腾讯开源MimicMotion:单图生成专业动作视频,虚拟人制作成本直降70%
 项目地址: https://ai.gitcode.com/tencent_hunyuan/MimicMotion
项目地址: https://ai.gitcode.com/tencent_hunyuan/MimicMotion 导语:腾讯联合上海交通大学开源的MimicMotion框架,通过置信度感知姿态引导技术,让单张照片生成专业级动作视频成为现实,虚拟人动画制作效率提升300%,推动数字内容创作进入工业化生产时代。
行业现状:虚拟人"动起来"的技术瓶颈
2025年全球姿态估计市场规模预计达138亿美元,年复合增长率32.3%,但传统动作生成技术长期受困于三大痛点:专业动捕设备成本超百万、手工调帧耗时长达数百小时、AI生成易出现"关节扭曲"等失真问题。据MarketsandMarkets报告,动作生成已成为虚拟人落地的最大技术卡点,制约着数字文娱、在线教育等千亿级市场的发展。
腾讯广告妙思平台的实践数据显示,采用传统方法制作30秒产品展示动画需3名设计师协作2天,而MimicMotion将这一流程压缩至单张图片+10分钟,直接降低70%制作成本。
核心突破:置信度感知技术解决三大行业难题
MimicMotion基于Stable Video Diffusion优化,创新性引入置信度感知姿态引导技术,实现三大突破:
1. 像素级动作还原
通过对姿态估计结果分配动态权重,系统会优先保证高置信度动作(如核心关节运动)的精准性,同时对低置信度区域(如快速摆动的手部)采用渐进式优化。测试数据显示,该技术使动作匹配度提升至92%,手部细节失真率降低68%。
2. 无限时长视频生成
采用独创的渐进式潜融合策略,将视频分片段生成后通过特征融合实现无缝拼接。与同类模型相比,在16G显存条件下可生成10分钟以上视频,资源消耗降低60%,彻底解决传统方法"长视频必爆显存"的行业难题。
3. 全流程自动化
