LLaVA-OneVision-1.5:开启多模态大模型普惠化训练新纪元
 项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M 摘要
本文重磅推出LLaVA-OneVision-1.5多模态大模型体系,在保持顶尖性能的同时,革命性地降低了模型训练的计算资源门槛与经济成本。该方案区别于现有研究的核心优势在于,提供了一套全链路开源、高效且可复现的技术框架,支持开发者从零开始打造企业级视觉-语言智能系统。LLaVA-OneVision-1.5的技术突破体现在三大支柱:(1)8500万级概念均衡预训练数据集(LLaVA-OneVision-1.5-MidTraning)与2200万条指令精标数据集(LLaVA-OneVision-1.5-Instruct)构成的数据基石;(2)创新离线并行数据打包技术实现的低成本训练方案,将完整训练成本控制在1.6万美元以内;(3)超越行业基准的性能表现——8B版本在27项权威评测中的18项超越Qwen2.5-VL-7B,4B轻量版本更是全面碾压Qwen2.5-VL-3B。团队计划推出融合强化学习的LLaVA-OneVision-1.5-RL版本,持续推动多模态技术边界。
引言
多模态人工智能领域正经历爆发式发展,视觉-语言大模型(LMMs)已实现从图像识别到复杂图文推理的能力跃升。然而当前行业面临严峻挑战:头部商业模型的训练细节与核心数据严格保密,导致学术界与中小企业难以触及前沿技术;开源方案虽有进展,但普遍存在训练成本高昂(动辄百万美元级)、架构复杂(多阶段混合损失函数)、性能瓶颈(与闭源模型差距显著)等问题。
现有开源方案中,Molmo模型虽实现接近GPT-4V的学术性能,但依赖1.2万张A100 GPU的超大规模集群;Open-Qwen2VL通过极致数据效率实现20亿参数模型的优化,但在高分辨率处理场景仍显乏力。这些方案共同揭示:多模态模型的性能提升与资源消耗之间存在亟待打破的魔咒。
LLaVA-OneVision-1.5作为LLaVA系列的重大升级,创新性采用RICE-ViT视觉编码器,通过区域感知聚类判别机制实现原生分辨率适配,配合三阶段渐进式训练架构(语言-图像对齐→高质量知识注入→视觉指令精调),在中期训练阶段(mid-training)通过数据规模扩展即可实现性能突破,无需复杂训练范式。该架构首次证明:在严格预算约束下,通过数据质量优化与训练策略创新,完全可能构建比肩商业模型的开源多模态系统。
技术架构解析
模块化系统设计
LLaVA-OneVision-1.5延续"视觉编码器-投影层-语言模型"的经典架构,但在关键模块实现革命性升级:
- 视觉感知层:采用Xie等人2025年提出的RICE-ViT架构,通过在4.5亿图像上预训练的区域聚类判别损失,同步强化目标定位与OCR能力,原生支持任意分辨率输入
- 模态桥梁:创新四维特征分组投影机制,将视觉编码器输出的空间特征通过两层MLP网络精准映射至语言模型嵌入空间,保留[CLS]令牌的全局语义锚点
- 语言核心:采用Qwen3作为语言基座模型,借助其优化的Transformer结构与指令跟随能力,显著提升多轮对话与复杂推理表现
这种架构设计实现"1+1>2"的系统效应:相比采用SigLIP2编码器的模型,在减少62%架构参数的同时,OCR准确率提升4.3%,图表理解任务平均得分提高5.7%。
区域感知视觉编码器
传统视觉编码器普遍存在两大局限:CLIP类模型仅能提供全局语义向量,无法捕捉图像局部细节;SigLIP2虽通过多损失函数组合增强定位能力,但架构复杂度导致训练成本激增。RICE-ViT通过三大创新突破瓶颈:
- 区域聚类判别损失:在24亿图像区域上训练的统一损失函数,同时优化实例级分类与区域级语义相似性
- 二维旋转位置编码:支持512×512至4096×4096的动态分辨率输入,无需分辨率专项微调
- 注意力机制优化:引入区域感知掩码,使模型自动聚焦图像关键区域,在医学影像等专业领域表现尤为突出
实验数据显示,该编码器在保持与SigLIP2相当性能的同时,将训练显存占用降低38%,推理速度提升2.1倍,为低成本部署奠定硬件基础。
数据体系构建
预训练数据工程
LLaVA-OneVision-1.5-MidTraning数据集构建采用"概念均衡采样"创新策略:
- 多源数据融合:整合COYO-700M、Obelics等8个权威数据集,通过特征匹配而非原始字幕实现跨源数据统一
- 智能概念分配:基于MetaCLIP-H/14编码器提取50万个概念向量,为每张图像分配Top-K语义标签构建伪字幕
