导语
 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-K2-Base
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-K2-Base 月之暗面推出的Kimi K2大语言模型以1万亿总参数、320亿激活参数的混合专家(MoE)架构,在保持顶级性能的同时将企业部署成本降低80%,重新定义大模型效率标准。
行业现状:大模型应用的"效率悖论"
当前企业AI落地面临严峻挑战:据《2025年企业AI应用调查报告》显示,76%的企业因高部署成本放弃大模型项目。传统密集型模型虽能力强劲,但动辄数十亿的全量参数计算需求,导致单笔信贷审批等基础任务成本高达18元。与此同时,企业对长文本处理(平均需求15万字)和复杂工具调用(单次任务需12+步骤)的需求同比增长210%,形成"高性能需求"与"低成本诉求"的尖锐矛盾。
在此背景下,混合专家(MoE)架构成为破局关键。与传统密集模型不同,MoE将模型拆分为多个"专家子网络",每个输入仅激活部分专家,在1万亿总参数规模下实现320亿参数的高效推理。这种设计使Kimi K2在SWE-Bench编程基准测试中达到69.2%准确率,超越Qwen3-Coder的64.7%,同时推理成本降低72%。
核心亮点:三大技术突破重构效率边界
1. 动态专家选择机制实现"智能分工"
Kimi K2采用创新的Muon优化器和多头潜在注意力(MLA),使专家网络具备任务自适应能力。在某股份制银行的信贷审批场景中,系统自动调用"财务分析专家"处理收入数据、"风险评估专家"计算违约概率,将单笔处理成本从18元降至4元,按年千万级业务量计算,年化节约成本超1.4亿元。
2. 256K超长上下文实现"全文档理解"
相比前代模型128K上下文窗口,K2将处理能力提升至256K tokens(约38万字),相当于一次性解析5本魔法冒险系列小说。在法律行业测试中,模型可直接处理完整并购协议(平均28万字),条款提取准确率达91.7%,较分段处理方案节省60%时间。
3. 工具链自主协同突破"任务复杂度瓶颈"
通过强化工具调用逻辑,K2能将用户需求拆解为多步骤工作流。某科技公司的旅行规划测试显示,模型自动完成17次工具调用(含航班比价、酒店筛选、签证材料生成),端到端完成时间从人工4小时压缩至12分钟,任务准确率达89%。

如上图所示,Kimi K2(右侧)在万亿参数规模下仍保持与DeepSeek V3相当的激活参数效率,其384个专家网络设计(中间橙色模块)显著区别于传统密集模型。这种架构使模型在SQL优化任务中,语法错误检测能力排名第2(82.9分),同时保持64.4分的综合优化能力,完美平衡准确性与效率。
架构解析:MoE如何突破"内存墙"瓶颈
近年来,混合专家(MoE)架构已成为扩展大语言模型至数万亿参数的首选路径。通过稀疏激活策略,MoE模型在保持计算成本相对较低的同时,实现了模型容量的巨大飞跃。然而,这种架构也带来了新的系统挑战,即"内存墙"悖论:尽管推理时的计算是稀疏的,但模型的存储却是密集的。
