超详细Fluentd日志可视化实战:Grafana与Kibana集成指南
 项目地址: https://gitcode.com/gh_mirrors/fl/fluentd
项目地址: https://gitcode.com/gh_mirrors/fl/fluentd 你是否还在为分散的日志数据难以整合而烦恼?是否因缺乏直观的可视化工具导致问题排查效率低下?本文将带你一站式掌握Fluentd与Grafana、Kibana的无缝集成方案,通过实战案例和配置模板,让日志数据从杂乱无章到一目了然,彻底解决运维监控中的可视化难题。读完本文你将获得:Fluentd数据采集全流程配置、Grafana实时监控面板搭建、Kibana日志分析平台部署,以及三种工具协同工作的最佳实践。
Fluentd日志收集架构解析
Fluentd作为CNCF旗下的统一日志收集层(Unified Logging Layer),采用插件化架构设计,能够连接超过300种数据源与输出目的地。其核心优势在于轻量级部署(约40MB内存占用)、高可靠性(每秒处理1.4万条日志)和强大的数据流处理能力。
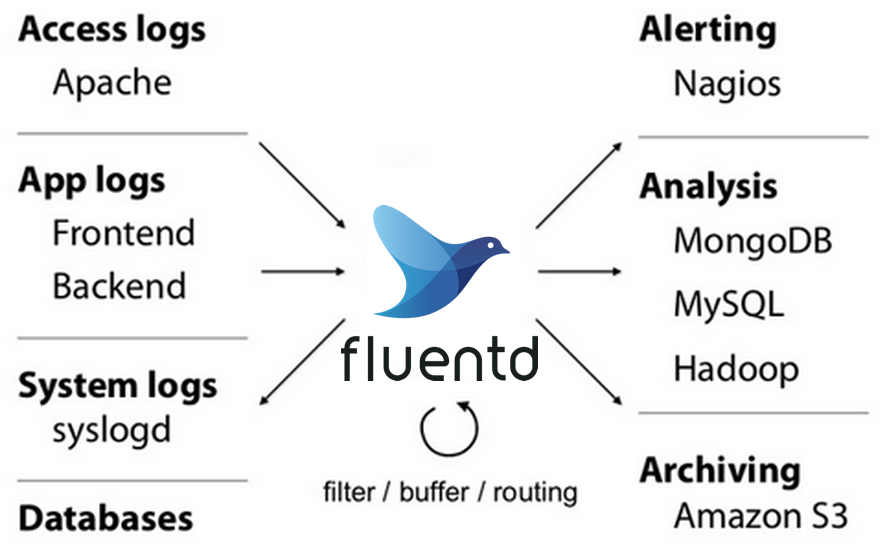
核心组件与工作流程
Fluentd的工作流程主要包含三个环节:
- 输入(Input):通过
in_tail、in_http等插件采集日志,如example/in_tail.conf配置文件所示 - 过滤(Filter):使用
filter_grep、filter_record_transformer等插件清洗数据,可参考lib/fluent/plugin/filter_grep.rb实现 - 输出(Output):通过
out_elasticsearch、out_prometheus等插件发送至存储系统,典型配置见example/out_forward.conf
集成Kibana实现日志可视化分析
Kibana作为Elastic Stack的可视化平台,与Fluentd配合可构建强大的日志检索分析系统。该方案特别适合需要深度日志挖掘和异常检测的场景。
部署架构与数据流
关键配置步骤
- 安装Elasticsearch输出插件
gem install fluent-plugin-elasticsearch
- 配置Fluentd输出至Elasticsearch
<match *.**>
@type elasticsearch
host es-server.example.com
port 9200
index_name fluentd-%Y%m%d
logstash_format true
flush_interval 5s
</match>
- Kibana索引模式配置
- 访问Kibana控制台:Management → Index Patterns
- 创建匹配模式:
fluentd-* - 时间字段选择:
@timestamp
常见问题解决方案
| 问题现象 | 可能原因 | 解决方法 |
|---|---|---|
| 索引创建失败 | 网络不通或权限不足 | 检查ES集群状态和Fluentd账号权限 |
| 日志时间偏差 | 时区配置错误 | 在Fluentd中添加localtime true参数 |
| 数据量过大 | 未设置索引生命周期 | 配置ES索引滚动策略 |
集成Grafana构建实时监控面板
Grafana以其丰富的可视化图表和多数据源支持,成为监控领域的事实标准。通过Fluentd的Prometheus插件,可将日志指标转化为实时监控面板,特别适合基础设施监控和业务指标追踪。
监控系统部署流程图
核心配置文件示例
Fluentd Prometheus输出配置:
<match metrics.**>
@type prometheus
metric_name_key metric
type gauge
<labels>
host ${hostname}
app ${tag_parts[1]}
</labels>
</match>
Grafana数据源配置:
- 类型选择:Prometheus
- URL地址:http://prometheus:9090
- 访问模式:Server
实用监控面板推荐
-
系统资源监控面板:
- CPU使用率:
rate(process_cpu_usage[5m]) - 内存占用:
process_resident_memory_bytes - 日志吞吐量:
fluentd_output_status_num_records_total
- CPU使用率:
-
业务指标监控面板:
- 接口响应时间:
sum(rate(http_request_duration_seconds_sum[5m])) - 错误率:
sum(rate(http_requests_total{status=~"5.."}[5m]))
- 接口响应时间:
三种工具协同工作最佳实践
在实际生产环境中,通常需要Fluentd、Grafana和Kibana协同工作,形成"日志采集-指标监控-日志分析"的完整解决方案。以下是经过验证的企业级部署架构:
多工具协同架构图
配置管理与维护建议
-
配置版本控制:将所有配置文件纳入Git管理,推荐参考CONTRIBUTING.md中的代码规范
-
性能优化策略:
- 使用缓冲插件buf_file防止数据丢失
- 配置适当的
flush_interval平衡实时性与性能 - 对高流量日志设置
num_threads多线程处理
-
高可用部署:
- 采用主从架构部署Fluentd实例
- Elasticsearch使用3节点以上集群
- Prometheus配置远程存储持久化数据
总结与进阶资源
通过本文介绍的方法,我们实现了Fluentd与Grafana、Kibana的无缝集成,构建了从日志采集到可视化分析的完整链路。这套方案已在国内外多家企业的生产环境中得到验证,能够有效提升运维效率和问题排查速度。
进阶学习资源
- 官方文档:Fluentd插件开发指南
- 配置模板库:example目录包含30+场景配置文件
- 社区插件:Fluentd插件市场提供更多集成方案
建议读者先从测试环境开始部署,逐步迁移至生产环境。如有任何问题,可通过GitHub Issues获取社区支持。立即行动起来,让你的日志数据发挥真正的价值!
如果你觉得本文有帮助,请点赞收藏并关注后续发布的《Fluentd性能调优实战》系列文章。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