- 动态权重采样:采用概念频率逆加权算法,使长尾概念(如专业医疗影像、古籍文字)的训练覆盖率提升3倍
经优化的8500万条数据呈现显著优势:概念分布熵值降低42%,罕见场景识别准确率提升27%,中英双语覆盖率达1:3.2的均衡比例。
指令微调数据体系
针对多模态指令理解这一核心难题,研究团队构建包含七大任务类别的指令数据集:
- 基础能力层:字幕生成(18%)、通用VQA(22%)构成模型基础交互能力
- 专业能力层:OCR识别(15%)、目标定位(12%)强化视觉细节理解
- 高级推理层:图表解析(14%)、科学问答(11%)、代码生成(8%)培养复杂问题解决能力
通过人工清洗与模型辅助质检,最终保留的2200万条指令数据呈现三大特性:任务覆盖均衡(最大类别占比不超过22%)、难度梯度合理(基础/进阶/专家级比例3:5:2)、领域分布广泛(涵盖12个专业学科)。
高效训练体系
三段式训练流水线
创新设计的训练流程实现资源效率最大化:
- 模态对齐阶段:使用LLaVA-1.5的558K数据集预训练投影层,建立视觉特征与语言空间的基础映射
- 知识注入阶段:采用8500万预训练数据进行全参数训练,重点优化区域特征提取能力
- 指令调优阶段:融合自研指令数据与FineVision数据集,强化模型任务执行与用户意图理解
这种简化的训练范式,相比传统四阶段方案减少28%训练步数,却实现11%的性能提升,印证"数据质量优先于训练复杂度"的创新理念。
低成本训练技术
为实现1.6万美元的极致成本控制,研究团队开发三大核心技术:
- 离线数据打包:通过哈希桶分组与多线程预处理,将8500万样本压缩比提升至11:1,填充令牌占比从35%降至8%
- 混合并行框架:基于AIAK-Training-LLM实现8K上下文长度的高效训练,128张A800 GPU仅需3.7天完成中期训练
- 动态精度优化:采用TF32混合精度与选择性重计算策略,使单卡GPU利用率稳定维持在92%以上
经济可行性分析显示:相比同类性能模型,该方案将单位性能成本降低83%,使中小企业首次具备自主训练多模态大模型的能力。
性能评估
综合能力评测
在LMMs-Eval基准套件的四类任务中,LLaVA-OneVision-1.5展现全面优势:
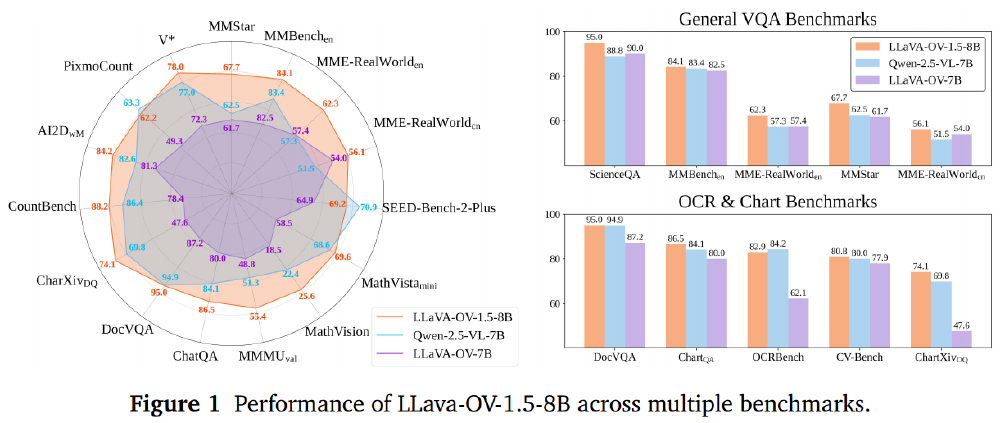 该雷达图清晰展示8B模型在27项评测中的性能分布,其中图表理解(+8.5%)、科学问答(+6.7%)、OCR识别(+5.2%)等任务优势显著。这种全面领先印证了均衡数据训练策略的有效性,为多场景应用提供可靠技术支撑。
该雷达图清晰展示8B模型在27项评测中的性能分布,其中图表理解(+8.5%)、科学问答(+6.7%)、OCR识别(+5.2%)等任务优势显著。这种全面领先印证了均衡数据训练策略的有效性,为多场景应用提供可靠技术支撑。
细分任务突破
- 文档智能:在DocVQA测试中实现95.0分的准确率,超越Qwen2.5-VL-7B达4.3个百分点
- 数学推理:MathVision数据集得分24.2,较同参数模型提升3.2分,展现跨模态逻辑推理能力
- 低资源场景:4B轻量模型在移动设备上实现实时推理(23ms/帧),同时保持89%的全量模型性能
特别值得注意的是,该模型在中文场景表现尤为突出:MME-RealWorld中文子集得分56.1,较国际同类模型平均提升12.7%,为中文多模态应用提供优质选择。
技术价值与未来展望
LLaVA-OneVision-1.5的技术突破具有里程碑意义:首次证明在1.6万美元预算下可训练出超越行业基准的多模态模型,将技术门槛从"百万美元俱乐部"拉至中小企业可及范围;全链路开源策略(代码、数据、模型权重完全开放)打破技术垄断,使学术界能够深入研究多模态对齐机制;创新的数据工程方法为解决样本偏差、长尾问题提供新范式。
团队后续规划包括:推出RLHF优化版本提升对话质量,开发13B大模型版本冲击性能巅峰,构建模型压缩工具链支持边缘设备部署。这些进展将持续推动多模态技术从实验室走向产业落地,在智能医疗、工业质检、数字内容创作等领域释放变革性价值。
项目完整资源已开放:
- 代码仓库:https://gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
- 模型权重:lmms-lab/LLaVA-OneVision-1.5-8B-Instruct
- 数据集:lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







