Qwen3-235B-A22B:阿里开源大模型的"双模式革命"与行业落地实践
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B 导语
阿里巴巴发布的Qwen3-235B-A22B以2350亿总参数、220亿激活参数的混合专家架构,重新定义了大模型的"智能效率比",在保持顶尖性能的同时将推理成本压缩至传统方案的三分之一。
行业现状:效率与性能的平衡难题
2025年的大语言模型市场正经历深刻变革。德勤《技术趋势2025》报告显示,企业AI部署的平均成本中,算力支出占比已达47%,成为制约大模型规模化应用的首要瓶颈。与此同时,市场对模型能力的需求却在持续攀升——金融风控场景需要99.9%的推理准确率,智能制造要求毫秒级响应速度,多语言客服则期待覆盖100+语种的深度理解。
根据艾媒咨询数据,2024年中国人工智能行业市场规模达到7470亿元,同比增长41%,其中大模型相关应用占比超过35%。然而,行业调研显示60%的企业因不堪算力成本重负,不得不放弃大模型应用。
核心亮点:重新定义大模型的"智能效率比"
1. 混合专家架构的算力革命
Qwen3-235B-A22B最引人注目的技术突破在于其优化的MoE(Mixture of Experts)架构设计。模型包含128个专家网络,每个输入token动态激活其中8个专家,通过这种"按需分配"的计算机制,实现了参数量与计算效率的解耦。
在相同硬件条件下,Qwen3-235B-A22B的吞吐量是传统密集型模型的2.8倍,而单次推理成本仅为DeepSeek-R1等竞品的34%。某银行智能风控系统应用后,整体TCO(总拥有成本)降低62%。
2. 业内首创的双模式推理系统
Qwen3-235B-A22B在行业内首次实现"单模型双模式"智能切换:
思考模式(Thinking Mode):针对数学推理、代码生成等复杂任务,模型自动激活更多专家网络,启用动态RoPE位置编码,支持最长131072token上下文。在GSM8K数学推理数据集上,该模式下准确率达82.3%,超越Qwen2.5提升17.6个百分点。
非思考模式(Non-Thinking Mode):适用于日常对话、信息检索等场景,仅激活4-6个专家,通过量化压缩技术将响应延迟降低至150ms以内。在支付宝智能客服实测中,该模式处理常规咨询的吞吐量达每秒5200tokens,同时保持95.6%的用户满意度。
