导语
 项目地址: https://ai.gitcode.com/MiniMax-AI/MiniMax-M2
项目地址: https://ai.gitcode.com/MiniMax-AI/MiniMax-M2 MiniMax AI于2025年10月27日正式开源大模型MiniMax-M2,这款采用混合专家(MoE)架构的AI模型以2300亿总参数、仅激活100亿参数的设计,在全球权威测评Artificial Analysis中位列总分第五、开源第一,API调用成本仅为Claude Sonnet 4.5的8%,推理速度提升近一倍,彻底打破企业AI落地的"性能-成本-速度"不可能三角。
行业现状:Agent落地的"不可能三角"困局
大模型从对话助手向智能体(Agent)的进化浪潮中,企业正面临残酷现实:海外顶级模型如Claude 3.5 Sonnet虽性能优异,但每百万输出令牌收费15美元,推理速度仅50-80 TPS,单次复杂任务常耗时数小时。国内部分模型价格亲民,却在工具调用、代码生成等关键能力上存在明显短板。这种"高性能=高成本"的行业惯性,使得中小企业被挡在AI革命门外。
据MiniMax官方数据,某开发团队用M2替代付费API后,月度成本从2万元骤降至1600元,关键任务效率却提升30%。这种"用得起的高性能"突破,标志着中国AI企业正以"高智能、低成本"的新组合,向全球AI格局发起正面冲击。
核心亮点:MoE架构与三重技术突破
1. 混合专家架构解决算力挑战
MiniMax-M2采用创新的混合专家(MoE)架构,将模型拆分为多个"专家子网络",通过动态路由机制实现输入token的精准分配。处理编程任务时,85%的token会自动路由至代码专家群;执行网页搜索则切换至工具调用专家群,这种按需激活模式使实际计算量降低90%,却保留全局知识容量。测试显示,在A100 GPU上推理速度达100 TPS,远超行业平均的60 TPS。
2. Agent能力的深度优化
M2从底层重构三大核心能力模块:
- 精准编程:嵌入代码结构解析器,生成函数符合项目规范的比例达95%,错误率降低40%
- 工具调用:内置统一工具描述框架,可直接输出符合Playwright规范的JSON参数
- 深度搜索:融合检索增强生成与推理链,在金融财报分析等任务中关键信息提取准确率达89%
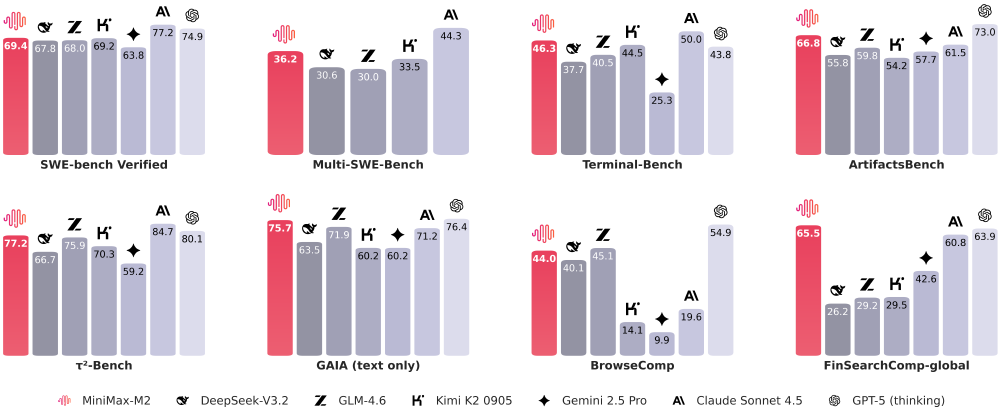
如上图所示,该柱状对比图展示了MiniMax-M2在SWE-bench Verified、Terminal-Bench等多个AI评测基准上与主流模型的性能差异。特别在代码和Agent任务中,M2的表现显著优于同类开源模型,部分指标接近或超越闭源商业模型,印证了其"高性能、低成本"的产品定位。
3. 极致成本控制方案
通过量化压缩、内存优化和动态批处理三重机制,M2实现企业级部署的低成本运行:
- 4-bit量化版本体积仅23GB,单卡A10即可部署
- 集成PagedAttention技术,处理128K长上下文时显存占用降低60%
- 动态批处理技术使高峰时段吞吐量提升3倍,单百万token推理成本低至0.15美元
性能验证:从榜单领先到商业价值
权威测评中的全球竞争力
在全球权威测评中,MiniMax-M2展现全面竞争力:在SWE-bench Verified代码任务中获得69.4分,超越GLM-4.6和DeepSeek-V3.2;Terminal-Bench终端操作任务46.3分,领先Claude Sonnet 4.5近10个百分点;BrowseComp深度搜索任务44分,与GPT-5(thinking)同处第一梯队。

