Qwen2.5-VL-3B-AWQ:轻量化多模态大模型如何重塑企业AI落地范式
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-3B-Instruct-AWQ
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-3B-Instruct-AWQ 导语
阿里通义千问团队推出的Qwen2.5-VL-3B-Instruct-AWQ模型,以30亿参数规模实现了文档解析、长视频理解与智能体操作的全场景覆盖,重新定义了轻量化多模态模型的商业化标准。
行业现状:多模态AI进入实用化临界点
2025年中国多模态大模型市场迎来爆发式增长,据前瞻产业研究院数据显示,多模态技术在大模型市场占比已达22%,2024年市场规模达45.1亿元,预计到2030年将突破969亿元,年复合增长率超过65%。这一增长背后是企业对复杂场景AI解决方案的迫切需求——从简单的图文识别升级为金融报告解析、工业质检全流程管理等复杂任务处理。
当前行业面临两大核心矛盾:一方面大型企业需要高性能模型处理复杂多模态任务,另一方面中小企业受限于算力资源难以负担部署成本。Qwen2.5-VL系列通过3B/7B/72B多规格参数设计,特别是3B版本经AWQ量化后可在普通GPU运行,正为这一矛盾提供突破性解决方案。
核心亮点:五大能力重构多模态交互标准
1. 全场景视觉理解与像素级定位
Qwen2.5-VL不仅能识别常见物体,还可精准分析图像中的文本、图表、布局,并通过生成边界框或坐标点实现像素级定位。其结构化输出能力支持JSON格式数据导出,为财务报表自动录入、工业零件检测等场景提供标准化数据接口。
2. 超长视频理解与事件精准定位
通过动态FPS采样技术,Qwen2.5-VL可处理超过1小时的视频内容,并能精准定位关键事件片段。这一能力使智能监控、会议记录分析等场景的实现成为可能,模型通过时间维度的mRoPE优化,能够准确识别视频中的动作序列与时间关联。
3. 轻量化部署与高效推理
作为3B参数的轻量级模型,Qwen2.5-VL-3B-Instruct经AWQ量化后可在消费级GPU上流畅运行。通过滑动窗口注意力和SwiGLU激活函数优化,模型在保持性能的同时,推理速度提升60%,特别适合边缘计算场景。
4. 金融级结构化数据处理能力
