GLM-4-9B-Chat-1M:100万上下文窗口开启大模型长文本处理新纪元
【免费下载链接】glm-4-9b-chat-1m  项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-1m
项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-1m
导语
智谱AI推出的GLM-4-9B-Chat-1M模型以其100万tokens(约200万中文字符)的超长上下文窗口,重新定义了开源大模型处理长文本的能力边界,为企业级文档分析、多语言处理和复杂知识管理提供了新工具。
行业现状:长文本处理成大模型竞争新焦点
2024年,大模型技术竞争已从参数规模转向实用能力,其中上下文窗口长度成为关键指标。根据Spherical Insights报告,全球大语言模型市场规模预计将从2024年的6.37亿美元增长至2035年的135.92亿美元,年复合增长率达32.08%。在这一快速增长的市场中,长文本处理能力正成为金融、法律、医疗等行业的核心需求。
企业级应用场景中,传统大模型受限于8K-128K的上下文长度,处理完整代码库、学术论文集或多语言合同等超长文本时需频繁截断,导致信息丢失和理解偏差。据Fortune Business Insights数据,2024年全球智能文档处理市场规模已达78.9亿美元,预计2032年将增长至666.8亿美元,年复合增长率30.1%,这一增长很大程度上依赖于大模型上下文能力的突破。
模型核心亮点:百万上下文与多语言能力的双重突破
1. 100万tokens超长上下文窗口
GLM-4-9B-Chat-1M支持100万tokens的上下文长度,是当前开源模型中的领先水平。在"大海捞针"实验中,该模型在100万tokens文本中定位关键信息的准确率表现优异:
如上图所示,该实验在100万tokens的文本中随机插入关键信息,GLM-4-9B-Chat-1M能以高准确率定位这些信息。这一能力使模型能完整处理长篇技术文档、法律合同和学术论文集,无需分段处理,显著提升了企业级文档分析的效率和准确性。
在LongBench-Chat长文本理解评测中,GLM-4-9B-Chat-1M也展现了竞争力,尤其在多轮对话和复杂推理任务上表现突出:
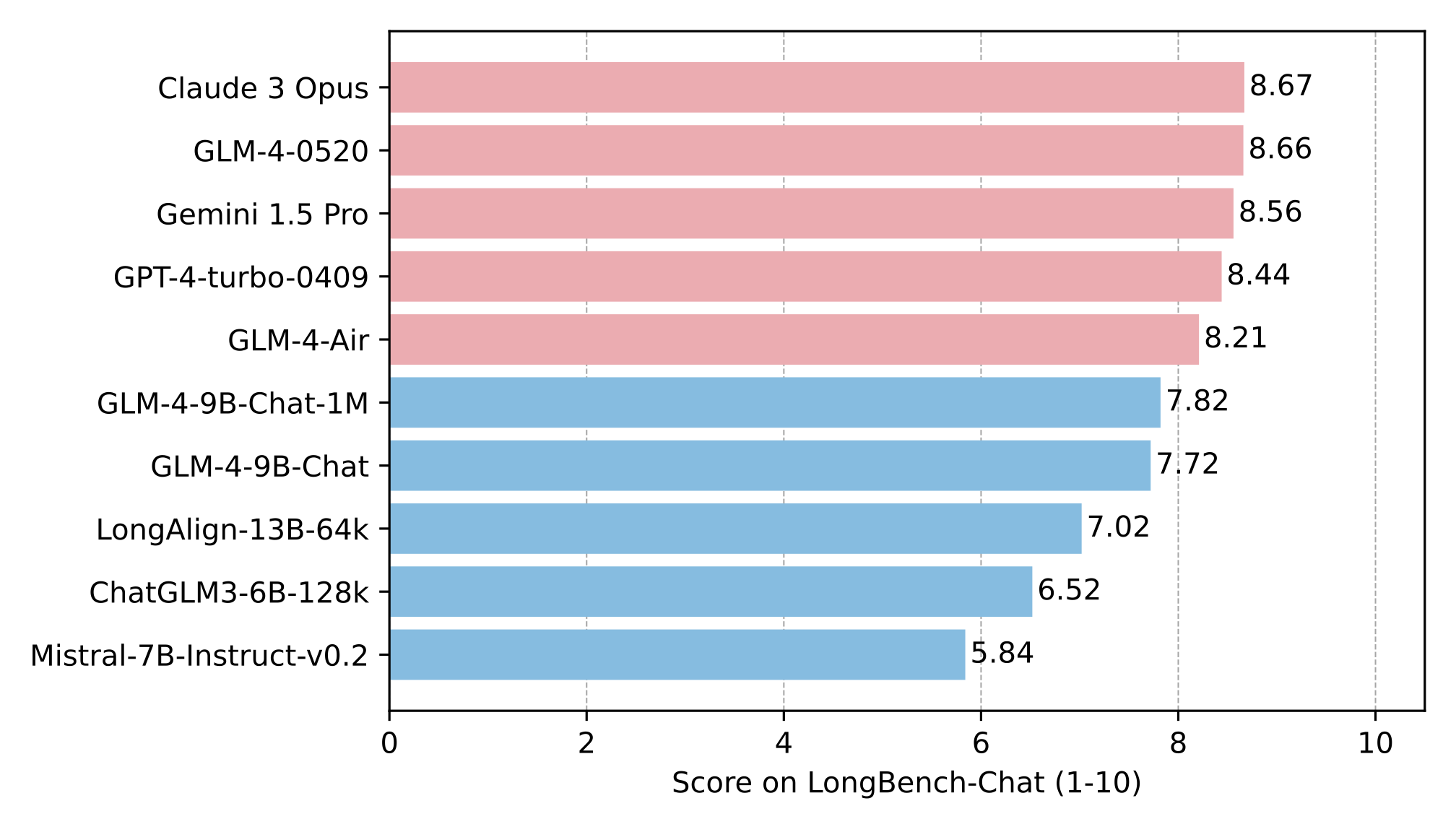
从图中可以看出,GLM-4-9B-Chat-1M在多个长文本任务中超越或持平同类模型,特别是在需要深度理解和跨段落推理的场景中优势明显。这为处理需要全局理解的文档(如多章节报告、代码库架构分析)提供了技术基础。
2. 26种语言支持与企业级功能
除超长上下文外,该模型还支持包括日语、韩语、德语在内的26种语言处理,满足跨国企业多语言文档处理需求。同时集成了代码执行、工具调用和网页浏览等高级功能,可直接应用于智能客服、自动化报告生成等场景。
模型提供两种推理方案:基于Transformers的基础推理和基于VLLM的高效推理,后者通过张量并行和PagedAttention技术优化,降低了长文本处理的显存占用。企业用户可通过以下代码快速部署:
# VLLM后端推理示例
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