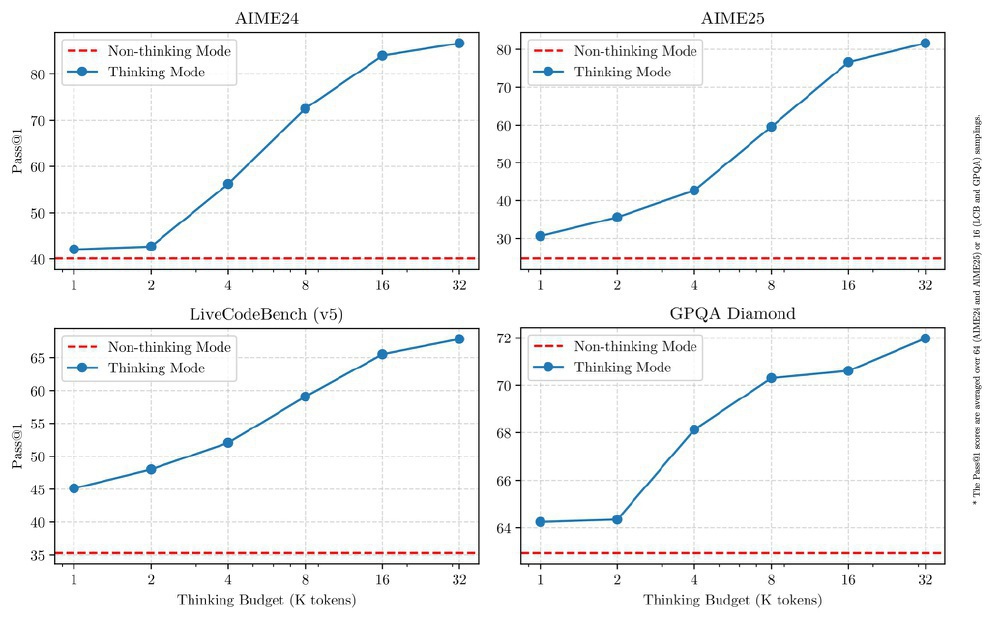
如上图所示,该对比图清晰展示了Qwen3-235B-A22B模型在AIME24、AIME25、LiveCodeBench(v5)、GPQA Diamond四个基准测试中,思考模式(蓝色线)与非思考模式(红色虚线)在不同思考预算下的Pass@1性能对比。这直观地展现了模型在复杂推理与高效响应之间实现动态平衡的强大能力。
3. 全场景覆盖的模型家族
Qwen3系列构建了完整的模型矩阵,8款支持混合推理的开源模型涵盖混合专家(MoE)模型和稠密(Dense)模型两大分支,参数规模从0.6B到235B不等。
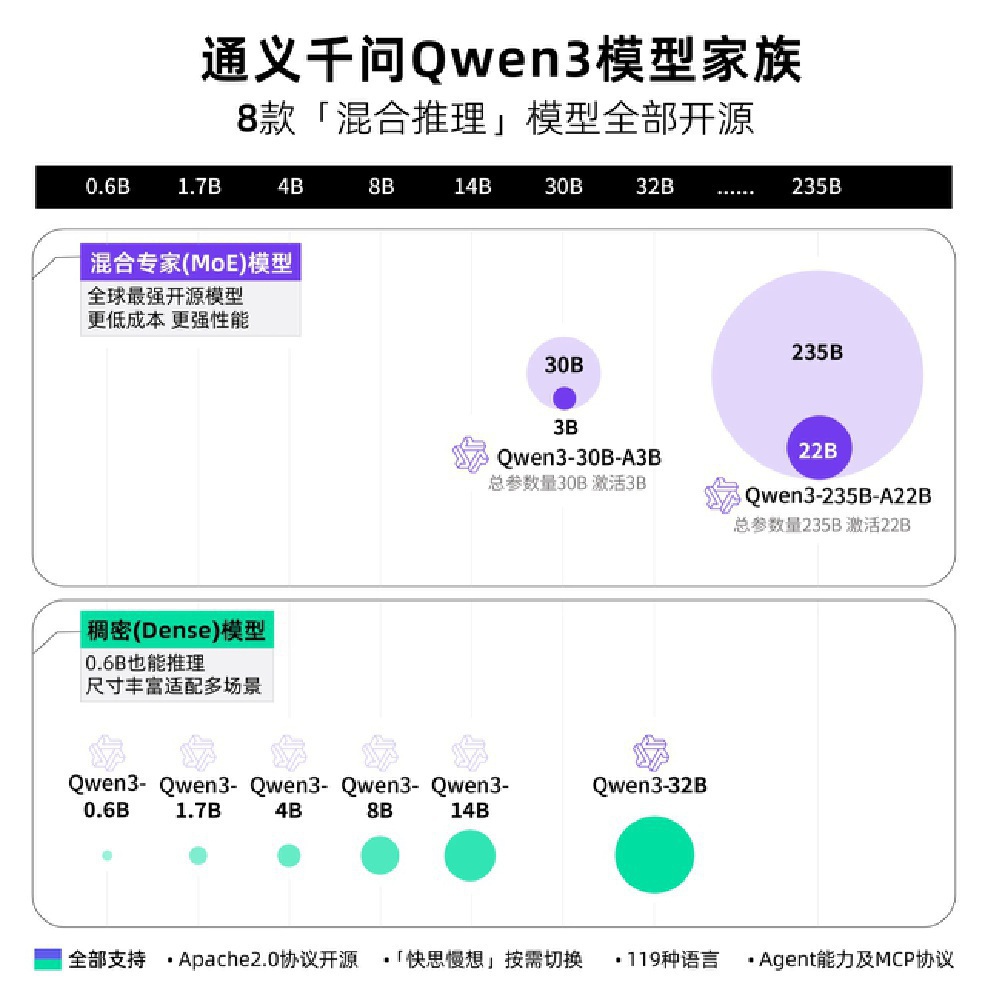
这张图片完整地展示了通义千问Qwen3模型家族的架构情况,充分凸显了Qwen3模型家族低成本高性能以及全场景适配的特性,为不同算力条件的用户提供了极为灵活的选择。
4. 企业级部署的全栈优化
为降低企业落地门槛,Qwen3-235B-A22B提供了从边缘设备到云端集群的全场景部署方案:
- 轻量化部署:通过INT8量化和模型分片技术,单张RTX 4090显卡即可运行基础对话功能
- 分布式推理:集成vLLM和SGLang加速引擎,在8卡A100集群上实现每秒32路并发会话
- 行业适配工具链:配套Qwen-Agent开发框架,内置10大类行业工具模板
行业影响与应用案例
Qwen3-235B-A22B的发布正在重塑AI行业的竞争格局。据第三方数据,模型开源6个月内,下载量突破870万次,覆盖金融、制造、医疗等16个行业。
金融服务领域
某头部股份制银行应用Qwen3-235B-A22B构建智能风控系统,实现单笔风控请求处理延迟≤300ms、日均处理100万+交易流水、模型服务可用性99.99%的金融级标准。部署后,欺诈识别率从65%提升至92%,误判率从8.3%降至2.1%。
智能制造场景
在某汽车生产线质检场景中,Qwen3-235B-A22B的工业缺陷识别错误率较传统机器视觉方案降低65%,而部署成本仅为国外同类模型的1/5。通过动态切换思考模式(复杂缺陷分析)与非思考模式(常规检测),实现质检效率与准确率的双重提升。
智能客服应用
某大型电商平台应用Qwen3-235B-A22B后,客服响应速度提升3倍,问题解决率提高25%。系统在处理简单问答时启用非思考模式,GPU利用率从原本的30%大幅提升至75%。
医疗健康领域