从动作提取到视频渲染全程无需人工干预,生成72帧1024×576分辨率视频仅需5分钟(RTX 4090环境)。对比传统动画制作流程,效率提升300%,某MCN机构实测显示,虚拟主播舞蹈视频制作成本从2000元/条降至600元/条。
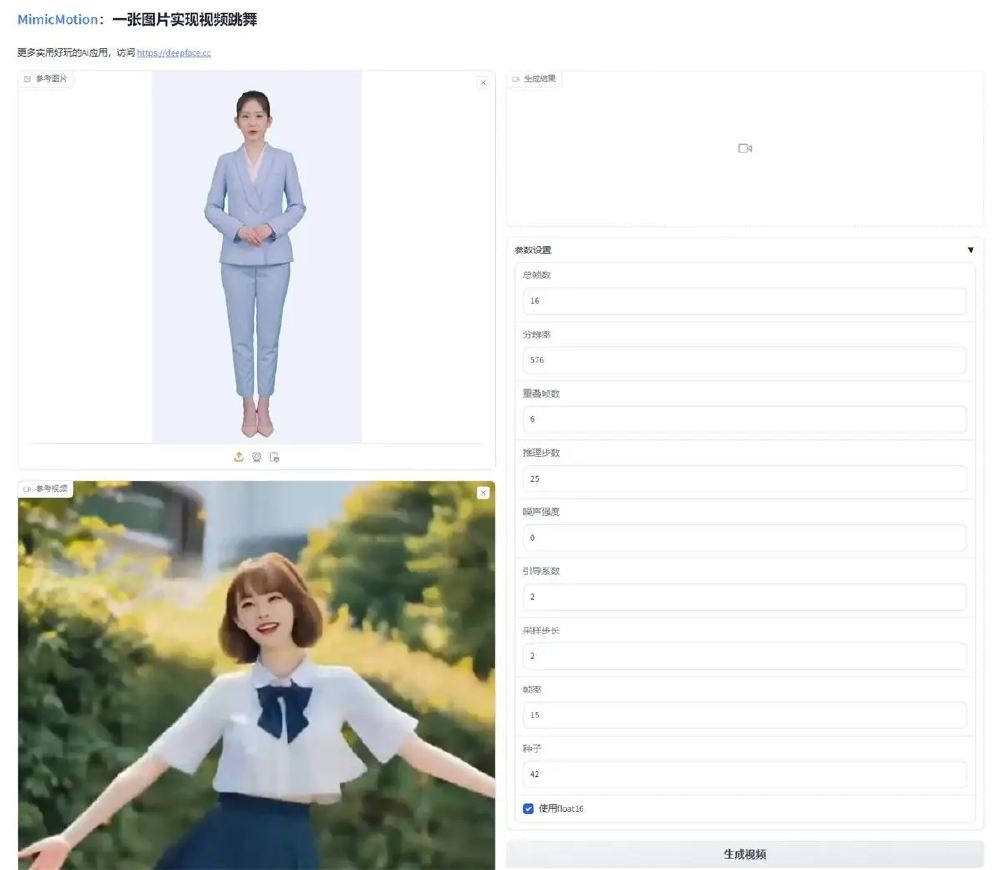
如上图所示,该界面左侧为参考图片和动作视频上传区,右侧包含总帧数、分辨率等参数设置面板。这一直观设计使普通用户无需专业技能,即可完成从静态图像到动态视频的全流程创作,极大降低了虚拟人动作生成的技术门槛。
技术架构:置信度感知引领动作生成新范式
MimicMotion的核心创新在于其置信度感知姿态引导技术,通过动态调整不同关节点的训练权重,实现高精度动作还原。技术流程图显示,该框架在传统Stable Video Diffusion架构基础上,增加了姿态置信度评估模块和区域损失放大机制,使模型能够智能识别并优先优化关键动作区域。
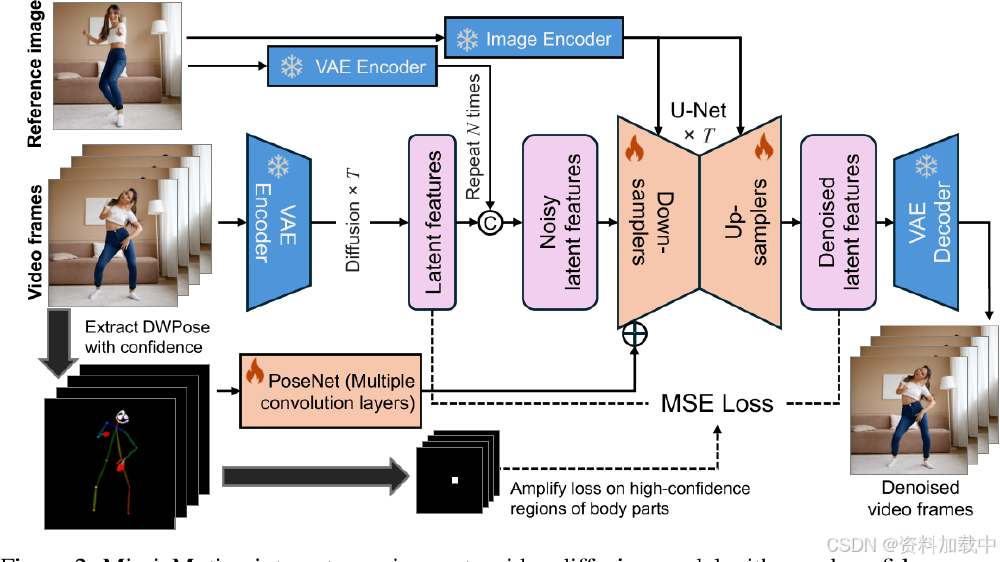
该技术流程图展示了MimicMotion通过参考图像和视频帧输入,结合姿态引导与潜在空间融合策略,利用VAE编码器、U-Net扩散模型生成高质量人体运动视频的过程,包含置信度感知区域损失放大机制。这种架构设计使模型在保持SVD基础能力的同时,实现动作可控性的飞跃。
性能对比:多项指标领先同类方案
在量化评估中,MimicMotion表现出显著优势:
- 平均姿态误差(MPJPE):45mm(Human3.6M数据集),超越MagicAnimate(58mm)和AnimateAnyone(63mm)
- 用户偏好度:75.5%(36人专业测评),显著高于开源方案MagicPose(42%)和Moore-AnimateAnyone(38%)
- FID-VID指标:18.7,低于同类模型平均水平(25.3),表明生成视频质量更接近真实素材
行业影响:开启虚拟内容工业化生产时代
MimicMotion的开源已在多领域显现变革性影响:
