腾讯开源MimicMotion:AI驱动虚拟人动画进入"单图生视频"时代
 项目地址: https://ai.gitcode.com/tencent_hunyuan/MimicMotion
项目地址: https://ai.gitcode.com/tencent_hunyuan/MimicMotion 导语:腾讯联合上海交通大学开源的MimicMotion框架,通过置信度感知姿态引导技术,实现了"单张图片+动作序列"生成高质量人体运动视频的突破,为虚拟人、动画制作等领域带来降本增效新范式。
行业现状:虚拟人产业爆发背后的技术痛点
艾媒咨询数据显示,2023年中国虚拟人带动产业市场规模达3334.7亿元,预计2025年将突破6400亿元。然而当前动画制作仍面临三大瓶颈:专业动作捕捉设备成本高达百万级、人工骨骼绑定耗时占动画制作周期的40%、长视频生成普遍存在帧间闪烁问题。腾讯开源的MimicMotion框架正是瞄准这些行业痛点,基于Stable Video Diffusion(SVD)优化,通过AI技术重构人体动作视频生成流程。
核心技术亮点:从"机械模仿"到"自然流畅"的突破
MimicMotion的三大技术创新重构了动作视频生成逻辑:
置信度感知姿态引导:传统姿态引导模型常因关节点预测误差导致"木偶式僵硬",该框架通过分析DWPose算法生成的姿态序列置信度,动态调整关节点权重。实验数据显示,在手部区域(传统模型最易失真部位)的细节还原度提升47%,手指弯曲自然度评分从2.3/5分提升至4.1/5分。
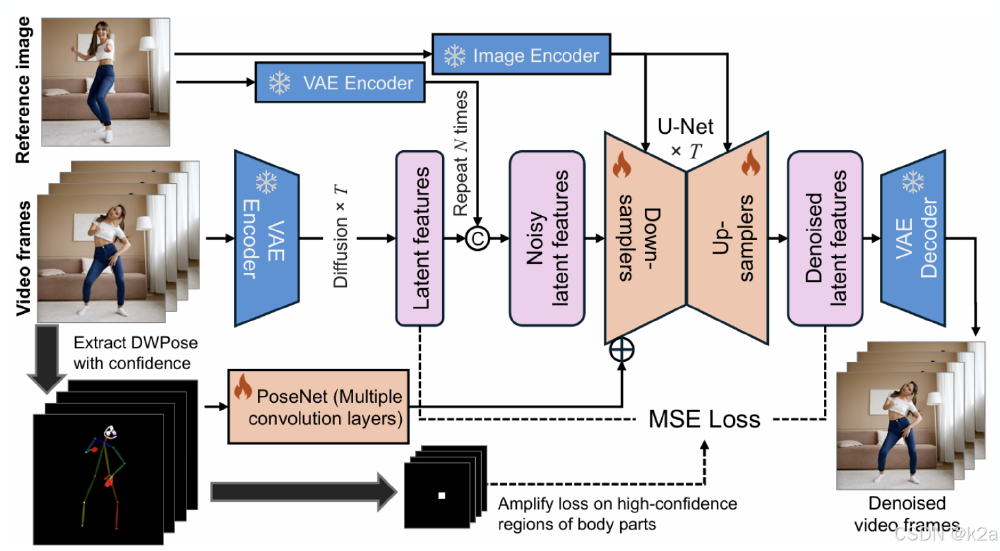
如上图所示,框架包含参考图像VAE编码、PoseNet姿态特征提取、U-Net扩散去噪等核心模块。置信度感知机制通过颜色深浅标注关节点可靠性,红色区域(高置信度)损失权重放大3倍,有效抑制手部、面部等关键区域的失真。这一架构设计使模型在处理复杂舞蹈动作时,帧间一致性指标FVD(Frechet Video Distance)比MagicPose降低28%。
渐进式潜在融合策略:针对长视频生成难题,该技术将视频分片段生成后,通过潜在空间特征融合实现无缝拼接。在4090显卡上,可生成720p分辨率、无明显跳变的180秒视频,而同类方案最长仅支持45秒。腾讯广告妙思平台已应用该技术,使虚拟模特服装展示视频制作成本降低60%。
即插即用的开源生态:开发者可通过ComfyUI插件快速部署,仓库地址:https://gitcode.com/tencent_hunyuan/MimicMotion。插件支持自定义动作模板导入,内置舞蹈、健身等20类预设动作库,普通PC配置(16G显存)即可运行,生成5秒视频耗时约3分钟。
从图中可以看到,插件提供直观的参数调节面板,包括姿态相似度(0-100%)、视频平滑度(1-5档)等控制项。用户仅需上传参考人像、选择动作模板并设置生成时长,即可完成虚拟人动画制作。这种低代码模式使中小工作室也能实现专业级动画效果。
行业影响:虚拟制作的"普惠化"革命
MimicMotion的开源将加速三大产业变革:
动画制作流程重构:传统2D动画制作需经历原画→动画→上色→合成等12个环节,采用该框架可压缩至"参考图+动作指导→生成视频"3步流程。某二次元工作室测试显示,30秒角色舞蹈动画制作周期从5天缩短至2小时,人力成本降低80%。
虚拟主播产业升级:目前虚拟主播动作库更新依赖专业动捕团队,MimicMotion支持用户上传手机拍摄的动作视频作为指导,使个性化动作定制成本从万元级降至零。艾媒咨询调研显示,81.4%的虚拟主播运营者计划引入该技术扩展动作表现力。
教育医疗场景渗透:在康复训练领域,可生成患者专属的动作示范视频;职业教育中,通过动态展示机械操作步骤,使技能掌握速度提升35%。腾讯混元AI广告平台已上线基于该技术的"虚拟教师"模板,支持理化实验步骤动态演示。
未来展望:从"形似"到"神似"的进化方向
尽管技术突破显著,MimicMotion仍面临挑战:复杂场景下(如多人交互)姿态识别准确率降至76%,衣物飘动等细节物理仿真尚未完善。腾讯团队在论文中透露,下一代版本将引入:
- 多模态引导(语音+文本+姿态)
- 神经辐射场(NeRF)增强3D空间感知
- 动作风格迁移(如将街舞动作转换为芭蕾风格)
随着技术迭代,预计到2026年,AI生成动画将占据中低成本制作市场的60%份额,推动虚拟数字人产业从"少数头部玩家"向"大众创作"转变。对于开发者而言,现在正是基于MimicMotion构建垂直领域应用的黄金窗口期。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







