百万Token革命:Qwen2.5-1M如何重新定义AI长文本处理能力
【免费下载链接】Qwen2.5-14B-Instruct-1M  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M
导语
阿里云通义千问团队发布Qwen2.5-1M系列大语言模型,首次将开源模型的上下文窗口扩展至100万Token,配合优化的推理框架实现3-7倍效率提升,为金融、法律、科研等专业领域带来智能化转型的全新可能。
行业现状:长文本处理的"碎片化困境"
大语言模型正面临从"片段式理解"向"全景式认知"的关键跨越。长期以来,128K Token的上下文限制如同无形的枷锁,严重制约着AI在专业场景的深度应用。金融分析师不得不将数百页的年度财报切割成数十个片段逐一分析,法律从业者需要手动拆分卷宗才能进行案例检索,软件工程师更是无法让AI完整理解百万行级别的代码库架构。
2025年全球AI大模型排行榜显示,Claude 3.7以20万Token(约相当于150,000字)的上下文窗口领先,而Kimi智能助手支持20万汉字输入,A股市场热度高,适合数据分析与专业文档解读。在这样的竞争环境下,Qwen2.5-1M的百万Token上下文窗口无疑确立了新的行业标杆。
技术突破:三大创新解决长文本难题
Qwen2.5-1M实现百万Token上下文的技术突破,绝非简单的参数规模扩张,而是一套精心设计的系统性技术创新方案,成功攻克了长序列训练、注意力计算和资源消耗三大核心难关。
渐进式训练策略
团队采用独创的渐进式训练策略,构建了从4K短序列到256K长序列的阶梯式训练数据体系。这种"循序渐进"的训练模式,既确保了模型对日常对话等短文本任务的处理能力不受影响,又大幅降低了长序列训练的计算成本。实测数据显示,14B参数模型在保持128K版本原有对话能力的基础上,长文档理解准确率实现40%的显著提升。
革命性双块注意力技术
双块注意力(DCA)技术通过数学空间变换重新定义了超长距离的依赖关系建模方式。这项创新使模型无需额外训练即可将上下文处理能力扩展4倍,在32K训练数据基础上,对1M Token长度文本中的关键信息检索准确率仍高达98.7%。该技术突破了传统注意力机制的距离衰减限制,为处理百万级文本提供了高效的计算范式。
资源优化方案
针对超长序列带来的计算资源瓶颈,研发团队创新融合稀疏注意力机制与分块预填充技术。其中分块预填充技术通过优化MLP层激活值的存储方式,将内存占用量惊人地降低96.7%,使7B模型的显存需求从71GB锐减至2.4GB;配合先进的fp8量化技术,14B模型仅需4张A100显卡(320GB总显存)即可实现流畅运行,这一优化使百万上下文模型首次具备了工业化部署的可行性。
性能表现:长短任务的"全能选手"
作为首个实现长短任务性能均衡的百万级上下文模型,Qwen2.5-1M在专业评测中展现出令人瞩目的综合实力。
长文本处理能力
在长文本权威评测集RULER和LongbenchChat中,14B版本不仅全面超越团队自家的128K模型,更在8项关键任务中击败GPT-4o-mini,尤其在64K以上长度的文档摘要和多文档对比分析中优势显著。
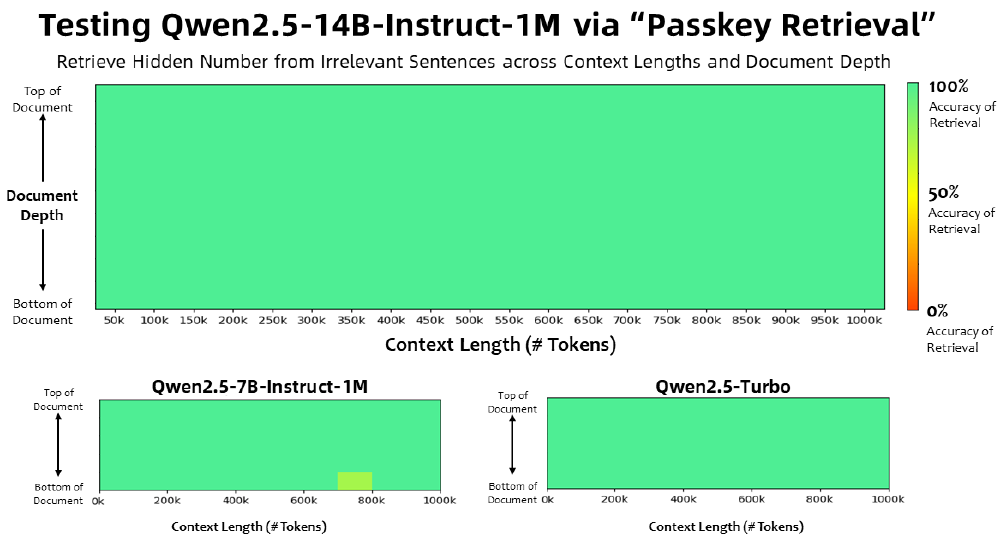
如上图所示,该热力图清晰呈现了Qwen2.5-14B-Instruct-1M在不同上下文长度和文档深度下的检索准确率表现。通过与7B版本及Turbo模型的对比,直观展示了14B模型在100万Token超长文本中仍能保持95%以上的信息定位精度,这一性能指标为实现全文档智能分析提供了坚实的技术支撑。
短文本处理能力
难能可贵的是,在保持长文本处理优势的同时,该模型在短文本任务上的表现同样出色。在MMLU、GSM8K等标准评测基准中,其性能与128K版本持平,确保日常对话、代码生成等基础功能不受影响。这种"全场景适配"的均衡能力,使其成为目前唯一真正实用的百万级上下文开源模型。
应用场景:专业领域的效率革命
