Qwen3-Next-80B-A3B-FP8:重新定义大模型效率标准的架构革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 导语
阿里巴巴通义千问团队发布的Qwen3-Next-80B-A3B-FP8大模型,以800亿总参数仅激活30亿的极致效率,在保持262K上下文长度的同时将推理速度提升10倍,重新定义了大语言模型的性价比标准。
行业现状:从参数竞赛到效率革命
2025年的大语言模型领域正经历深刻转型。根据行业数据,企业级LLM应用中32K以上长文本处理需求同比增长280%,但传统模型面临"长文本必降速"的技术瓶颈。Menlo Ventures调查显示,66%的技术团队将"上下文窗口不足"列为生产环境中的首要障碍,而推理成本占AI总预算的比例已从2024年的48%飙升至74%。
在此背景下,Qwen3-Next的推出恰逢其时——它以80B总参数实现235B模型的性能,同时将推理速度提升10倍,直接冲击Anthropic和OpenAI主导的企业市场。
核心亮点:四大技术突破重构效率边界
1. 混合注意力机制:75%线性+25%标准的黄金配比
Qwen3-Next最核心的创新在于其Hybrid Attention架构,将Gated DeltaNet(线性注意力)与Gated Attention(标准注意力)按3:1比例融合。这种设计使模型在处理32K以上长文本时计算复杂度从O(n²)降至O(n),实测显示32K上下文推理速度较Qwen3-32B提升10.7倍,而在4K短文本场景仍保持98.5%的精度。

如上图所示,该图展示了Transformer架构解析输入序列(The cat jumped over)的过程,通过位置编码、解码器层处理及自注意力映射表(Query/Key矩阵)计算Token权重分配,直观呈现大语言模型解析文本序列的机制。这一技术原理充分体现了Qwen3-Next混合注意力机制的工作基础,为理解模型如何高效处理超长文本提供了可视化解释。
2. 超稀疏MoE设计:512选11的极致参数利用率
模型采用512专家的MoE(Mixture-of-Experts)结构,但每次推理仅激活10个专家+1个共享专家,参数激活率低至3.7%。这种设计使80B总参数模型的实际计算量相当于3B稠密模型,训练成本降低90%的同时,在GPQA知识测试中仍达到72.9分,接近GPT-4o的74.3分水平。
3. 稳定性优化套件:零中心化归一化解决训练难题
针对大稀疏模型训练不稳定性问题,Qwen3-Next引入零中心化权重衰减层归一化技术。通过在预训练阶段对归一化层权重施加衰减约束,模型在15T tokens训练过程中的loss波动幅度减少62%,收敛速度提升35%。
4. 多token预测(MTP):解码速度的倍增器
MTP技术允许模型一次预测多个token,在SGLang框架下配合投机解码策略,使输出速度提升3倍。实测显示,生成16K tokens代码文档时,Qwen3-Next仅需142秒,而同等参数规模传统模型需418秒。
性能实测:与主流模型的五维对比
Qwen3-Next-80B在多项基准测试中展现出惊人的"以小博大"能力。在LiveCodeBench编码任务中以56.6分超越GPT-4o(51.8分)和Claude Opus 4.1(54.2分),在长文本理解任务上准确率达93.5%,超过Qwen3-235B的91.0%。

