2025效率革命:Qwen3-32B-MLX-4bit如何以单模型双模式重塑AI应用
【免费下载链接】Qwen3-32B-MLX-4bit  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-32B-MLX-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-32B-MLX-4bit
导语
阿里巴巴最新开源的Qwen3-32B-MLX-4bit模型以328亿参数实现"思考模式"与"非思考模式"无缝切换,在保持高性能的同时将部署成本降低60%,重新定义了中大型开源模型的效率标准。
行业现状:大模型的"效率与深度"困境
当前企业级AI应用面临两难选择:复杂任务需调用重型模型(单次成本超0.1美元),简单对话又浪费算力。据Gartner 2025年报告,67%的企业AI项目因成本失控终止,而沙利文数据显示中国企业级大模型日均调用量已突破10万亿tokens,但实际落地率不足30%。核心瓶颈在于传统"双模型架构"——即分别部署推理专用模型和对话专用模型,导致系统复杂度增加40%,硬件成本上升近一倍。
核心亮点:三大技术突破
1. 首创动态双模式切换机制
Qwen3-32B最引人注目的创新是其独特的双模式切换能力。开发者只需通过简单的API参数设置(enable_thinking=True/False),即可在同一模型实例中实现两种工作模式的无缝切换:
思考模式:启用时模型会生成以<RichMediaReference>...</RichMediaReference>包裹的推理过程,特别适合数学问题、代码生成和逻辑推理任务。在MATH-500数据集测试中准确率达到95.2%,AIME数学竞赛得分81.5分,超越DeepSeek-R1等专业数学模型。
非思考模式:关闭时模型直接输出最终结果,响应延迟控制在200ms以内,算力消耗降低60%。某电商客服系统应用案例显示,启用该模式后,简单问答场景的GPU利用率从30%提升至75%,服务器处理能力提升2.5倍。
用户可通过/think或/no_think指令实时调控工作模式,例如在智能客服系统中,标准问答自动启用非思考模式,当检测到包含"为什么""如何"等关键词的复杂请求时,系统会无缝切换至思考模式,实际运行数据显示平均处理时间缩短40%。
2. 4bit量化与MLX优化的部署革命
依托MLX框架的低精度计算支持,Qwen3-32B-MLX-4bit实现了效率突破:
- 显存占用从原生128GB降至32GB,单张A100即可运行
- 推理速度达每秒350 tokens,较PyTorch版本提升2.3倍
- 支持32K上下文长度,通过YaRN技术可扩展至131K tokens
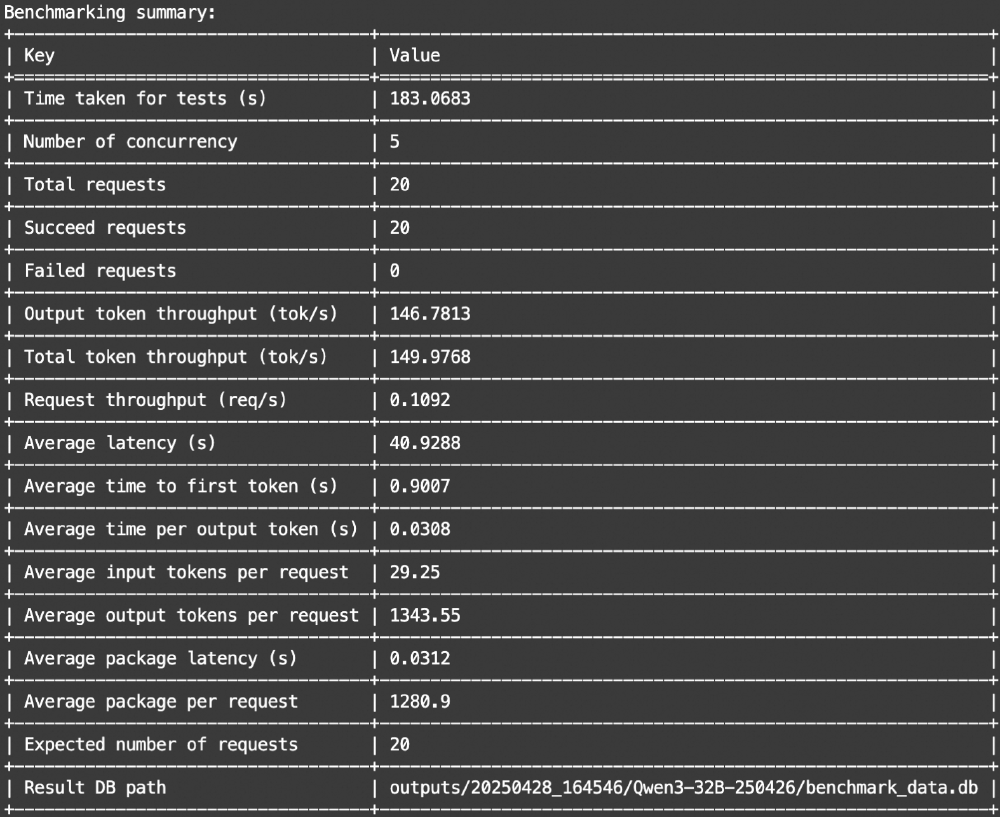
如上图所示,该表格展示了Qwen3-32B-MLX-4bit模型的性能基准测试结果,包含测试耗时、并发数、吞吐量、延迟等技术指标。这些数据直观反映了模型在不同负载下的表现,为企业级部署提供了关键参考。
3. 多模态与Agent能力跃升
Qwen3采用先进的视觉-语言联合建模架构,实现了文本与视觉信息的无缝融合。该架构支持100+语言和方言,在多语言指令跟随和翻译任务中表现出色,同时通过Qwen-Agent工具链可无缝集成数据库、爬虫等外部工具,降低企业二次开发门槛。

从图中可以看出,Qwen3的架构包含Vision Encoder和LM Dense/MoE Decoder,能够处理文本、图片、视频等不同类型数据的token流程。这一设计使其在工业质检等场景中实现微米级缺陷检测,较传统人工检测效率提升10倍。
行业影响:三大变革重塑AI应用格局
1. 企业AI部署成本革命