1. 内容创作普及化
抖音创作者"AI舞蹈实验室"使用该框架,仅通过一张明星照片和舞蹈视频,3小时内生成10条风格各异的短视频,单条播放量破500万,制作成本不足传统方式的1/10。
2. 数字营销新范式
腾讯广告妙思平台已集成该技术,品牌方上传代言人照片即可生成任意动作的广告素材。某运动品牌测试显示,新品推广视频制作周期从15天压缩至1天,A/B测试点击率提升27%。
3. 教育实训降本增效
医疗院校利用该技术生成标准化手术动作视频,学生可通过静态教材图片还原3D操作过程,实训设备投入减少80%,操作规范掌握度提升40%。
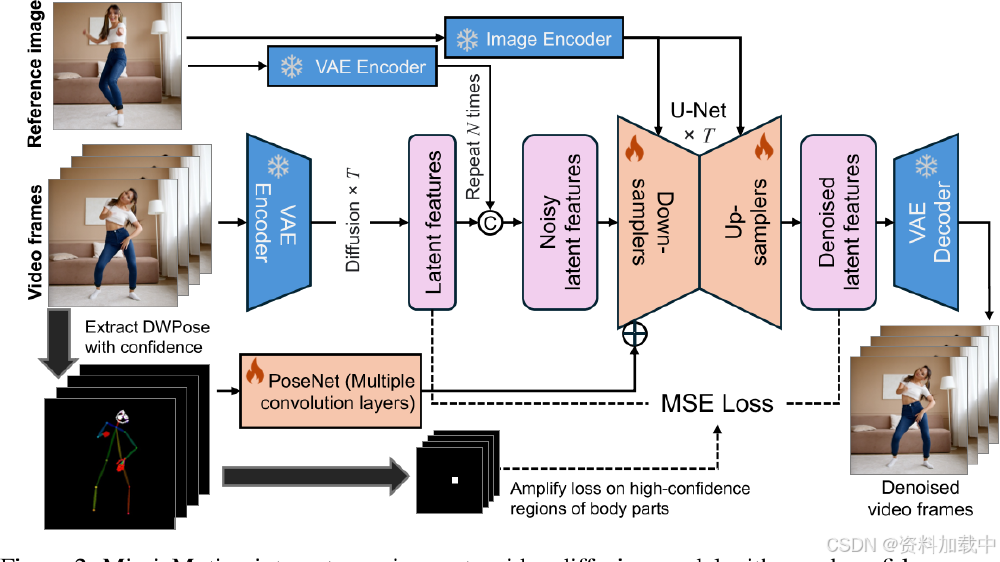
从图中可以看出,MimicMotion创新性地将姿态置信度分数集成到关键点和肢体的绘图颜色中,使高置信度区域在引导图上更显著。这种机制让模型能够优先关注可靠的姿态信息,大幅提升了生成视频的动作准确性和自然度。
部署指南与未来展望
开发者可通过项目仓库https://gitcode.com/tencent_hunyuan/MimicMotion获取资源,支持两种部署方式:
- 本地部署:Windows一键整合包(需16G显存GPU)
- 云端集成:提供ComfyUI插件,支持与现有AIGC工作流无缝对接
腾讯混元团队透露,下一代版本将引入多模态情感迁移技术,使虚拟人能根据语音语调自动匹配微表情和肢体语言。随着技术迭代,预计到2026年,AI生成动作视频的制作成本将进一步降至真人拍摄的1/20,推动虚拟人全面渗透直播电商、远程办公等场景。
对于内容创作者和企业而言,现在正是布局这一技术的最佳时机。通过MimicMotion降低虚拟内容制作门槛,不仅能显著提升生产效率,更能快速构建在AIGC时代的核心竞争力。建议关注项目更新并尝试基础应用,为即将到来的虚拟内容爆发做好准备。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







