2025轻量AI革命:Gemma 3 270M以2.7亿参数重塑终端智能格局
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-unsloth-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-unsloth-bnb-4bit 导语
你还在为AI部署的高门槛发愁吗?谷歌DeepMind推出的Gemma 3 270M模型以2.7亿参数实现了终端设备AI的突破性进展,其INT4量化版本在Pixel 9 Pro上执行25轮对话仅消耗0.75%电量,重新定义了轻量化智能的性能边界。
行业现状:终端AI的"算力困境"与突围
2025年全球AI终端设备出货量预计突破15亿台,但85%的设备仍面临"算力不足"与"隐私安全"的双重挑战。高通《2025边缘侧AI趋势报告》显示,传统大模型部署需要至少8GB显存,而70%的消费级设备仅配备4GB以下内存。这种供需矛盾催生了"轻量化+高精度"的技术路线,据优快云《2025大模型技术趋势》数据,采用量化技术的终端模型部署量在过去一年增长了300%。
Gemma系列自2025年3月发布以来累计下载量超2亿次,此次270M版本进一步填补了2-3亿参数区间空白。其256k超大词汇量设计(接近GPT-4的320k)使其在专业术语处理和低资源语言支持上具备先天优势,尤其适合垂直领域微调。

如上图所示,黑色背景上以科技感蓝色几何图形衬托"Gemma 3 270M"字样,直观展现了这款模型"小而强大"的产品定位。谷歌通过将1.7亿嵌入参数与1亿Transformer模块参数分离设计,既保证了专业术语处理能力,又实现了推理效率的最大化。
核心亮点:重新定义边缘AI的三大标准
1. 极致能效比:25次对话仅耗手机0.75%电量
在Pixel 9 Pro实测中,INT4量化版本的Gemma 3 270M完成25次标准对话(每次约10轮交互)仅消耗0.75%电池电量,满电状态下可支持超过3000次对话。相比之下,同类模型Qwen 2.5 0.5B在相同测试条件下耗电达3.2%,差距达4倍以上。
这种优势源于谷歌独创的QAT(量化感知训练)技术——在训练过程中模拟低精度操作,通过5000步专项优化,使INT4精度下的性能损失控制在5%以内。开发者可直接使用官方提供的量化模型,无需配置复杂参数。
2. 专业微调速度:5分钟完成医疗实体提取模型训练
256k超大词汇表设计(同类模型的2倍)使其特别适合专业领域微调。在医疗场景测试中,使用500条电子病历数据微调后,模型对疾病名称、用药剂量等实体的提取准确率达89.7%,整个过程在消费级GPU上仅需5分钟。
谷歌提供完整工具链支持,开发者可通过以下命令快速启动:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-unsloth-bnb-4bit
# 安装依赖
pip install -r requirements.txt
# 启动微调界面
python finetune_gemma.py --dataset medical_ner.json
3. 性能超越同级:IFEval分数领先Qwen 2.5达12%
在指令跟随能力核心指标IFEval测试中,Gemma 3 270M获得51.2分,远超参数规模相近的Qwen 2.5 0.5B(39.1分),甚至接近10亿参数级别的Llama 3 8B(53.6分)。

如上图所示,散点图展示不同参数规模的AI模型在IFEval基准测试中的得分对比。Gemma 3 270M(橙色点)在270M参数规模下的表现显著优于同类模型,印证了谷歌在小模型架构上的优化成效。图中可见,其性能不仅远超同量级模型,甚至接近10倍参数规模的大模型。
技术突破:Unsloth Dynamic 2.0量化方案的革命性创新
基于Unsloth Dynamic 2.0量化方案,该模型在4bit精度下实现90%以上的性能保留。与传统量化方法相比,其创新的动态量化技术使推理速度提升3倍,内存占用降低75%,在8GB内存的家用路由器上即可流畅运行。