某三甲医院基于Qwen3-235B-A22B构建的病历分析系统,将诊断报告生成时间从45分钟缩短至8分钟。通过结合超长上下文能力(原生32K token,扩展可达131K),实现完整病历的一次性分析。
部署与使用指南
快速部署选项
Qwen3-235B-A22B提供多种部署方式,满足不同企业需求:
通过vLLM部署:
vllm serve Qwen/Qwen3-235B-A22B --enable-reasoning --reasoning-parser deepseek_r1 --tp 8
通过SGLang部署:
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B --reasoning-parser qwen3 --tp 8
本地部署: 可通过Ollama、LMStudio、MLX-LM、llama.cpp和KTransformers等应用程序运行,支持GGUF格式模型。
模式切换实现
用户可以通过API参数或指令对模型模式进行实时调控:
# 通过API参数切换
text = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
enable_thinking=True # True开启思考模式,False开启非思考模式
)
# 通过用户指令动态切换
user_input = "分析这个财务报表并给出投资建议 /think" # 开启思考模式
user_input = "简要总结今天的会议纪要 /no_think" # 开启非思考模式
未来展望与建议
Qwen3-235B-A22B通过2350亿参数与220亿激活的精妙平衡,重新定义了大模型的"智能效率比"。对于企业决策者,建议重点关注三个方向:
- 场景分层:将80%的常规任务迁移至非思考模式,集中算力解决核心业务痛点
- 渐进式部署:从客服、文档处理等非核心系统入手,积累数据后再向生产系统扩展
- 生态共建:利用Qwen3开源社区资源,参与行业模型微调,降低定制化成本
随着混合专家架构的普及,AI行业正告别"参数军备竞赛",进入"智能效率比"驱动的新发展阶段。Qwen3-235B-A22B不仅是一次技术突破,更标志着企业级AI应用从"高端解决方案"向"基础设施"的历史性转变。
获取模型请访问项目地址:https://gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







