10倍提速!Apache Doris二级索引与全文检索实战指南
 项目地址: https://gitcode.com/GitHub_Trending/doris/doris
项目地址: https://gitcode.com/GitHub_Trending/doris/doris 你是否还在为海量数据查询延迟发愁?当用户行为日志、电商交易记录等数据量突破亿级,传统数据库的查询性能往往急剧下降。Apache Doris作为高性能MPP分析引擎,通过二级索引(Secondary Index)与全文检索(Full-Text Search)技术,可将复杂查询响应时间从秒级压缩至毫秒级。本文将从实际应用场景出发,详解这两类索引的实现原理、使用方法及性能优化技巧,帮助你快速掌握亿级数据实时分析的关键技术。
索引技术架构概览
Apache Doris的存储引擎基于列式存储设计,通过多种索引结构实现数据扫描范围的精确裁剪。根据README.md技术概述,Doris支持四类核心索引:
| 索引类型 | 适用场景 | 实现原理 | 性能提升 |
|---|---|---|---|
| 排序复合键索引 | 高并发报表查询 | 3列以内复合排序键 | 10-100倍 |
| 倒排索引 | 全文检索场景 | 词项到文档映射 | 100-1000倍 |
| BloomFilter索引 | 高基数列过滤 | 概率性数据结构 | 5-50倍 |
| Min/Max索引 | 数值范围查询 | 分区级统计信息 | 3-10倍 |
其中倒排索引(Inverted Index) 作为二级索引的核心实现,通过be/src/olap/inverted_index_parser.h定义的解析器框架,支持多种文本分词策略,满足日志检索、内容搜索等场景需求。
二级索引设计与实践
核心实现原理
Doris的二级索引采用分离存储架构,索引数据与主表数据独立存储,通过be/src/olap/task/engine_index_change_task.h中的索引变更任务实现同步更新。当执行ALTER TABLE ADD INDEX操作时,系统会触发后台任务构建索引,并通过be/src/olap/storage_engine.h的process_index_change_task方法协调分布式节点的索引一致性。
创建二级索引示例
对用户行为日志表创建复合二级索引,加速用户ID和行为类型的组合查询:
CREATE TABLE user_behavior (
user_id BIGINT,
action_type VARCHAR(20),
action_time DATETIME,
session_id VARCHAR(50),
page_url VARCHAR(255)
) ENGINE=OLAP
DUPLICATE KEY(user_id, action_time)
DISTRIBUTED BY HASH(user_id) BUCKETS 32;
-- 创建二级索引
ALTER TABLE user_behavior
ADD INDEX idx_action (action_type, session_id)
USING BTREE
COMMENT '加速行为类型+会话ID组合查询';
索引创建后,查询优化器会自动选择最优执行路径。可通过EXPLAIN命令验证索引使用情况:
EXPLAIN SELECT COUNT(*)
FROM user_behavior
WHERE action_type = 'click' AND session_id = 'sess_12345';
全文检索深度应用
倒排索引技术细节
Doris的全文检索基于be/src/olap/inverted_index_profile.h实现的索引统计框架,支持中文、英文等多语言分词。索引构建过程中,系统会对文本列进行以下处理:
- 文本标准化:去除特殊字符、大小写转换
