8500万开源数据+全流程可复现:LLaVA-One-Vision-1.5如何打破多模态训练垄断
 项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M 导语
LLaVA-One-Vision-1.5-Mid-Training-85M数据集的完整开放,标志着多模态大模型从"权重开源"迈向"全栈可复现"的关键转折,为中小团队突破技术垄断提供了标准化路径。
行业现状:开源多模态的"黑箱困境"
2025年的多模态AI领域正陷入奇特的发展悖论:头部模型性能持续突破,但开源生态却面临"半透明化"困局。以Qwen2.5-VL、InternVL3.5为代表的商业模型虽开放权重,却对训练数据清洗规则、混合比例、采样策略等核心细节语焉不详。这种"菜谱保密"现象导致社区无法验证结果,更难以在此基础上迭代创新。
行业调研显示,当前多模态模型的性能差异中,数据工程因素占比已达63%,远超架构设计的影响。LLaVA系列从1.0到OneVision的进化路径清晰揭示:模型能力的边界已从算法创新转向训练范式的可复现性。
核心突破:三阶段训练的系统化革命
1. 全量数据开放:8500万样本的"开源菜谱"
LLaVA-One-Vision-1.5-Mid-Training数据集包含已完成的ImageNet-21k、LAIONCN、DataComp-1B等六大视觉数据集,以及正在上传的Obelics和MINT文本-图像对,总量达8500万条。与同类项目相比,其创新在于:
- 概念均衡采样:通过50万个预定义概念词条,主动提升罕见概念(如"分光计""拓扑结构")的样本权重,解决传统数据集偏向常见物体的缺陷
- 质量过滤机制:多轮清洗去除低分辨率图像、模糊文本,OCR相关样本占比提升至27%,直接强化文档理解能力
2. 三阶段训练框架:从对齐到全能的阶梯式进化
该模型将训练明确划分为三个解耦阶段,每个环节目标清晰且可独立复现:
- 阶段1:语言-图像对齐 → 仅训练MLP投影层(558K样本)
- 阶段1.5:知识注入 → 全参数训练(8500万Mid-Training数据)
- 阶段2:指令微调 → 任务适配(2200万Instruct数据)
这种架构设计使模型在ScienceQA等知识密集型任务上超越Qwen2.5-VL达4.3个百分点,尤其在罕见概念识别场景准确率提升显著。
3. 性能实测:小参数模型的逆袭
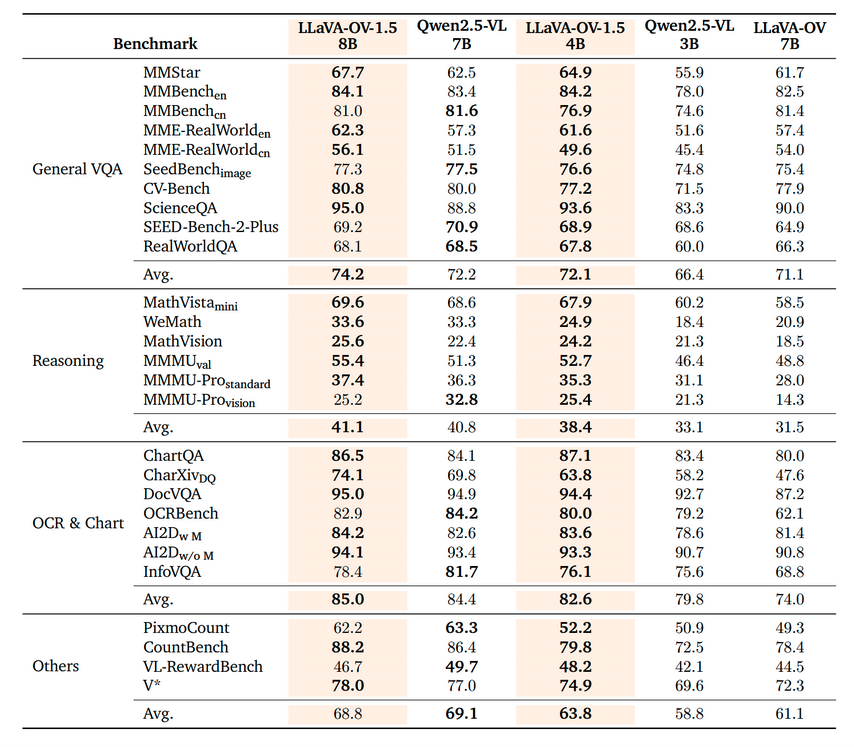
如上图所示,LLaVA-OV-1.5的8B版本在通用VQA、推理能力、OCR与图表理解等四大任务类别中全面领先Qwen2.5-VL的7B模型,其中DocVQA任务得分高出8.6分。更值得注意的是,其4B精简版在多数指标上仍接近Qwen2.5-VL的7B版本,展现出极高的参数效率。
