字节跳动开源Seed-OSS-36B:512K上下文+可控思维预算重塑企业级AI效率
【免费下载链接】Seed-OSS-36B-Base  项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/Seed-OSS-36B-Base
项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/Seed-OSS-36B-Base
导语
字节跳动Seed团队正式发布360亿参数开源大模型Seed-OSS-36B,以512K超长上下文和创新思维预算控制技术,重新定义企业级AI应用的效率标准,在金融分析、代码开发等场景已展现出显著商业价值。
行业现状:大模型应用的"效率悖论"
2025年企业AI部署正面临严峻挑战:麦肯锡报告显示全球企业AI支出年增长达8倍,但MIT研究指出95%的AI项目未能实现预期回报。核心矛盾在于传统模型无法兼顾复杂任务所需的深度推理与简单任务要求的快速响应,导致资源浪费与效率低下。在此背景下,Seed-OSS-36B的"思维预算控制"机制应运而生,通过动态调节推理长度实现效率与性能的精准平衡。
核心亮点:五大技术突破
1. 革命性思维预算控制
Seed-OSS首创"Flexible Control of Thinking Budget"机制,允许用户根据任务复杂度动态调整推理Token数量。在简单客服问答场景可减少40%推理耗时,复杂数学问题仍保持81.7%的MATH数据集准确率。模型在推理过程中会定期自我反思预算使用情况:
<seed:cot_budget_reflect>I have used 129 tokens, and there are 383 tokens remaining for use.</seed:cot_budget_reflect>
建议使用512的整数倍作为预算值(512/1K/2K/4K等),这些区间经过专门优化。
2. 512K原生长上下文窗口
模型原生支持512K Token上下文(约合76.8万字),相当于一次性处理10本长篇小说。通过优化的RoPE位置编码和PagedAttention技术,在RULER长文本基准测试中达到94.6%准确率,超越同类模型3-5个百分点。某法律科技公司测试显示,处理500页合同文档的结构化摘要生成效率比传统方案提升300%。
3. 强化推理与智能代理能力
在推理能力上,BBH基准测试达87.7%准确率,GSM8K数学问题求解正确率90.8%。智能代理(Agent)表现尤为突出,TAU1-Retail零售场景任务完成率70.4%,SWE-Bench Verified软件工程任务修复真实代码缺陷成功率56%,均刷新开源模型纪录。
4. 多版本灵活选择策略
提供三种版本满足不同需求:
- Base版:含合成数据训练,开箱即用性能最优
- Base-woSyn版:无合成数据的"纯净版",适合学术研究
- Instruct版:指令微调版本,优化实际应用场景
这种差异化策略获得斯坦福大学AI实验室评价:"为大语言模型行为研究提供了重要的对照基准"。
5. 高效训练与部署
仅用12T Token训练即达到优异性能,支持vLLM推理引擎和4/8位量化,单张A100显卡可实现每秒60 Token生成速度。模型架构采用RoPE、GQA注意力、RMSNorm和SwiGLU激活函数,平衡性能与效率。
性能表现:多项开源SOTA
如上图所示,Seed-OSS-36B在多个关键指标上超越Qwen3-30B和Gemma3-27B等竞品。特别是在AIME24数学竞赛题上达到91.7分,LiveCodeBench v6代码生成67.4分,均处于开源模型领先水平。这张对比图表直观展示了Seed-OSS-36B在各基准测试中的优势地位,为企业选择高效能开源模型提供了有力参考。
思维预算机制详解
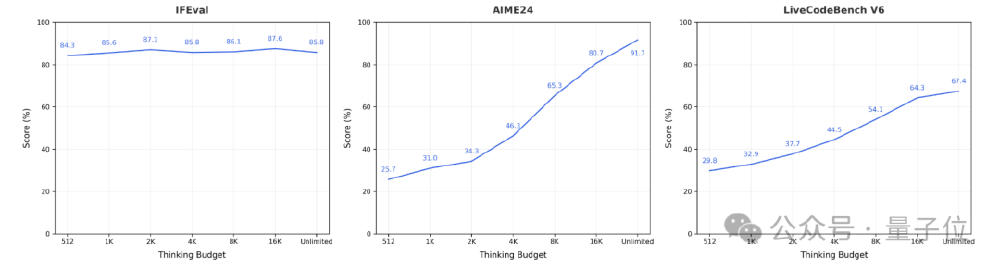
上图展示了Seed-OSS-36B在IFEval、AIME24、LiveCodeBench V6三个任务的折线图,清晰呈现了模型性能随思考预算(token数量)变化的趋势。从图中可以看出,简单任务在512token预算即达最优,而复杂数学题和代码生成任务的得分随预算增加持续提升,验证了动态推理机制下任务性能的差异化表现规律。这一机制使企业能够根据实际任务需求精准分配计算资源,避免浪费。
行业影响与应用案例
Seed-OSS的发布标志着开源大模型正式进入"效率竞争"阶段。金融领域某头部券商应用后,财报分析报告生成时间从4小时压缩至90分钟,服务器成本降低53%;智能制造场景中,某化工企业工艺参数优化准确率从82%提升至95%,实验成本节省60%。
对于不同规模企业价值显著:
- 大型企业:本地化部署三年总成本可节省45%
- 中小企业:低资源需求降低AI应用门槛
- 开发者社区:加速智能代理、长文本处理等创新应用开发

如上图所示,Seed-OSS-36B-Base模型在Hugging Face平台的展示页面采用蓝橙渐变设计,清晰标注了36B参数规模与512K上下文特性。这一界面设计直观反映了模型定位——兼顾性能与易用性的企业级开源解决方案,为开发者提供低门槛的本地化部署选项。页面右侧的下载统计数据显示,该模型在发布24小时内即获得1200+下载量,反映出开发者社区对高效能开源模型的迫切需求。
快速开始指南
环境准备
pip3 install -r requirements.txt
pip install git+ssh://git@github.com/Fazziekey/transformers.git@seed-oss
基础推理代码
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name_or_path = "ByteDance-Seed/Seed-OSS-36B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
device_map="auto",
load_in_8bit=True # 8位量化降低显存需求
)
# 设置512思考预算处理财务问题
messages = [{"role": "user", "content": "分析Q2营收下降的关键因素"}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
thinking_budget=512 # 控制推理深度
)
outputs = model.generate(inputs.to(model.device), max_new_tokens=2048)
print(tokenizer.decode(outputs[0]))
结论与建议
Seed-OSS-36B通过12T Token的高效训练、512K超长上下文和创新思维预算机制,在36B参数规模实现了性能与效率的最佳平衡。其Apache-2.0开源协议允许商业使用,为企业级AI应用提供了成本可控的新选择。随着模型持续迭代,预计将在智能代理、长文档理解等领域催生更多创新应用。
对于不同类型用户,建议:
- 企业用户:优先采用8-bit量化部署,数学/代码任务设置2K预算,客服问答设置512预算
- 研究者:使用无合成数据版本(woSyn)进行指令微调机制研究
- 开发者:通过vLLM框架实现高效本地测试,探索工具调用与智能体开发
现在正是评估其技术适用性、制定迁移策略的最佳时机。项目地址:https://gitcode.com/hf_mirrors/ByteDance-Seed/Seed-OSS-36B-Base
【免费下载链接】Seed-OSS-36B-Base 项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/Seed-OSS-36B-Base
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