model_name = "THUDM/glm-4-9b-chat-1m"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=4,
max_model_len=1048576,
trust_remote_code=True
)
行业影响:从技术突破到商业价值转化
1. 降低企业长文本处理成本
传统长文本处理需人工分段或使用RAG技术辅助,不仅增加系统复杂度,还可能引入检索偏差。GLM-4-9B-Chat-1M的百万上下文能力可直接处理500页以上的PDF文档,据行业测算,这将为金融分析、法律审查等场景减少30%-50%的预处理时间。
2. 开源模式推动行业创新
作为开源模型,GLM-4-9B-Chat-1M降低了企业级长文本处理技术的获取门槛。开发者可通过以下仓库获取完整代码和文档:
https://gitcode.com/zai-org/glm-4-9b-chat-1m
这一开源策略将加速长文本处理技术在中小企业中的普及,推动智能文档处理、自动化报告生成等应用场景的创新。
3. 多语言能力拓展跨境应用
26种语言支持使该模型能直接处理多语言合同、国际标准文档和跨国企业知识库。在全球化背景下,这一功能可减少企业90%以上的多语言文档翻译和校对工作量,显著提升跨境业务效率。
企业应用场景与实施建议
典型应用场景
- 法律行业:完整分析多语言合同条款,自动提取关键责任条款和风险点
- 金融领域:处理多年度财报数据,生成跨周期财务分析报告
- 研发部门:理解完整代码库架构,辅助代码重构和文档生成
- 学术研究:整合多篇相关论文,生成综述报告和研究脉络分析
实施建议
- 硬件配置:建议使用4×NVIDIA A100/H100 GPU配置,配合≥256GB内存以支持100万tokens推理
- 部署优化:优先采用VLLM后端并启用KV Cache量化,可将显存占用降低40%
- 数据安全:对于敏感文档,建议采用本地部署模式,避免数据上传云端
- 应用开发:结合RAG技术构建混合系统,利用模型长上下文能力处理核心文档,同时通过检索补充实时数据
结论与展望
GLM-4-9B-Chat-1M的推出标志着开源大模型正式进入百万上下文时代。其超长文本处理能力和多语言支持,为企业级智能文档处理提供了新的技术选择。随着模型优化和硬件成本下降,预计未来1-2年内,百万上下文能力将成为企业级大模型的标配功能。
对于行业用户而言,现在是评估长文本处理需求、规划模型部署策略的关键时期。建议重点关注金融分析、法律审查等文档密集型场景,通过POC验证GLM-4-9B-Chat-1M等长上下文模型的实际业务价值,为即将到来的智能文档处理浪潮做好准备。
随着技术的持续演进,我们有理由相信,大模型的上下文能力将继续突破,最终实现"无限上下文"的理想状态,为企业知识管理和决策支持带来革命性变化。
【免费下载链接】glm-4-9b-chat-1m 项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-1m
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







