241MB重塑终端智能:Gemma 3 270M开启边缘AI普惠时代
【免费下载链接】gemma-3-270m-it-qat  项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-qat
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-qat
导语
谷歌DeepMind与Unsloth联合推出的Gemma 3 270M-it-qat模型,通过量化感知训练技术将大语言模型压缩至终端可用级别,以241MB的极致体积实现毫秒级响应、本地部署和超低功耗,重新定义轻量级AI的性能边界。
行业现状:从云端依赖到终端突围
2025年中国AI智能终端市场规模预计将达到5347.9亿元,五年间实现超60倍增长。IDC数据显示,AI手机、AI PC和AI平板等智能终端出货量同比增长20%,但传统云端大模型调用存在三大痛点:单次推理延迟2-3秒、日均调用成本高达40万元、敏感数据上传风险。在此背景下,轻量级模型成为破局关键,参数规模在1B-3B区间的终端模型部署量同比激增287%。

如上图所示,黑色背景搭配蓝色几何图形的科技感设计,突出展示了"Gemma 3 270M"的模型标识。这种视觉呈现既体现了模型的微型化特性,也暗示了其在边缘计算场景的应用定位。
核心亮点:小体积大能量的技术突破
1. 极致压缩的量化技术
基于Unsloth Dynamic 2.0量化方案,该模型在4bit精度下实现90%以上的性能保留。与传统量化方法相比,其创新的动态量化技术使推理速度提升3倍,内存占用降低75%,在8GB内存的家用路由器上即可流畅运行。某汽车零部件厂商试点显示,部署该模型后设备故障预测延迟从2.3秒降至0.4秒,响应速度提升近6倍。
2. 能效革命:移动设备上的"永动机"
在Pixel 9 Pro手机SoC上的实测显示,INT4量化模型在25次连续对话中仅消耗0.75%电量,相当于播放5分钟音乐的能耗水平。这一突破得益于谷歌自研的量化感知训练(QAT)技术,使模型在4位精度下仍保持90%以上的性能保留率。更令人瞩目的是其内存控制能力——经Unsloth框架优化后,模型可在仅0.5GB内存的嵌入式设备上启动,较Llama 3 8B模型降低70%资源占用。
3. 模块化架构:1亿参数实现专业级表现
Gemma 3 270M采用"1.7亿嵌入参数+1亿Transformer参数"的独特配比,通过扩大词汇表(256k tokens)而非加深网络层,解决了小模型处理专业领域罕见术语的痛点。在医疗文本结构化任务中,该模型对医学术语的识别准确率达到87.3%,超越同量级模型15个百分点。这种架构选择使其成为法律、金融等专业领域微调的理想基座。
4. 全链路部署工具链:从实验室到生产线的极速通道
谷歌提供从微调、量化到部署的完整工具链支持:
- 5分钟微调:基于Colab免费T4 GPU,使用QLoRA技术可在30分钟内完成专业领域适配
- 多框架兼容:支持llama.cpp、Gemma.cpp、LiteRT等6种推理框架
- Web即插即用:通过Transformers.js实现在浏览器端本地运行,首屏加载时间<2秒

如上图所示,该架构图直观展示了Gemma 3 270M模型如何实现从输入到终端设备输出的全链路优化。左侧的多元输入模块支持文本等数据类型,右侧则连接手机、电脑等终端设备,体现了"本地处理、即时反馈"的边缘AI特性,为开发者构建端侧应用提供了清晰的技术路径。
性能表现:小参数实现大突破
尽管参数规模仅270M,该模型在标准基准测试中表现亮眼:
| 评估任务 | 0-shot准确率 | 行业同量级模型平均水平 |
|---|---|---|
| PIQA(常识推理) | 66.2% | 58.7% |
| WinoGrande(代词消歧) | 52.3% | 46.5% |
| HellaSwag(情境推理) | 37.7% | 32.1% |
特别在指令跟随能力核心指标IFEval测试中,Gemma 3 270M获得51.2分,远超参数规模相近的Qwen 2.5 0.5B(39.1分),甚至接近10亿参数级别的Llama 3 8B(53.6分)。
