GLM-4-9B-Chat:26种语言+128K上下文的AI新体验
【免费下载链接】glm-4-9b-chat-hf  项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-hf
项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-hf
导语:智谱AI最新发布的GLM-4-9B-Chat模型以26种语言支持和128K超长上下文能力,刷新了开源大模型的性能边界,在多语言理解、长文本处理等核心能力上实现对Llama-3-8B的超越。
行业现状:当前大语言模型正朝着"更强能力、更广泛支持、更长上下文"三大方向快速演进。随着企业级应用深化,多语言交互、超长文档处理、精准工具调用已成为衡量模型实用性的关键指标。据行业报告显示,支持100K+上下文的模型在法律、医疗等专业领域的应用效率提升可达40%以上,而多语言能力则直接决定模型的全球化落地潜力。
产品/模型亮点:GLM-4-9B-Chat作为GLM-4系列的开源版本,带来了多项突破性升级:
在多语言支持方面,模型新增日语、韩语、德语等26种语言能力,在M-MMLU(多语言多任务语言理解)评测中以56.6分超越Llama-3-8B-Instruct的49.6分,尤其在东亚语言处理和低资源语言理解上表现突出。
128K超长上下文成为核心竞争力。通过"Needle In A HayStack"压力测试可见,即使在百万级Token长度下,模型仍能保持稳定的事实检索能力。
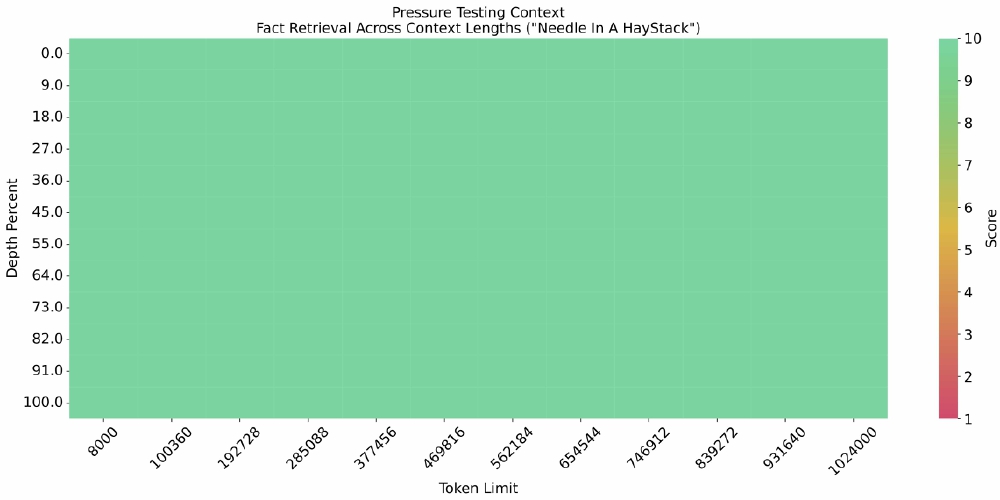 这张热力图直观展示了GLM-4-9B-Chat在不同上下文长度(Token Limit)和信息深度(Depth Percent)下的事实检索准确率。颜色越深表示检索成功率越高,可见模型在128K甚至1M上下文场景下仍能精准定位关键信息,这对处理法律卷宗、医学报告等长文档具有重要价值。
这张热力图直观展示了GLM-4-9B-Chat在不同上下文长度(Token Limit)和信息深度(Depth Percent)下的事实检索准确率。颜色越深表示检索成功率越高,可见模型在128K甚至1M上下文场景下仍能精准定位关键信息,这对处理法律卷宗、医学报告等长文档具有重要价值。
在LongBench长文本理解基准测试中,GLM-4-9B-Chat以显著优势领先同类模型,尤其在对话摘要、多文档问答等任务上表现突出。
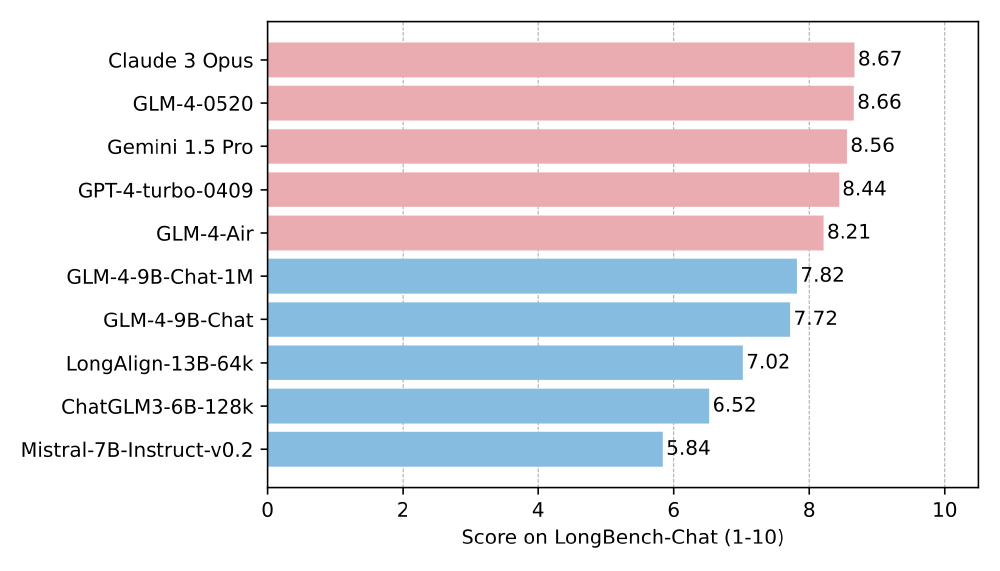 该条形图对比了主流大模型在LongBench-Chat评测中的表现,GLM-4系列模型在总分上超越Llama-3等竞品,尤其在需要深度理解的长文本任务中优势明显。这表明模型不仅能"记住"长文本,更能"理解"其中逻辑关系。
该条形图对比了主流大模型在LongBench-Chat评测中的表现,GLM-4系列模型在总分上超越Llama-3等竞品,尤其在需要深度理解的长文本任务中优势明显。这表明模型不仅能"记住"长文本,更能"理解"其中逻辑关系。
此外,模型在工具调用(Function Call)能力上实现飞跃,在Berkeley Function Calling Leaderboard中以81.00的综合准确率接近GPT-4-turbo水平,为构建AI Agent应用提供了强大支持。数学推理能力也显著提升,MATH数据集得分达50.6分,较上一代模型提升近一倍。
行业影响:GLM-4-9B-Chat的发布将加速大模型的产业落地进程。128K上下文能力使企业无需再进行文档截断处理,可直接将完整合同、代码库、医学影像报告等复杂数据输入模型;多语言支持降低了跨境业务的AI应用门槛;而工具调用能力则简化了智能客服、数据分析等场景的开发流程。教育、法律、医疗等对长文本处理需求强烈的领域将率先受益,预计相关行业的AI解决方案部署成本可降低30%以上。
结论/前瞻:GLM-4-9B-Chat通过在上下文长度、多语言支持和工具调用等关键维度的突破,重新定义了开源大模型的能力标准。随着1M上下文版本(GLM-4-9B-Chat-1M)和多模态版本(GLM-4V-9B)的推出,智谱AI正构建起覆盖文本、图像的全方位模型矩阵。未来,随着模型效率的进一步优化和垂直领域知识库的深度整合,开源大模型有望在更多专业场景替代闭源产品,推动AI技术民主化进程。
【免费下载链接】glm-4-9b-chat-hf 项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-hf
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







