers import AutoModelForCausalLM
# 加载模型
model_id = "./HunyuanImage-3"
kwargs = dict(
attn_implementation="sdpa", # 使用"flash_attention_2"如果已安装
trust_remote_code=True,
torch_dtype="auto",
device_map="auto",
moe_impl="eager", # 使用"flashinfer"如果已安装
)
model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
model.load_tokenizer(model_id)
# 生成图像
prompt = "一只棕白相间的狗在草地上奔跑"
image = model.generate_image(prompt=prompt, stream=True)
image.save("image.png")
行业影响与趋势
混元图像3.0的开源将加速文生图技术普及进程。GitHub数据显示,该项目上线一周星标数突破1.7k,社区已衍生出12种语言的本地化版本。其技术路线证明,通过MoE架构可在控制计算资源的前提下实现性能突破,为中小团队提供了低成本接入高端生成能力的可能。
商业应用场景正快速拓展:
- 电商领域:生成的"柠檬水海报"已达到商业广告级质量,包含产品质感与促销信息
- 教育领域:"素描教学九宫格"能自动分解绘画步骤
- 传统文化传播:"十二生肖月饼"案例展示了AI对非遗元素的创造性转化
腾讯官方透露,图生图、图像编辑等功能将在后续版本开放,进一步丰富应用场景。
结论与前瞻
混元图像3.0的推出标志着国产大模型在多模态领域进入全球第一梯队。其技术突破验证了"统一架构+开源生态"的发展路径,为行业提供了从"单点生成"到"智能创作"的完整解决方案。随着后续Instruct版本(支持多轮交互)的发布,预计将在内容创作、工业设计、教育培训等领域催生更多创新应用。
对于开发者,建议优先关注模型的Prompt工程指南,特别是"主体-环境-风格-参数"四要素描述框架;企业用户可重点评估其在广告素材批量生成和个性化内容推荐场景的落地价值。随着开源社区的壮大,这个兼具"工业级精度"与"学术前瞻性"的模型,有望成为多模态研究的新基准。
相关资源
- 官方网站:https://hunyuan.tencent.com/image
- GitCode仓库:https://gitcode.com/hf_mirrors/tencent/HunyuanImage-3.0
- 技术报告:HunyuanImage 3.0 Technical Report
- 提示词手册:https://docs.qq.com/doc/DUVVadmhCdG9qRXBU
欢迎点赞、收藏、关注,获取混元图像3.0的最新技术动态和应用案例!
下期预告:12月将推出模型量化部署专题,敬请关注官方公告。
【免费下载链接】HunyuanImage-3.0 项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanImage-3.0
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