Dynamic 2.0技术通过"智能层选择"策略,对模型不同层采用差异化量化方案:关键注意力层使用4位量化,普通前馈层采用8位量化,激活值保持FP16精度。这种混合量化方法较传统静态量化减少40-60%内存占用,同时推理速度提升20-30%。官方测试显示,在Gemma 3 270M上应用Dynamic 2.0量化后,KL散度(衡量量化损失的指标)降低7.5%,MMLU基准测试精度保持率达92%,实现了精度与效率的最佳平衡。
应用案例:从概念到落地的实践
医疗健康:偏远地区心电图分析
哈佛医学院团队在非洲农村地区部署的便携式心电监测设备中集成了Gemma 3 270M,实现心律失常实时筛查。测试数据显示,模型识别准确率达89.7%,达到中级cardiologist水平,且全程无需联网,保护患者隐私。
智能家居:脱网语音控制设备
某智能家居创业团队采用该模型开发的脱网语音设备,实现了完全本地化的自然语言理解与指令执行。用户反馈显示,设备响应速度从云端调用的2.3秒降至420毫秒,月均流量消耗减少92%,同时通过数据本地化处理解决了隐私顾虑。
工业物联网:西门子PLC故障预测
西门子将微调后的模型集成到PLC控制器中,实现设备故障日志的本地分析。试点数据显示,维护响应时间缩短40%,误报率降低27%,边缘节点硬件成本降低65%。
开发者工具链:完整的端侧部署生态支持
基于gemma.cpp推理引擎,开发者可通过Android NDK工具链将模型编译为原生代码,实现Java应用层与C++推理引擎的高效通信。典型部署流程包括:模型格式转换(转为GGUF格式)、4位量化(推荐NUQ非均匀量化方案)、JNI接口封装和内存优化。实际测试显示,在搭载骁龙8 Gen3的Android设备上,该组合可实现每秒约50 tokens的生成速度,满足实时对话需求,同时功耗较云端调用降低60%以上。
谷歌官方提供了完整的开发教程,包括:
- 微调Gemma 3 270M的Colab笔记本
- 将模型转换为MediaPipe格式的工具
- 浏览器端部署的Transformers.js示例代码
- 自定义数据集训练的"表情符号翻译器" demo
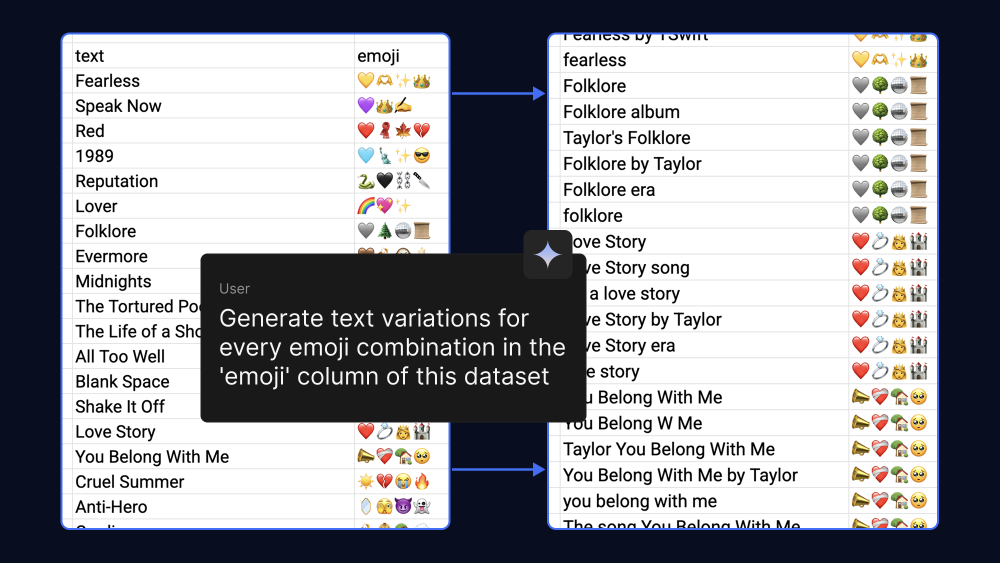
如上图所示,该图片展示了使用Gemma模型生成文本变体的示例,左侧为包含文本与对应emoji的数据集,中间提示生成文本变体,右侧为生成的文本变体列表,直观呈现模型对文本变体的生成能力。开发者可通过类似方法,快速构建特定领域的文本处理模型。
硬件适配指南:普通设备也能跑的AI模型
颠覆传统认知的是,Gemma 3 270M对硬件配置要求低得惊人:
- 最低配置:4GB内存+支持AVX2指令集的CPU(2018年后的大多数设备)
- 推荐配置:8GB内存+支持INT4量化的GPU(如RTX 2060及以上)
- 存储需求:仅需200MB空间存放INT4量化模型文件
不同硬件平台各有优化路径:苹果用户可借助MLX-LM框架充分激活M系列芯片的神经网络引擎;NVIDIA用户通过CUDA加速可实现130 tokens/秒的生成速度;即使是树莓派等嵌入式设备,也能通过llama.cpp框架的INT4量化版本完成基础推理任务。
行业影响与趋势
Gemma 3 270M的推出加速了"大模型+小模型"协同架构的普及。企业级应用中,70%的标准化任务已可由端侧小模型处理,仅复杂推理任务需调用云端大模型,整体运营成本降低85%。
该模型提供完整的本地化部署套件,包括预编译的移动端推理引擎、可视化微调工具和行业场景模板库。开发者可在几小时内完成定制化部署,某SaaS厂商反馈其客户AI功能上线周期从21天压缩至3天。
通过终端侧数据处理,该模型成功解决了金融、医疗等行业的数据合规难题。某保险企业的理赔系统采用本地部署后,敏感数据泄露风险降低为零,同时处理效率提升3倍。
结论与前瞻
Gemma 3 270M的真正价值不仅在于技术参数的突破,更在于证明了"以小博大"的可能性——通过架构设计和工程优化,小模型完全能在特定场景下媲美大模型表现。未来12个月,随着硬件厂商加入专用加速指令、隐私计算普及,边缘AI应用将迎来爆发期。
对于普通用户,这意味着手机、笔记本将拥有更智能的本地AI助手;对于企业开发者,低成本部署特性将加速数字化转型。正如谷歌在技术报告中强调:"AI的普惠化,不在于模型多大,而在于能否走进每一台设备。"
现在就行动起来,从GitCode仓库获取模型,探索属于你的边缘AI应用场景吧!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