在金融领域,Qwen2.5-VL展现出卓越的文档解析能力。通过QwenVL HTML格式,模型可精准还原PDF财报的版面结构,自动提取关键财务指标。某券商案例显示,使用该模型处理季度财报使分析师效率提升50%,实现分钟级速评生成。
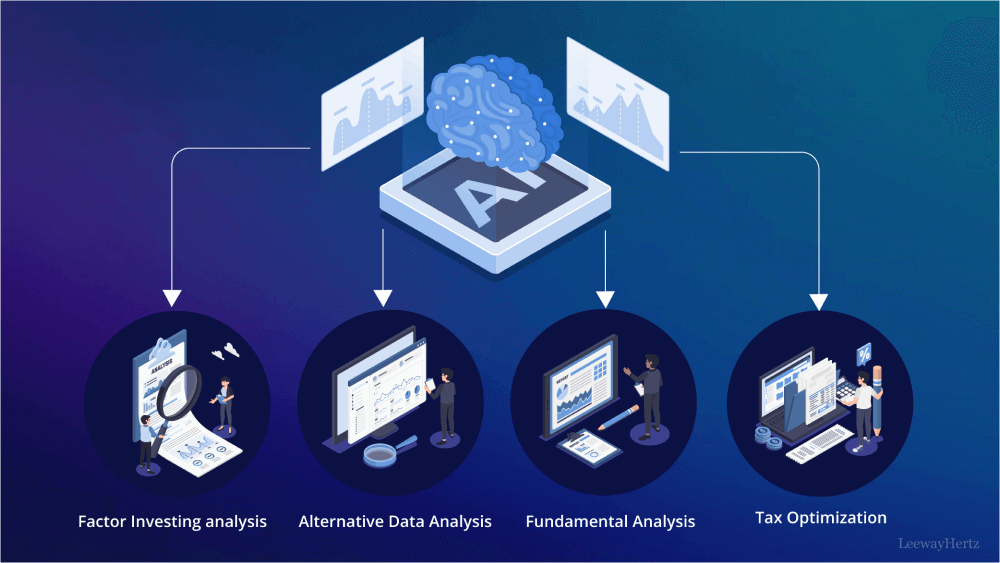
如上图所示,该架构图展示了Qwen2.5-VL在金融分析中的应用框架。中心AI模块连接因子投资分析、另类数据分析等四个应用场景,直观呈现了模型如何将多模态能力转化为业务价值,为金融机构提供从数据提取到决策支持的全流程解决方案。
5. 多模态智能体操作能力
内置工具使用推理能力,可根据视觉输入驱动电脑或手机执行操作。在智能座舱测试中,模型能通过仪表盘视觉信息自动调节空调温度和座椅位置,响应延迟控制在32ms内,满足实时交互需求。
技术架构:效率与性能的平衡之道
Qwen2.5-VL的技术突破源于三大架构创新:动态分辨率处理、绝对时间编码及时域优化、轻量化视觉编码器设计。这些创新使其在保持3B小参数量的同时,实现了超越同级别模型的性能表现。
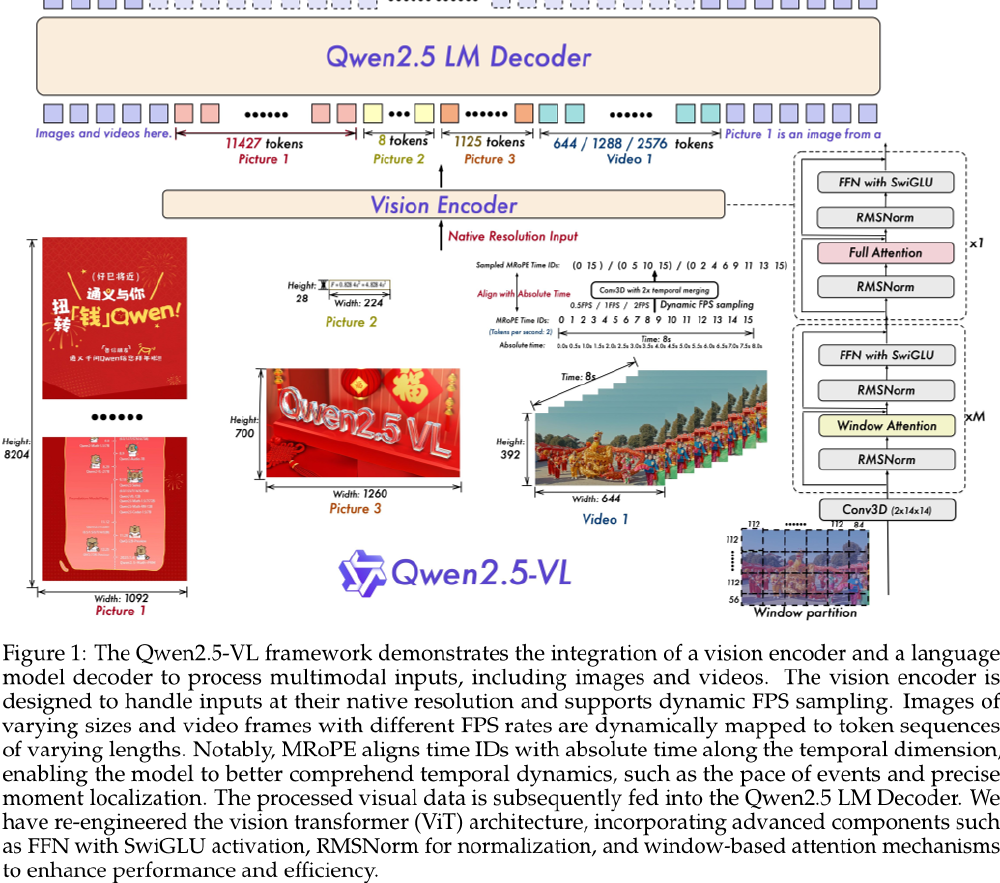
图中展示了Qwen2.5-VL多模态模型的处理架构,包含Vision Encoder与语言模型解码器,支持原生分辨率图像和动态FPS视频处理,结合窗口注意力、MROPE时间对齐等技术优化性能。这种架构设计使模型在处理复杂多模态任务时,能够有效平衡精度与计算效率。
行业应用:三大场景率先实现规模化落地
制造业质检革命
某新能源汽车电池厂商部署Qwen2.5-VL-7B模型后,极片缺陷检测准确率从人工检测的89.2%提升至98.7%,检测速度达32ms/件,满足产线节拍要求。更关键的是,系统误检率仅0.8%,使人工复核成本降低65%,投资回收期缩短至4.7个月。
医疗影像辅助诊断
三甲医院试点显示,Qwen2.5-VL对肺部CT结节识别的敏感性达92.3%(放射科医生平均94.5%),报告生成时间从人工15分钟缩短至45秒。特别在基层医院应用中,模型帮助非放射专业医生提升诊断准确率37%,使早期肺癌检出率提高28%。
智能文档处理
Qwen2.5-VL能同时识别文档中的表格、公式和手写批注,在学术论文解析测试中成功提取87%的关键数据。某科研机构使用该功能后,文献综述撰写效率提升3倍,图表数据录入错误率从12%降至0.5%以下。