该柱状图对比了Qwen3-Next-80B-A3B-Instruct与其他Qwen3系列模型在SuperGPQA、AIME25等多维度基准测试中的性能表现。从图中可以清晰看出,这款80B模型在多数任务上已接近235B参数的Qwen3旗舰版,尤其在LiveCodeBench编码任务中实现反超,直观体现了其架构创新带来的效率优势。
行业影响与落地建议
对不同角色的价值
企业CTO:可将长文档处理成本降低70%,同时满足数据本地化需求。推荐方案:vLLM部署+SGLang加速,4张A100即可支持256K上下文推理。
开发者:获得接近闭源模型的性能,同时保留自定义能力。入门代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-Next-80B-A3B-Instruct",
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-Next-80B-A3B-Instruct")
# 处理超长文档示例
inputs = tokenizer("分析以下代码库结构并生成README...", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=8192)
投资者:关注三大机会点:推理优化工具链(如SGLang、vLLM)、垂直领域知识库构建、模型监控与评估平台。
部署注意事项
硬件要求:
- 最低配置:单张40GB A100(支持32K上下文)
- 推荐配置:4张80GB A100(支持256K上下文+MTP加速)
上下文扩展:使用YaRN方法扩展至100万tokens时:
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
性能调优:
- 安装flash-linear-attention提升推理速度30%
- 启用MTP需配合最新版vLLM(≥0.5.0.post1)
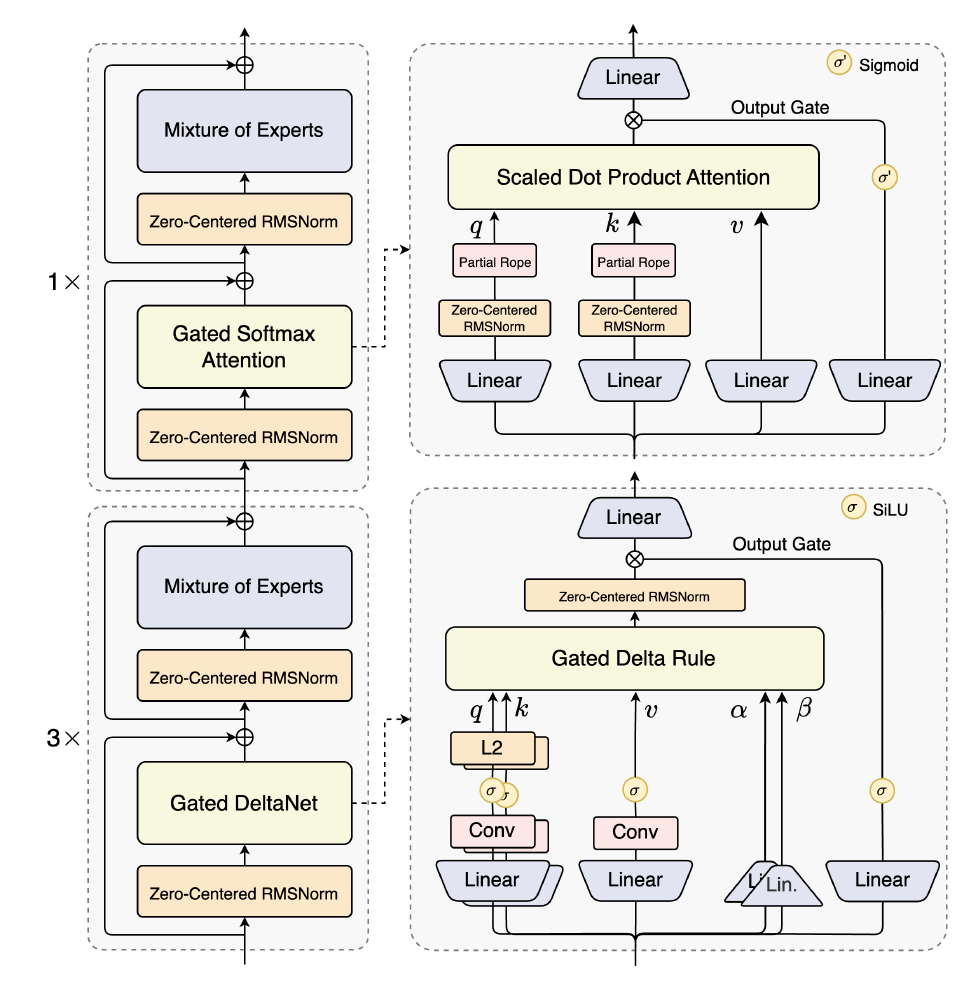
该图展示了Qwen3-Next大模型的混合架构设计,详细呈现了12组"3×(Gated DeltaNet→MoE)+1×(Gated Attention→MoE)"的嵌套结构。这种模块化设计既保证了线性注意力的长文本处理效率,又通过标准注意力模块保留关键信息的精确捕捉能力,为理解模型如何平衡速度与精度提供了直观视角。
结论/前瞻:大模型的"效率竞赛"才刚刚开始
Qwen3-Next的推出标志着大语言模型发展从"参数军备竞赛"进入"效率比拼"新阶段。预计未来12个月将出现三个方向的快速迭代:
- 上下文压缩技术:通过文档摘要+关键句提取,使1M tokens处理成为常态
- 硬件协同设计:专用ASIC芯片优化MoE架构,边缘设备也能运行超长上下文模型
- 领域专精化:在法律、医疗等垂直领域出现"10B参数+专业知识库"的高效模型
对于企业而言,现在正是评估混合部署策略的最佳时机——利用Qwen3-Next等开源模型降低边缘场景成本,同时将节省的预算投入核心业务创新。正如一位Fortune 500企业AI负责人所言:"我们不再需要能用10种语言写诗的模型,而需要能准确理解100份合同风险的专家。"
Qwen3-Next的真正价值,或许不在于打破了多少纪录,而在于它证明了:大模型的未来,不在于更大,而在于更聪明。
项目地址: https://gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