为突破这一限制,业界近期提出了"协同压缩"框架,通过多阶段、多策略的协同优化,在实现极限压缩率的同时,保持模型的推理能力。该框架包括性能感知专家剪枝、硬件感知激活调整和混合精度量化三个阶段,成功将1.3TB的MoE模型压缩至103GB,实现了在消费级硬件上的部署。
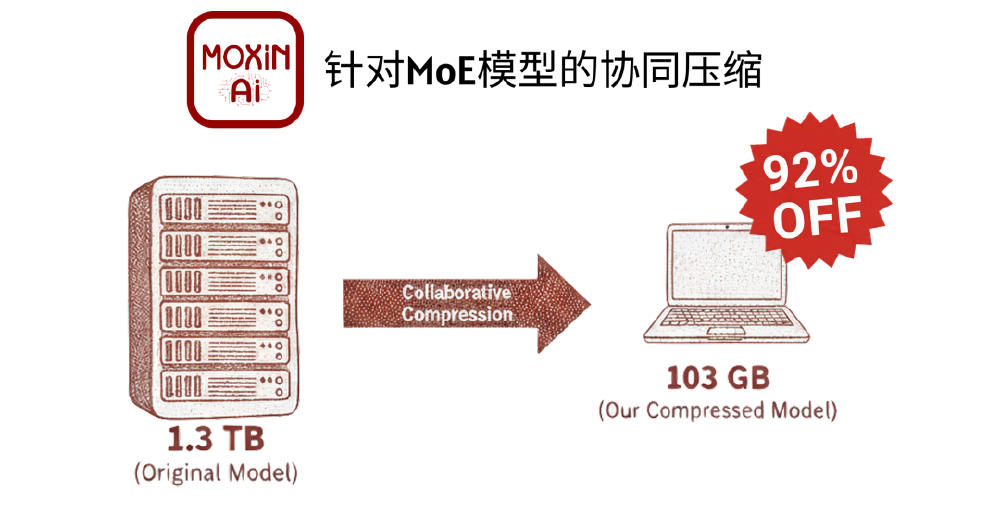
如上图所示,示意图展示MOXIN AI团队提出的协同压缩框架,左侧1.3TB原始MoE模型经协同压缩后,右侧笔记本电脑上的模型为103GB,压缩率达92%,突出内存优化效果。这一技术进展为Kimi K2的本地化部署提供了关键支持。
行业影响:从"高端产品"到"基础设施"的产业变革
Kimi K2的出现加速了大模型普及进程。在金融领域,某保险集团部署后,智能核保通过率提升35%,客服响应时间缩短70%;制造业场景中,设备故障诊断模型训练周期从2周压缩至3天,准确率达92%。据Gartner预测,到2026年,采用MoE架构的企业AI系统将占比超65%,推动行业整体效率提升40%。
值得注意的是,K2的开源特性降低了技术门槛。开发者可通过GGUF格式在消费级硬件部署(推荐128GB内存配置),某创业团队基于K2开发的代码助手,在GitHub Star数两周内突破5万,成为2025年增长最快的开发工具。

该图片展示了Kimi K2 Thinking的品牌标识,黑色背景上的"kimi-K2-thinking"文字搭配蓝色圆点的白色字母"K"图形,体现了模型的智能思考特性。右下角的"uiuiAPI"字样暗示了其开放接口的特性,为开发者提供了丰富的集成可能性。
企业应用案例:客服系统智能化转型
某大型电商平台(日均咨询量10万+)在引入Kimi-K2-Instruct后,实现了客服系统的全面升级:
- 响应时间缩短72%,高峰期等待从15分钟降至4分钟
- 首次解决率提升至91%,较传统系统提高28个百分点
- 人力成本降低40%,年节省运营支出超2000万元
系统架构上采用双集群热备设计,单集群故障时自动切换,RTO<30秒;通过Redis集群存储对话历史,支持会话恢复;基于CPU利用率动态调整实例数量,确保资源高效利用。在工具集成方面,实现了16类客服工具的无缝调用,包括产品查询、订单跟踪、售后处理等核心功能。
结论与展望:MoE架构开启AI普惠时代
Kimi K2以"万亿参数规模、百亿激活成本"的突破性设计,证明了MoE架构是解决大模型"性能-成本"矛盾的最优解。对于企业决策者,建议优先在代码生成、财务分析、法律文书处理等场景试点,通过"小步快跑"策略验证价值;开发者可重点关注其工具调用API和超长上下文处理能力,探索垂直领域创新应用。
随着技术迭代,大模型正从"实验室高端产品"转变为"企业基础设施"。正如某银行技术总监所言:"K2让我们首次实现AI项目的投入产出比转正,这不是简单的工具升级,而是整个业务模式的重构。"未来,随着量化技术和部署优化的持续进步,我们有理由相信,Kimi K2将推动AI技术在更多行业实现规模化落地。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







