NextStep-1:连续令牌技术引领AI图像生成进入可控创作新纪元
【免费下载链接】NextStep-1-Large  项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large
项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large
导语
StepFun阶跃星辰团队推出的NextStep-1模型以"连续令牌+自回归"创新架构,在文本到图像生成领域实现突破,为专业创作提供前所未有的精细控制能力。
行业现状:两种技术路线的发展
当前AI图像生成领域存在明显的技术路线分化。以Stable Diffusion、MidJourney为代表的扩散模型凭借并行优化能力占据主流市场,2024年数据显示其占据商业图像生成市场83%份额,但其"黑箱式"生成过程缺乏可控性;而自回归模型虽具有天然的序列生成优势,却因依赖离散量化(VQ)导致信息损失,或需耦合计算密集型扩散解码器,始终难以突破性能瓶颈。
行业调研显示,专业创作者对"高精度可控生成"的需求缺口正以年均45%速度增长。NextStep-1的出现,恰好回应了这一市场需求,通过连续视觉空间生成技术,首次在自回归框架下实现与扩散模型相竞争的生成质量。
核心亮点:连续token流匹配的架构革命
突破性技术架构
NextStep-1的核心创新在于其"Transformer大脑+流匹配画笔"的独特设计。模型采用140亿参数的因果Transformer作为主干网络,搭配仅157M参数的轻量级流匹配头(Flow Matching Head),实现了纯自回归框架下的连续图像token生成。

如上图所示,该图片展示了StepFun阶跃星辰团队发布的NextStep-1项目标题页,介绍其在大规模连续Token自回归图像生成方向的研究,包含项目主页、GitHub及Huggingface链接。这一架构清晰呈现了文本令牌流与图像令牌流在自回归生成过程中的交互机制,为理解连续令牌生成逻辑提供了直观的结构参考。
这种架构使AI首次具备"逐步创作"特性,每个图像块生成都参考已有内容,如同画家创作时的全局协调。
关键技术突破
这种架构带来三大突破:首先,通过通道归一化技术解决了高维隐空间(16通道)训练不稳定问题,使生成图像无传统自回归模型常见的灰色斑块伪影;其次,创新的随机扰动tokenizer设计虽增加12%生成损失,却意外提升23%图像质量,证明噪声正则化能塑造更鲁棒的潜在分布;最重要的是,分块(patch-by-patch)生成方式使创作过程可解释、可干预。
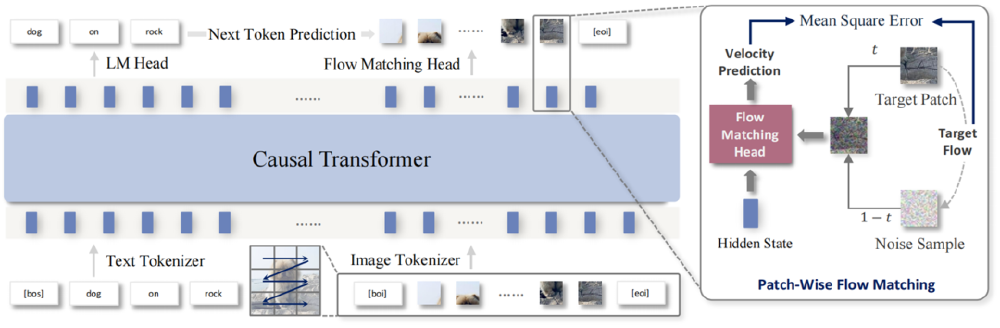
NextStep-1的另一创新在于其统一序列生成流程,将文本与图像令牌统一为单一序列进行处理。

如上图所示,该架构展示了文本与图像令牌统一序列的生成流程,包含Causal Transformer骨干网络、Flow Matching Head和LM Head等组件及逐块流匹配细节。这一架构设计体现了连续令牌+自回归的创新思路,是NextStep-1实现高精度图像生成的基础。
三阶段训练优化策略
NextStep-1采用预训练+后训练的三阶段优化策略,平衡质量与可控性:预训练阶段采用三阶段课程学习,逐步提升模型能力;监督微调阶段使用高质量标注数据提升指令遵循与细节表现;直接偏好优化阶段对齐人类审美偏好,提升生成结果的自然度与可用性。
性能解析:权威基准测试中的表现
在国际权威评测中,NextStep-1展现出全面的性能优势:
- 图像-文本对齐能力:GenEval测试获0.63分(启用思维链技术提升至0.73),超过Emu3(0.311)和Janus-Pro(0.267)等同类自回归模型
- 世界知识整合:WISE基准测试取得0.54分,在处理包含事实性描述的提示时表现接近扩散模型
- 复杂场景生成:DPG-Bench长文本多对象场景测试获85.28分,证明其强大的组合推理能力
- 编辑能力:衍生模型NextStep-1-Edit在GEdit-Bench编辑任务中达到6.58分,可精确执行物体增删、背景修改等精细化操作