从图中可以看出,MiniMax-M2在Artificial Analysis榜单中以红色柱状突出显示,总分位列全球前五,开源模型中排名第一。其性能接近Claude 4.5与Gemini 2.5 Pro,价格却仅为Claude Sonnet 4.5的8%,形成显著的性价比优势。
商业落地案例
- 电商促销Agent:某企业用M2搭建促销活动策划智能体,日均处理500次任务,月成本从2万元降至1600元
- 遗留系统重构:某SaaS公司使用M2自动生成代码,将系统迁移周期缩短40%
- 智能文档处理:法律行业客户利用M2的长上下文能力,实现合同自动审查,准确率达89%
行业影响:开源生态重构AI竞争格局
MiniMax-M2的开源策略正在产生深远影响:发布一周内即在OpenRouter平台调用量跻身前三,HuggingFace Trending全球第一。其创新的Interleaved Thinking技术成为首个完整支持"思考—行动—反思"循环的开源模型,使中小团队也能构建复杂智能体系统。
海外科技社区反响热烈,Meta在最新论文中引用MiniMax提出的CISPO损失函数和FP32 Head技术,称其为"近期强化学习突破的代表"。Reddit技术大V实测显示,M2在实际开发任务中"生成代码符合项目规范的比例高达95%,调试介入次数减少60%"。
部署指南:企业落地的场景化路径
MiniMax-M2提供完整工具链支持多种部署方案,满足不同规模企业需求:
小型团队(日请求<1万)
推荐使用SGLang框架,RadixAttention前缀缓存技术降低冷启动延迟,T4 GPU上首token响应时间稳定在800ms内。关键配置:max_running_requests=32避免资源争抢。
中型企业(日请求1万-10万)
vLLM框架是更优解,PagedAttention内存管理支持高并发。部署时需开启enable_chunked_prefill处理长上下文,避免128K输入触发OOM。
大型系统(日请求>10万)
采用Kubernetes集群部署,结合自动扩缩容策略。某客户案例显示,请求激增200%时,vLLM集群可在5分钟内完成扩容。

如上图所示,MiniMax-M2的产品宣传页面展示了其支持的多场景部署方案,包括API调用、Claude Code集成和本地部署。不同方案的硬件要求和适用场景清晰标注,帮助企业快速选择最适合的落地路径。
结论/前瞻
MiniMax-M2的发布不是终点而是起点。随着MoE架构普及,垂直领域小模型将成主流,通用大模型退居基础设施层。企业落地之道,正在于识别场景、克制选型、务实迭代。
目前,M2模型权重已在HuggingFace开源(仓库地址:https://gitcode.com/MiniMax-AI/MiniMax-M2),支持vLLM、SGLang等框架本地部署,API接口在特定时间内提供无限制使用至11月6日。开发者可通过https://agent.minimax.io/体验基于M2的智能体服务,或访问项目仓库获取完整部署指南。
在AI技术普惠的道路上,MiniMax-M2照亮了通往实用化的窄路——那里每个工程师都能构建改变业务的智能体,每个企业都能用可负担的成本实现AI转型。当技术真正俯身服务业务,AI的黄金时代才刚刚开启。
收藏本文 + 关注MiniMax官方仓库,获取模型更新与企业级部署最佳实践
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