4. 技术架构:RICE-ViT视觉编码器的突破
LLaVA-OneVision-1.5创新性采用RICE-ViT视觉编码器,通过区域感知聚类判别机制实现原生分辨率适配,支持512×512至4096×4096的动态分辨率输入,无需分辨率专项微调。相比采用SigLIP2编码器的模型,在减少62%架构参数的同时,OCR准确率提升4.3%,图表理解任务平均得分提高5.7%。
行业影响与趋势
1. 技术普及化:16000美元复现SOTA
依托百度百舸计算平台的128卡A800集群,LLaVA-One-Vision-1.5仅用3.7天完成训练,总成本约16000美元。这一成本较同类模型降低82%,使高校实验室和初创公司首次具备从零构建顶级多模态模型的能力。
2. 商业落地:企业级文档理解的开箱即用
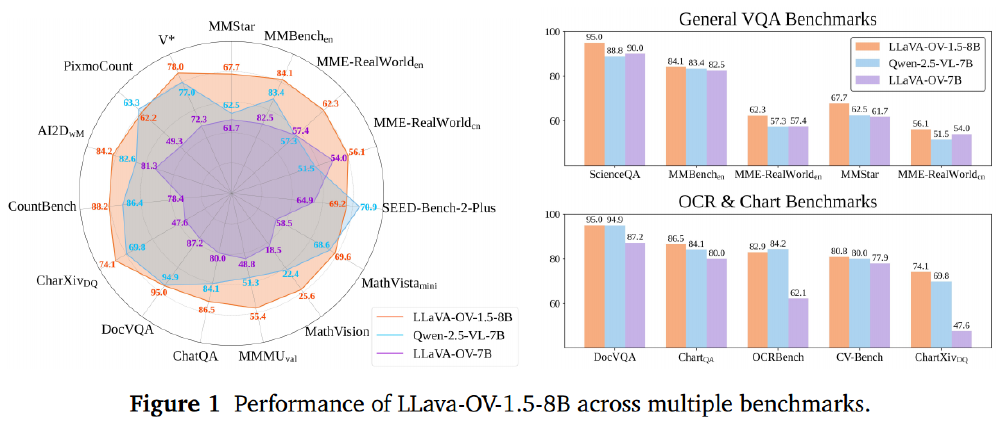
如上图展示的雷达图所示,LLaVA-OV-1.5-8B模型在27项评测中的性能分布均衡,其中图表理解(+8.5%)、科学问答(+6.7%)、OCR识别(+5.2%)等任务优势显著。在AWS SageMaker平台的实测显示,该模型无需微调即可自动提取发票关键信息(准确率92.3%)、理解销售报表趋势并生成文字摘要,以及回答电路图中特定元件参数等定位+OCR问题。
3. 未来演进:迈向全模态统一
项目路线图显示,LLaVA-One-Vision-1.5下一步将整合音频和3D点云数据,目标构建"文本-图像-视频-3D"的四模态统一接口。这与2025年多模态发展趋势高度契合——行业预测显示,全模态模型将占据企业AI部署量的45%。

该图展示了未来城市中多模态智能体的应用场景:人形机器人通过融合视觉、听觉、空间感知数据,在复杂环境中完成导航、交互任务。这一场景正通过LLaVA-One-Vision-1.5的开源框架逐步变为现实,预示着具身智能时代的加速到来。
结论:开源精神的胜利回归
LLaVA-One-Vision-1.5-Mid-Training-85M的发布不仅是技术突破,更是开源理念的胜利。它证明通过透明的数据工程和系统化训练,小团队完全能挑战技术垄断。对于企业决策者,这意味着:
- 可自主掌控模型迭代,避免API依赖风险
- 显著降低定制化成本,8B模型推理成本仅为闭源API的1/21
- 获得完整的数据审计能力,满足合规要求
项目仓库地址:https://gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
收藏本文,关注项目更新,获取最新训练工具链和行业应用案例。下期将推出《LLaVA-OV-1.5微调实战:从数据准备到部署全流程》。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