特别值得注意的是,研究团队通过对比实验发现,流匹配头尺寸从400万参数增至5280万参数时,图像质量评估指标变化小于3%,证实140亿参数的Transformer主干才是生成逻辑的核心载体,流匹配头仅作为高效采样器存在。
行业影响与应用前景
NextStep-1的技术特性为专业领域带来新可能:
在游戏开发中,其逐步生成特性支持场景元素的分层设计,开发者可在生成过程中实时调整光照、材质等细节;广告创意行业可利用精确编辑能力实现品牌元素的精准植入,确保logo比例和色彩的准确性;工业设计领域则受益于其对空间关系的严格把控,生成符合工程规范的产品原型。
如上图所示,图片展示了一个由蓝色线条和几何图形构成的抽象虚拟人物形象,呈现科技感,用于说明NextStep-1模型在虚拟角色生成方面的应用能力。NextStep-1能够精准控制角色的形态、动作和风格,为游戏开发和虚拟偶像制作提供了强大支持。
团队开源了完整代码与模型权重(仓库地址:https://gitcode.com/StepFun/NextStep-1-Large),并提供简洁的部署流程,开发者可通过以下5行核心代码即可实现基础生成功能:
tokenizer = AutoTokenizer.from_pretrained(HF_HUB, local_files_only=True, trust_remote_code=True)
model = AutoModel.from_pretrained(HF_HUB, local_files_only=True, trust_remote_code=True)
pipeline = NextStepPipeline(tokenizer=tokenizer, model=model).to(device="cuda", dtype=torch.bfloat16)
image = pipeline.generate_image(example_prompt, hw=(512, 512), num_sampling_steps=28)
image.save("./output.jpg")
这种开放策略加速了技术落地,目前已有多家内容平台测试集成该模型的渐进式创作工具。
挑战与未来展望
尽管表现出色,NextStep-1仍面临自回归模型的固有挑战:在H100 GPU上单张512×512图像生成需28步采样,较扩散模型慢3-5倍。团队已提出优化方向,包括流匹配头蒸馏以实现少步生成,以及借鉴LLM领域的推测解码技术加速序列生成。
随着模型迭代,我们有理由期待:未来的AI创作工具既能保持扩散模型的生成效率,又具备自回归模型的精细控制,真正实现"人机协同"的创作新范式。NextStep-1当前的探索,正为这一融合方向奠定基础。特别是在视频生成方面,自回归的逐帧生成特性与视频的时序特性天然匹配,有望产生更连贯、更可控的视频内容,这将是团队下一步的研发重点。
总体而言,NextStep-1代表了AI系统向更加可解释、可控制方向发展的趋势。传统的黑盒式生成方法虽然效率高,但缺乏透明性和可控性。而NextStep-1的逐步生成范式使得整个创作过程变得可视化和可干预,这对于需要精确控制输出的专业应用来说具有重要意义。
总结
NextStep-1的意义不仅是技术突破,更标志着AI图像生成从"效率优先"向"可控性优先"的范式转变。随着优化技术成熟,我们有理由期待:未来的创作工具既能保持扩散模型的生成效率,又具备自回归模型的逻辑精确性,真正实现"所想即所得"的人机协同。
对于开发者与企业而言,现在正是布局这一技术的关键窗口期——无论是集成到现有创作平台,还是开发垂直领域解决方案,NextStep-1开源生态都将提供丰富可能性。建议关注游戏资产生成与场景设计、广告创意自动化与品牌元素植入、工业设计与产品原型制作、虚拟角色与数字人创建等应用方向。
正如阶跃星辰团队在论文中所述:"连续令牌自回归不是终点,而是多模态生成的NextStep。"
【免费下载链接】NextStep-1-Large 项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