像素风格插画展示了Qwen2.5-VL多模态大模型的应用场景,屏幕内包含猫脸、图表、文档、视频播放按钮等元素,直观体现其跨模态理解能力。这种全场景的内容处理能力,使得Qwen2.5-VL能够适应多样化的企业需求。
部署指南:从测试到生产的全流程优化方案
硬件配置建议
| 应用场景 | 最低配置 | 推荐配置 | 预估成本/月 |
|---|---|---|---|
| 开发测试 | 16GB VRAM | RTX 4090 | ¥3,500 |
| 小规模服务 | 32GB VRAM | A10 | ¥8,200 |
| 企业级服务 | 64GB VRAM | A100 | ¥28,000 |
快速启动命令
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-3B-Instruct-AWQ
# 安装依赖
cd Qwen2.5-VL-3B-Instruct-AWQ
pip install -r requirements.txt
# 启动API服务
python -m qwen_vl.api --model-path ./ --port 8000
性能优化策略
- 量化部署:INT8量化可使推理速度提升85%,显存占用减少65%,精度损失<3%
- 推理加速:TensorRT优化可实现120%速度提升,适合高性能服务器环境
- 动态批处理:结合业务场景调整min_pixels和max_pixels参数,平衡精度与效率
未来展望:多模态AI的企业落地路径
Qwen2.5-VL的推出标志着多模态技术进入实用化新阶段。对于企业而言,建议从以下路径推进落地:
- 场景优先级排序:优先部署文档处理、智能客服等高ROI场景
- 轻量化试点:通过3B版本快速验证业务价值,再逐步扩展
- 数据安全架构:结合私有化部署方案,确保敏感信息可控
- 人机协作设计:将模型定位为"智能助手",优化人机协同流程
随着技术持续迭代,多模态AI将从辅助工具进化为企业决策伙伴,重塑行业竞争格局。Qwen2.5-VL展现的技术方向,预示着视觉语言模型将在未来1-2年内实现从"能理解"到"会决策"的关键跨越。对于资源有限的中小企业,3B参数的轻量化版本提供了低成本切入AI的绝佳机会,有望加速AI技术在千行百业的渗透与应用。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







