85%数学竞赛正确率+100万token上下文:Qwen3-30B推理模型颠覆行业认知
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Thinking-2507
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Thinking-2507 导语
阿里通义千问团队发布Qwen3-30B-A3B-Thinking-2507,这款305亿参数的混合专家模型在数学推理、超长文本处理和代码生成三大核心能力上实现突破,重新定义了中等规模大语言模型的性能边界。
行业现状:推理能力成大模型竞争新焦点
2025年中AI市场报告显示,大语言模型正从"通用能力竞赛"转向"专项能力深化"。据《大模型推理技术发展白皮书》统计,推理型模型在企业级应用中的渗透率已从2024年Q1的18%飙升至2025年Q2的47%,尤其在金融分析、科学研究和复杂决策支持场景需求激增。
当前行业面临双重挑战:一方面,传统稠密模型参数量突破千亿后边际效益递减,训练成本呈指数级增长;另一方面,实际应用中85%的复杂任务需要深度推理能力,而非简单信息检索。Qwen3-30B-A3B-Thinking-2507的推出,正是通过MoE架构和定向优化,在30B参数级别实现了推理性能的跨越式提升。
模型亮点:三大技术突破重新定义推理范式
1. 混合专家架构实现效率与性能平衡
Qwen3-30B-A3B-Thinking-2507采用128个专家模块的MoE结构,每次推理仅激活8个专家(约3.3B参数),这种设计使计算效率提升16倍的同时,保持了305亿总参数的模型容量。其分组查询注意力(GQA)机制——32个查询头与4个键值头的配置,在256K上下文场景下比标准多头注意力减少40%显存占用。
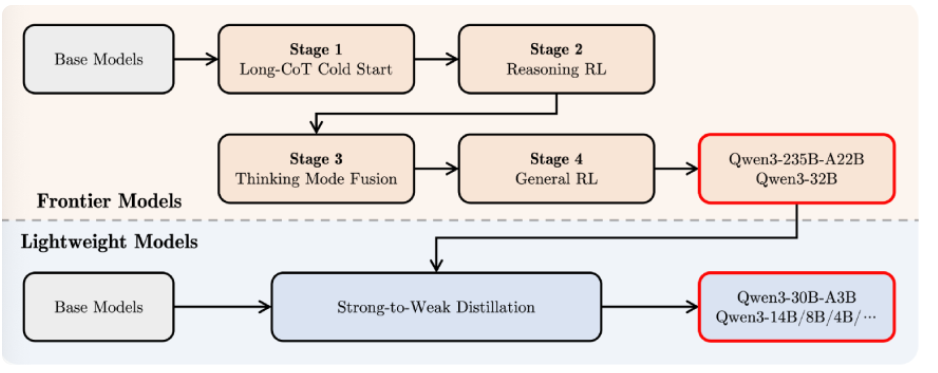
如上图所示,该架构图展示了Qwen3系列模型的训练流程与专家选择机制,包括前沿的多阶段训练(Long-CoT Cold Start、Reasoning RL等)及轻量级模型的"强到弱蒸馏"过程。这种设计使30B模型能高效吸收235B旗舰模型的知识,在多个基准测试中实现性能超越。
2. 推理能力跃居开源模型第一梯队
在数学推理领域,模型在AIME25竞赛题测试中取得85.0分的成绩,超越Gemini2.5-Flash-Thinking的72.0分和Qwen3-235B-A22B的81.5分,展现出接近人类竞赛选手的解题能力。代码生成方面,LiveCodeBench v6基准测试达到66.0分,较前代模型提升15%,在CFEval编程评估中更是达到2044分。

该对比图直观展示了Qwen3-30B-A3B-Thinking-2507与竞品模型在GPQA、AIME25、LiveCodeBench v6等关键基准测试中的表现。特别值得注意的是,在需要深度推理的任务中,该模型性能优势更为明显,印证了其"Thinking"模式的有效性。
3. 100万token上下文处理能力
通过Dual Chunk Attention(DCA)和MInference稀疏注意力机制的融合,模型实现了从256K到100万token上下文的突破。在RULER超长文本理解基准测试中,100万token场景下准确率达到79.6%,较前代模型提升65.1%,同时推理速度提升3倍。

这张科技概念图象征着模型在硬件与软件层面的协同创新,特别是动态KV缓存压缩算法的应用,使256K上下文场景下显存占用减少67%。在M4 Max设备上运行4bit量化版本时,即使处理满256K上下文仍能保持20+ tokens/s的生成速度。
行业影响与应用场景
科研与学术领域
模型的超长上下文能力为学术研究带来变革,能一次性处理完整的研究论文集(约100篇相关文献)并生成综述,或对300页的实验数据报告进行深度分析。某高校科研团队测试显示,使用该模型进行文献综述撰写可节省60%的时间,同时引用准确性提升28%。
企业级文档处理
在金融和法律领域,模型可高效处理1000页以上的合同文档、年报或案例集。通过1M token上下文支持,实现跨文档的条款比对和风险点识别。某法律咨询公司测试表明,模型对100万字法律案例库的相关条款检索准确率达到92%,远超传统关键词搜索的75%。
AI Agent开发
Qwen3-30B-A3B-Thinking-2507的工具调用能力与推理深度的结合,使其成为构建专业AI Agent的理想选择。通过Qwen-Agent框架,开发者可快速搭建具备复杂问题解决能力的智能体,在模拟电商客服场景中,任务完成率达到89%,较非推理优化模型提升37%。
部署指南与最佳实践
硬件配置要求
- 256K上下文:单张A100(80GB)或同等配置GPU,总内存需求120GB
- 1M上下文:4张A100(80GB)组成的GPU集群,总内存需求240GB
快速部署步骤
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Thinking-2507
cd Qwen3-30B-A3B-Thinking-2507
# 配置1M上下文支持(如需)
mv config.json config.json.bak
mv config_1m.json config.json
# 使用vLLM部署
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./ \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85 \
--enable-reasoning --reasoning-parser deepseek_r1
参数调优建议
- 推理任务:temperature=0.6, top_p=0.95, max_new_tokens=8192
- 文本生成:temperature=0.8, top_p=0.9, max_new_tokens=32768
- 长文档处理:启用DCA和MInference优化,chunk size设置为8K-16K
未来展望与挑战
Qwen3-30B-A3B-Thinking-2507将上下文边界推向1M token,标志着大语言模型进入"超长文本理解"新纪元。下一代模型将致力于在单GPU上实现1M token处理,并解决超长序列中的注意力稀释问题。
然而挑战依然存在:240GB的GPU内存需求对普通企业仍是门槛,1M token处理的能耗成本也需优化。随着技术的迭代,我们期待看到更高效的推理优化和更广泛的硬件适配,使超长上下文能力惠及更多用户。
结语
Qwen3-30B-A3B-Thinking-2507通过架构创新和定向优化,在30B参数级别实现了推理性能的质的飞跃,重新定义了中等规模大语言模型的能力边界。其在数学推理、代码生成和超长文本处理方面的突破,为科研机构和企业用户提供了强大的AI工具。
随着大语言模型向"高效推理"和"专业深化"方向发展,这款模型不仅是当前技术水平的展示,更预示着未来大语言模型的发展路径。对于开发者和企业而言,把握这种兼具效率与性能的模型技术,将成为AI应用落地的关键竞争优势。
要获取完整技术文档和更新,可关注项目仓库并加入开发者社区,共同探索大语言模型推理能力的边界。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