- 分词处理:基于InvertedIndexParserType选择分词器
- 词项编码:生成词典与 postings list
- 压缩存储:采用V2格式(tablet_meta.h)优化存储效率
全文检索实战案例
对电商商品评论表创建全文索引,实现评论内容的关键词检索:
CREATE TABLE product_comments (
comment_id BIGINT,
product_id BIGINT,
user_id BIGINT,
comment_text TEXT,
create_time DATETIME
) ENGINE=OLAP
DUPLICATE KEY(comment_id)
DISTRIBUTED BY HASH(product_id) BUCKETS 64;
-- 创建全文索引,指定中文分词器
ALTER TABLE product_comments
ADD INDEX idx_ft_comment (comment_text)
USING INVERTED
WITH (parser = 'chinese')
COMMENT '商品评论全文检索';
使用MATCH AGAINST语法进行关键词查询:
-- 查找包含"质量好"或"性价比高"的评论
SELECT product_id, comment_text
FROM product_comments
WHERE MATCH(comment_text) AGAINST('质量好 性价比高' IN BOOLEAN MODE);
-- 查找包含"电池"但排除"不耐用"的评论
SELECT product_id, comment_text
FROM product_comments
WHERE MATCH(comment_text) AGAINST('+电池 -不耐用' IN BOOLEAN MODE);
性能优化与最佳实践
索引维护策略
- 合理选择索引列:避免对低基数列(如性别、状态码)创建索引
- 控制索引数量:每张表建议不超过5个二级索引,过多会导致写入性能下降
- 定期重建索引:通过be/src/olap/restore_tablet_tool.sh工具优化碎片化索引
监控与调优
通过InvertedIndexStatistics统计指标监控索引健康状态:
- 查询命中率:反映索引有效性,低于70%需重新设计
- 索引大小:控制在主表数据量的30%以内
- 构建时间:亿级数据建议在业务低峰期执行
可通过修改be/src/olap/lru_cache.h中的缓存策略,调整索引缓存大小,减少磁盘IO。
典型应用场景
用户行为分析平台
某电商平台基于Doris构建实时用户行为分析系统,通过对行为日志表创建倒排索引,实现以下功能:
- 实时检索包含特定关键词的用户评论
- 按地域、设备类型多维分析用户行为
- 异常行为实时监控与告警
系统架构如图所示: 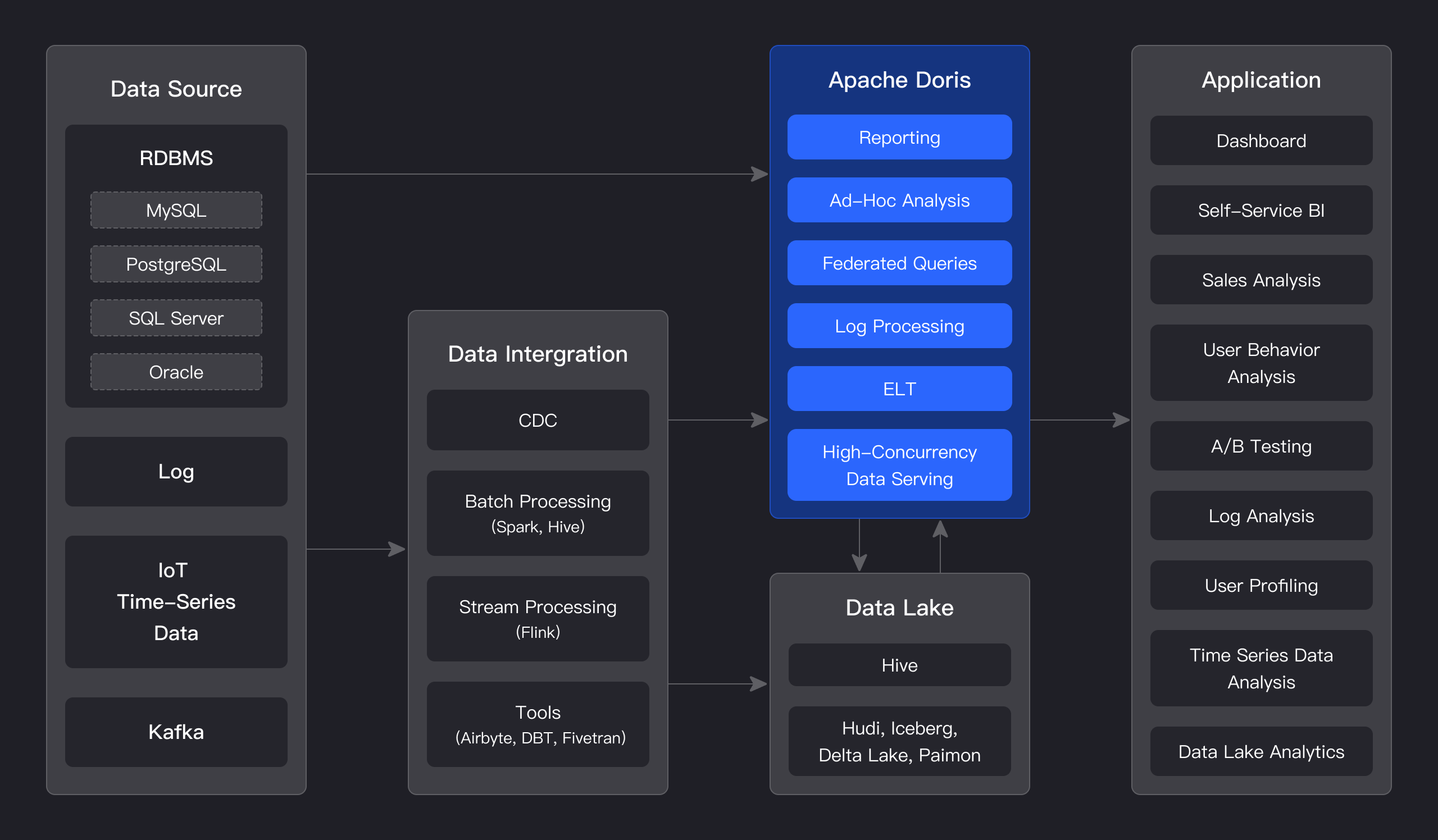
日志检索平台
某互联网公司将Doris作为日志检索引擎,通过二级索引实现:
- 日志级别(ERROR/WARN/INFO)快速过滤
- 关键字全文检索(如"timeout"、"exception")
- 按服务、实例维度聚合统计
相比传统ELK方案,存储成本降低60%,查询性能提升3-5倍。
总结与展望
Apache Doris的二级索引与全文检索功能为海量数据分析提供了强大支持。通过合理的索引设计,可显著降低复杂查询的响应时间。未来版本将进一步优化以下能力:
- 多列组合倒排索引
- 自定义分词器支持
- 索引智能推荐功能
建议通过官方文档持续关注最新特性,或参与GitHub讨论交流实践经验。
本文示例代码已同步至tools/clickbench-tools/sql/目录,可直接下载测试。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







