DeepSeek-V3.2-Exp震撼发布:DSA稀疏注意力机制引领大模型效率革命
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp 导语
DeepSeek-V3.2-Exp实验性模型横空出世,首创DeepSeek Sparse Attention(DSA)稀疏注意力机制,在保持与V3.1-Terminus同等性能的前提下,实现长文本处理效率跃升,推理成本直降50%,重新定义开源大模型性价比标准。
行业现状:大模型进入"效率竞争"新阶段
2025年,AI大模型行业正从"参数竞赛"转向"效率比拼"。据科技日报报道,深度求索自去年5月发布DeepSeek-V2以来,以每百万Tokens仅1元的推理成本引发行业震动,促使字节、阿里、百度等企业跟进降价。这种"花小钱办大事"的模式,打破了大模型"唯算力论"的发展逻辑——用2048块H800显卡、557.6万美元训练成本,实现了传统万卡集群才能达到的性能水平。
OpenAI创始成员安德烈·卡帕西评价,DeepSeek系列让"有限算力预算内进行模型预训练"成为可能。行业专家预测,2025年大模型行业将进一步收敛,计算效率与推理成本控制能力将成为核心竞争力。
核心亮点:DSA机制引领效率革命
1. DeepSeek Sparse Attention稀疏技术突破
DeepSeek-V3.2-Exp最显著的创新是引入DeepSeek Sparse Attention(DSA)稀疏注意力机制。这一技术通过细粒度注意力优化,在几乎不影响输出质量的前提下,实现了长文本处理效率的大幅提升。

如上图所示,Prefilling(左图)和Decoding(右图)场景下,V3.2-Exp的推理成本均显著低于V3.1-Terminus版本。这种效率提升直接转化为API服务价格下调50%以上,使开发者调用成本大幅降低。
2. 性能与效率的平衡艺术
为验证DSA机制的实际效果,深度求索严格对齐了V3.2-Exp与V3.1-Terminus的训练设置。在各领域公开评测集上,新版本表现与前代基本持平,证明效率提升并未以牺牲质量为代价。
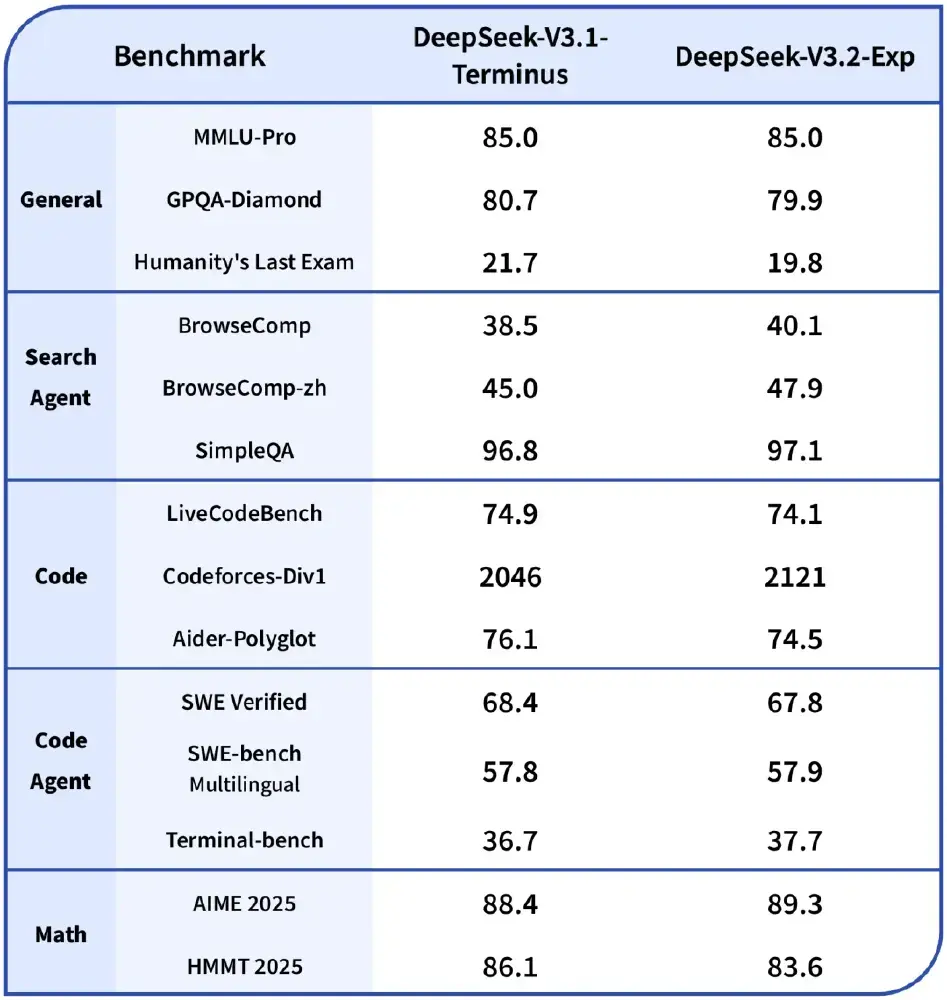
从图中可以看出,在MMLU-Pro、BrowseComp、LiveCodeBench等12项基准测试中,V3.2-Exp与V3.1-Terminus性能差异小于2%,但推理效率提升显著。这种"零性能损失"的优化,体现了深度求索在模型架构设计上的深厚积累。
3. 全栈开源与生态共建
DeepSeek-V3.2-Exp延续了深度求索的开源策略,不仅开放模型权重,还公开了TileLang与CUDA算子实现。研究性实验推荐使用TileLang版本以方便调试,生产环境则可切换至优化后的CUDA版本,这种灵活设计加速了社区二次开发。
企业应用:从技术突破到商业价值
开源大模型的商业化落地正加速推进。致远互联作为首批采用DeepSeek技术的企业案例,入选中国信通院"开源大模型+"典型案例。其AI-COP数智化协同运营平台整合DeepSeek等主流模型,打造了合同风险助理、企业智能问数等垂直场景智能体。
在大规模日志分析场景中,某自动驾驶企业采用DeepSeek-V3.2-Exp的DSA架构,通过分层存储与动态采样技术,将日均50TB日志的存储成本从每月15,000美元降至3,200美元,查询延迟从12ms压缩至3ms,实现了效率与成本的双重优化。
行业影响与趋势前瞻
DeepSeek-V3.2-Exp的发布标志着开源大模型进入"精细化运营"阶段。其带来的三大趋势值得关注:
-
技术普惠加速:50%的API降价使中小企业首次具备大规模应用AI的能力,预计2025年下半年将涌现大量垂直行业的创新应用。
-
硬件依赖降低:DSA机制证明通过算法优化可大幅提升硬件利用率,这将缓解企业对高端GPU的依赖,推动AI基础设施的多元化发展。
-
生态竞争加剧:随着模型性能趋同,效率优化、工具链完整性和场景适配能力将成为开源项目竞争的新焦点。
结论/前瞻
DeepSeek-V3.2-Exp以"稀疏注意力+全栈开源+商业友好协议"的组合拳,为企业级AI应用提供了新选择。对于技术决策者,建议重点关注其长文本处理效率提升带来的知识库构建、文档理解等场景突破;开发者可利用开源算子加速自定义优化;业务部门则可借助API成本下降契机,重新评估AI投资回报模型。
在AI技术日益同质化的今天,效率创新正成为差异化竞争的关键。DeepSeek-V3.2-Exp不仅是一次技术迭代,更代表着开源大模型从实验室走向产业深水区的关键一步。
要体验该模型,可通过以下仓库地址获取:https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







