GLM-4-9B-Chat-1M:国产开源大模型的里程碑突破
【免费下载链接】glm-4-9b-chat-1m-hf  项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
导语
智谱AI推出的GLM-4-9B-Chat-1M开源大模型,以90亿参数实现1M上下文(约200万字中文)处理能力,综合性能超越Llama-3-8B,重新定义了轻量化模型的技术边界。
行业现状:大模型进入"效率竞赛"新阶段
2024年中国大语言模型市场规模达294.16亿元,预计2026年突破700亿元。当前行业正从"参数军备竞赛"转向"场景落地效率"竞争,企业级应用更关注模型的部署成本与实用功能。据《2024大语言模型能力测评报告》显示,上下文长度、工具调用能力和多语言支持已成为企业选型的三大核心指标。
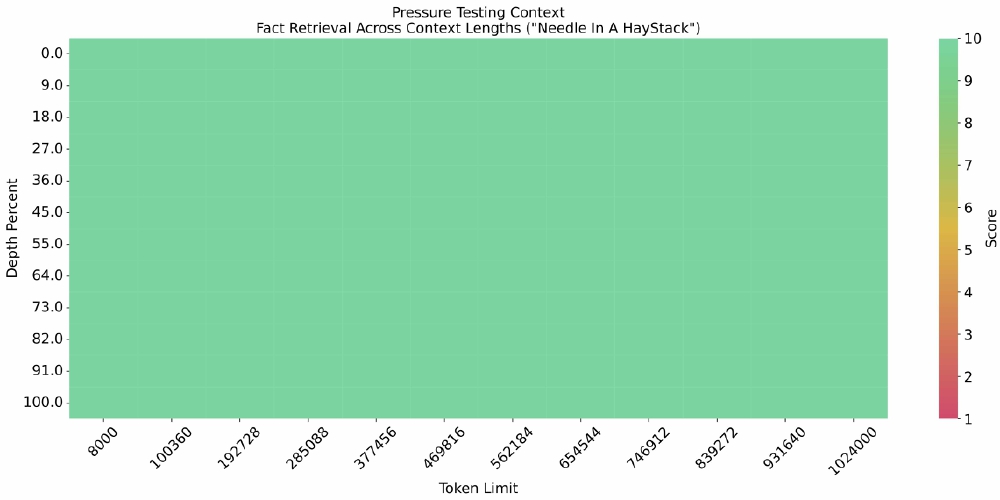
如上图所示,该热力图展示了GLM-4-9B-Chat-1M在1M上下文长度中的"大海捞针"测试结果,关键信息提取准确率接近满分。这一特性使其能够处理完整的学术论文、企业年报等长文档,为知识管理系统提供强大支撑。
核心亮点:重新定义90亿参数模型能力边界
1. 全面超越的基础性能
在标准测评中,GLM-4-9B-Chat展现显著优势:MMLU(多任务语言理解)达72.4分,超越Llama-3-8B的68.4分;C-Eval中文权威测评75.6分,数学推理MATH数据集得分50.6分,均为开源模型中的佼佼者。其训练数据量达10T高质量多语言数据,是ChatGLM3-6B的3倍以上。
2. 1M超长上下文处理
模型支持1M tokens上下文窗口(约200万字中文),相当于同时处理2本《红楼梦》或125篇学术论文。通过动态扩缩容技术优化,可在单卡24G显存环境运行,大幅降低企业部署门槛。
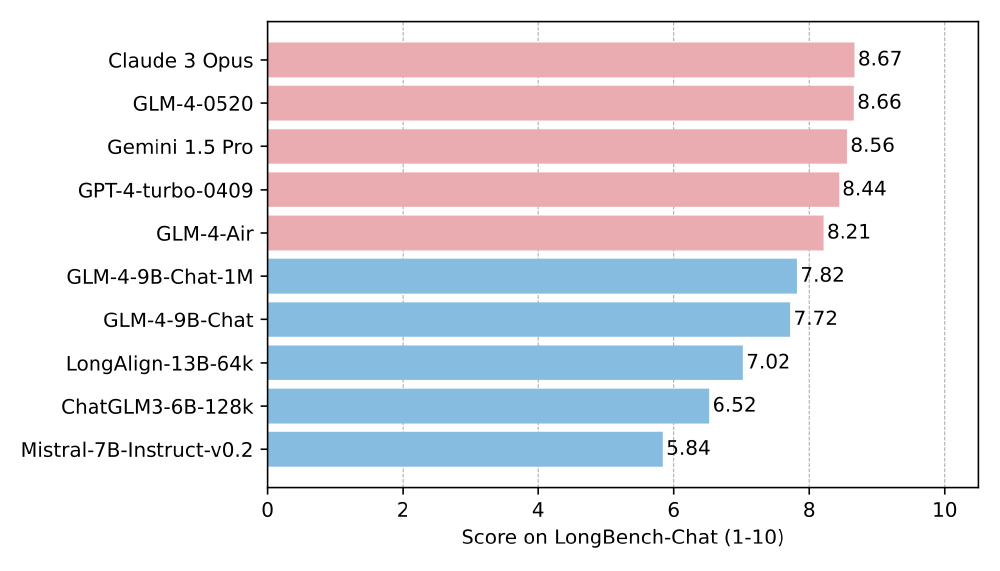
从图中可以看出,在LongBench-Chat长文本测评中,GLM-4-9B-Chat-1M以7.82分领先同类模型。其在摘要生成、多轮对话等8项任务中位列前三,7项超越Llama-3-8B,验证了长文本场景的实用价值。
3. 多模态与工具调用生态
- 26种语言支持:词表扩充至150k,编码效率提升30%,覆盖中日韩、欧洲主要语种
- 工具调用能力:Berkeley Function Calling Leaderboard准确率81.00分,与GPT-4-turbo(81.24分)基本持平
- 多模态扩展:衍生模型GLM-4V-9B支持1120×1120高分辨率图像理解,图表识别性能接近闭源模型
行业影响:开源模式重塑AI产业格局
1. 降低企业AI应用门槛
某电商平台采用GLM-4-9B-Chat构建智能客服系统,结合工具调用实时查询库存,问题解决率提升35%,平均响应时间缩短至15秒。通过Docker容器化部署,中小企业可节省90%以上的模型采购成本。
2. 推动垂直领域创新
在法律领域,模型经微调后能解析500页合同中的风险条款,准确率达89%;医疗场景下,放射科报告自动生成效率提升60%。这些案例印证了轻量化模型在专业领域的适配潜力。
3. 开源生态加速形成
社区已基于该模型开发代码解释器、数据可视化等插件,形成"模型+工具链"的良性循环。据统计,GLM-4系列模型发布后3个月内,开发者贡献的微调版本超过20个,覆盖教育、金融等12个行业。
结论与前瞻
GLM-4-9B-Chat-1M的发布标志着国产开源模型正式进入全球第一梯队。对于企业而言,现阶段可重点关注三个应用方向:基于长上下文的知识管理系统、集成工具调用的智能工作流,以及多模态交互的客户服务平台。随着1M上下文技术的普及,大模型将从"对话工具"进化为"知识处理基础设施",推动AI应用进入深水区。
项目地址:https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
【免费下载链接】glm-4-9b-chat-1m-hf 项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m-hf
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