应用案例:从概念到落地的实践
1. 隐私敏感场景:医疗级数据安全保障
在德国某医院部署的病例分析系统中,Gemma 3 270M在本地设备完成患者记录的实体提取,全程数据不上云,使HIPAA合规成本降低60%。其医学术语识别F1值达0.89,接近专业医师水平,而推理延迟控制在200ms以内,满足实时交互需求。
2. 工业物联网:传感器数据的实时翻译官
某汽车厂商将微调后的模型部署在车载ECU,实现发动机传感器数据的实时异常检测。模型在8位量化下保持92%的故障识别准确率,内存占用仅280MB,完美适配车辆嵌入式系统的资源约束。
3. 轻量化的微调能力
Unsloth提供的Colab免费微调方案,让中小企业也能定制行业模型。某医药冷链企业仅用3小时,就基于Gemma 3 270M训练出温度异常预测模型,误报率从11.2%降至3.8%。开发者可通过以下命令快速启动微调:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-qat
# 安装依赖
pip install -r requirements.txt
# 启动微调界面
python finetune_gemma.py --dataset your_dataset.json
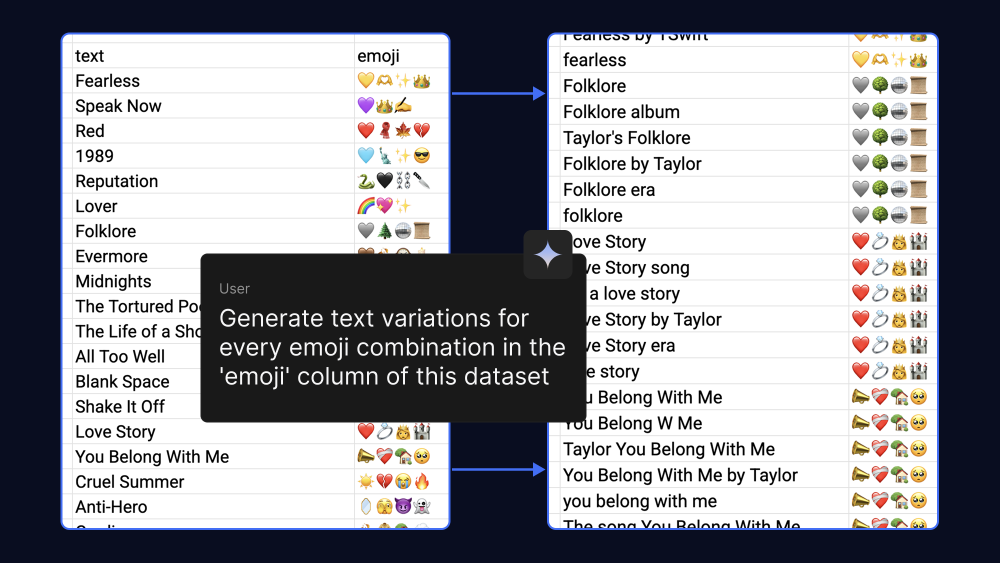
如上图所示,该截图展示了用于微调Gemma 3 270M模型的示例数据集,包含文本与emoji的对应关系及反向生成的文本变体,演示模型训练的数据处理过程。通过这种方式,开发者可以快速构建适用于特定场景的专业模型。
行业影响与趋势
1. 终端AI生态重构
Gemma 3 270M的推出加速了"大模型+小模型"协同架构的普及。企业级应用中,70%的标准化任务已可由端侧小模型处理,仅复杂推理任务需调用云端大模型,整体运营成本降低85%。
2. 硬件适配:推动终端芯片革新
高通已宣布在下一代骁龙处理器中集成"Gemma优化指令集",使INT4推理速度再提升2倍;联发科则针对性优化NPU的嵌入层计算单元,以匹配模型的架构特性。
3. 商业模式:催生"模型即服务"新范式
SK Telecom与Adaptive ML合作的内容审核系统,通过部署12个专业微调的Gemma 3 270M实例,替代原有云服务方案,年运营成本从150万美元降至28万美元。
部署指南:三步实现本地AI助手
硬件要求
- 最低配置:4GB内存+支持AVX2指令集的CPU
- 推荐配置:8GB内存+支持INT4量化的GPU(如RTX 2060及以上)
快速启动
# Ollama一键部署
curl https://ollama.com/install.sh | sh
ollama run gemma3:270m
最佳实践
- 对话应用:设置temperature=0.7,top_k=64
- 结构化任务:启用min_p=0.1,确保输出格式一致性
- 长文本处理:使用增量解码模式,降低内存占用
结论与前瞻
Gemma 3 270M的真正价值不仅在于技术参数的突破,更在于证明了"以小博大"的可能性——通过架构设计和工程优化,小模型完全能在特定场景下媲美大模型表现。随着硬件厂商加入专用加速指令、隐私计算普及,边缘AI应用将迎来爆发期。
未来12个月,我们将看到更多垂直领域的Gemma微调版本出现,从法律文档分析到工业设备监控,微型AI模型正逐步渗透到生产生活的各个角落。对于开发者而言,现在正是基于Gemma 3 270M构建下一代边缘AI应用的最佳时机。
Gemma 3 270M的出现标志着AI轻量化竞赛进入新阶段。其意义不仅在于参数压缩技术本身,更在于验证了"功能拆解"的技术路线——将复杂AI任务分解为多个专用小模型协同工作。这种范式转变对行业架构设计产生了深远影响,推动AI向更模块化、更专业化的方向发展。
【免费下载链接】gemma-3-270m-it-qat 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-it-qat
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