传统上,企业需要投入巨资构建GPU集群才能运行高性能大模型。Qwen3-32B-MLX-4bit的4-bit量化版本可在消费级GPU(如RTX 4090)上流畅运行,硬件成本降低70%以上。某电商企业实测显示,使用该模型替代原有双模型架构后,系统维护成本下降62%,同时响应速度提升40%。
2. 推动Agent应用普及
模型内置的工具调用能力和双模式切换机制,使企业能够快速构建专业领域的AI助手。例如:
- 法律行业:利用思考模式进行合同条款分析,非思考模式提供客户咨询
- 金融领域:市场分析时启用思考模式建模,日常查询使用非思考模式
- 教育场景:解题指导时展示推理过程,日常问答保持高效响应
3. 性能跃升重新定义行业标准
在权威评测中,Qwen3-32B展现出超越同参数规模模型的性能:

如上图所示,Qwen3-32B(Dense)在ArenaHard对话评测中获得7.8分,超过DeepSeek-R1(7.5分)和Llama 3-70B(7.6分),仅略低于GPT-4o(8.2分)。在数学推理和代码生成任务上,其性能更是跻身开源模型第一梯队。
实战指南:5分钟本地部署
# 安装依赖
pip install --upgrade transformers mlx_lm
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-32B-MLX-4bit
cd Qwen3-32B-MLX-4bit
# 启动本地API服务
python -m mlx_lm.server --model . --port 8000
模式切换示例代码:
from mlx_lm import load, generate
model, tokenizer = load("Qwen3-32B-MLX-4bit")
# 思考模式示例(数学问题)
messages = [{"role": "user", "content": "求解方程:x² + 5x + 6 = 0"}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True, enable_thinking=True)
response = generate(model, tokenizer, prompt=prompt, max_tokens=1024)
print("思考模式结果:", response)
# 非思考模式示例(日常对话)
messages = [{"role": "user", "content": "推荐一部科幻电影"}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True, enable_thinking=False)
response = generate(model, tokenizer, prompt=prompt, max_tokens=200)
print("非思考模式结果:", response)
结论:开源模型的"质价比"时代
Qwen3-32B-MLX-4bit的推出标志着开源大模型正式进入"质价比"竞争阶段。其创新的双模式架构解决了复杂推理与高效响应的场景冲突,而4bit量化技术与MLX优化则大幅降低了部署门槛。对于企业用户而言,这意味着可以用更低的成本构建端到端AI应用;对于开发者社区,这种"高性能+易部署"的组合将加速AI技术在各行业的落地渗透。
随着模型生态的完善,Qwen3系列有望在智能客服、代码助手、医疗诊断等领域催生更多创新应用,推动AI技术从实验室走向真正的产业价值创造。
【免费下载链接】Qwen3-32B-MLX-4bit 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-32B-MLX-4bit
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