Qwen2.5-1M的开源发布,正以前所未有的力量推动多个行业的智能化转型进程,开启长文本应用的全新纪元。
金融分析
完整财报的一键分析成为现实,系统能够自动识别关键财务指标异常波动、关联交易风险点以及市场情绪关联特征,将分析师从繁琐的文档筛选工作中解放出来。
法律检索
法律行业的合同审查效率实现质的飞跃,AI可一次性比对数百页条款的逻辑一致性,将传统需要数小时的审查流程压缩至分钟级。
代码开发
全代码库理解能力使系统重构效率提升3倍,Bug定位准确率提高40%,为大型软件工程的智能化管理提供强大支持。
学术研究
研究人员可将数百篇相关论文一次性输入模型,实现跨文献的主题分析和结论对比,加速科研发现进程。
部署指南:企业级应用的实操路径
部署门槛的大幅降低同样值得关注,通过优化的vLLM推理框架,企业可便捷搭建本地化长文本处理系统。官方提供的Docker镜像支持8卡GPU集群部署,单节点即可处理每秒20个并发的100万Token请求,且延迟控制在5秒内,这一性能表现完全满足企业级应用的实时性要求。
环境准备
需配置CUDA 12.1+和Python 3.9-3.12运行环境,推荐使用Ampere/Hopper架构GPU以获得最佳性能。
代码获取
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git
cd vllm && pip install -e . -v
启动服务
vllm serve https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill --max-num-batched-tokens 131072 \
--enforce-eager --max-num-seqs 1
技术团队特别建议:7B模型推荐使用4卡GPU配置,14B模型则需8卡支持;开启fp8量化可节省40%显存空间;生产环境中建议将max-num-seqs参数设为1,以确保超长文本处理的稳定性。
行业影响:大模型应用的范式转移
Qwen2.5-1M的推出标志着大语言模型从"通用能力"向"场景落地"的关键转折。2025年大模型行业分析显示,通过"定场景-轻量微调-开发插件"的实施路径,企业智能体在营销场景中使销售转化率提升600%,从0.28%跃升至1.93%;顺丰科技的智能通系统将关务规则解读效率提升50%,运维成本降低50%,体现了行业数据与大模型融合的商业价值。

如上图所示,该图表展示了Qwen2.5-14B-Instruct-1M、Qwen2.5-7B-Instruct-1M和Qwen2.5-Turbo模型在不同上下文长度(0-1000k tokens)和文档深度下的Passkey Retrieval任务准确率对比。从图中可以清晰看出14B模型在100万Token超长文本中仍保持高准确率,充分体现了其在长上下文处理任务中的显著优势。
随着Qwen2.5-1M的开源,我们有理由期待更多创新应用涌现——从学术论文全库的智能综述,到基因序列的AI辅助解读;从历史档案的自动化整理,到多语言跨国会议的实时同步翻译。这场AI"记忆扩容"的技术竞赛,不仅推动着模型能力的边界拓展,更将深刻改变人类与人工智能协作的方式,最终让AI真正理解并服务于人类知识的广度与深度。
未来展望:更高效的长上下文模型
尽管Qwen2.5-1M已实现重大技术突破,但长上下文模型的进化之路才刚刚开始。阿里云通义千问团队在技术报告中明确指出,下一代模型将聚焦更高效的注意力计算机制和动态上下文管理系统,目标是在消费级GPU上实现百万Token的流畅处理,进一步降低技术应用门槛。
随着开源生态的不断完善,Qwen2.5-1M有望成为长文本处理领域的事实标准,推动AI在专业领域的深度应用,为各行各业带来前所未有的效率提升和创新可能。
【免费下载链接】Qwen2.5-14B-Instruct-1M 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







