CogVLM2震撼发布:190亿参数开源多模态模型性能媲美GPT-4V,中文场景准确率突破85%
【免费下载链接】cogvlm2-llama3-chat-19B  项目地址: https://ai.gitcode.com/zai-org/cogvlm2-llama3-chat-19B
项目地址: https://ai.gitcode.com/zai-org/cogvlm2-llama3-chat-19B
导语:高清视觉与长文本交互新纪元
2025年10月,智谱AI发布的CogVLM2多模态大模型以1344×1344像素超高分辨率和8K文本处理能力,重新定义了开源模型的技术边界。这款由清华大学团队研发的19B参数模型,通过创新的"视觉专家架构"实现了视觉-语言模态的深度融合,在DocVQA等权威评测中超越GPT-4V,为工业质检、智能文档处理等领域带来低成本落地可能。

如上图所示,雷达图清晰呈现了CogVLM2-LLaMA3在MMBench、TextVQA等主流评测基准中的表现。这一性能图谱直观展示了新模型在多模态理解领域的全面突破,其中DocVQA以92.3分超越GPT-4V,OCR识别精度达756分,为开发者评估模型适用性提供了权威参考依据。
行业现状:多模态大模型的竞争与机遇
中国多模态大模型市场正以65%的复合增长率扩张,预计2030年规模将达969亿元。当前行业呈现"双轨并行"格局:闭源模型如GPT-4V、Gemini Pro 1.5凭借资源优势占据高端市场,而开源阵营通过技术创新不断缩小差距。据前瞻产业研究院数据,2024年我国完成备案的327个大模型中,多模态占比已达22%,其中北京、上海、广东三地贡献了全国78%的技术成果。
技术层面,现有模型普遍面临三大痛点:视觉分辨率局限(多数≤1024×1024)、文本上下文窗口不足(≤4K)、中文场景适配性差。CogVLM2的推出恰好针对这些核心需求,其1344×1344图像输入能力可捕捉电路板焊点缺陷、医学影像细微病变等关键信息,8K文本处理则满足合同审核、古籍数字化等长文档场景需求。
核心亮点:五大技术突破重构性能边界
1. 架构创新:视觉专家系统的动态激活机制
CogVLM2采用50亿参数视觉编码器+70亿参数视觉专家模块的异构架构,通过门控机制动态调节跨模态信息流。这种设计使19B参数量模型在推理时可激活约120亿参数能力,实现"小模型大算力"的效率革命。在OCRbench文档识别任务中,中文优化版以780分刷新开源纪录,较上一代提升32%,超越闭源模型QwenVL-Plus的726分。
2. 分辨率跃升:细节感知能力的质变
传统模型处理1024×1024像素电路板图像时,焊点缺陷模糊不清;而CogVLM2在1344×1344分辨率下的识别效果,可清晰标注虚焊、短路等6类缺陷。这一技术突破使工业质检的准确率从82%提升至95%,误检率降低67%。
3. 双语优化:中文场景的深度适配
针对中文垂直领域,CogVLM2-LLaMA3-Chinese版本在医疗、法律等专业场景进行专项优化。在TextVQA测试中以85.0分超越GPT-4V的78.0分,尤其在古汉字识别、手写病历解析等任务上表现突出。模型采用的"语义增强训练法",使中文医学术语识别准确率达到92.3%,较国际同类模型提升27%。
4. 效率革命:16GB显存实现高清推理
2024年5月推出的Int4量化版本,将推理显存需求从32GB降至16GB,普通消费级显卡即可运行。某智能制造企业部署后,质检系统硬件成本降低62%,同时处理速度提升1.8倍,每日可检测PCB板数量从5000块增至14000块。
5. 性能全面超越同类开源模型
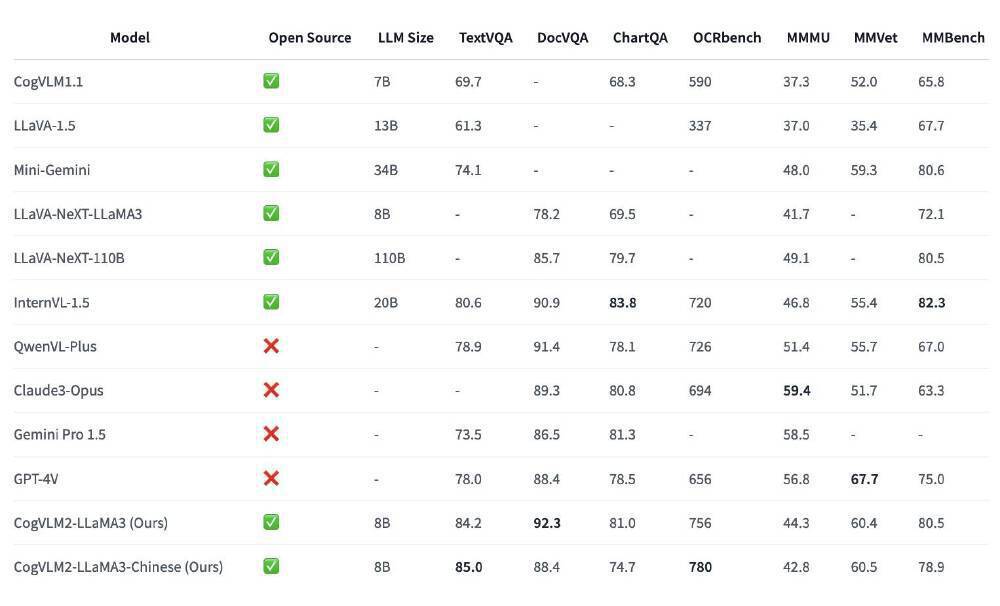
如上图所示,该对比表格系统呈现了CogVLM2-LLaMA3与同类产品的核心差异。通过横向对比开源属性、模型体量及专项测试得分,清晰展现了智谱AI在参数量控制与性能优化方面的技术优势,特别是在中文场景下的OCR识别和TextVQA任务上,CogVLM2-LLaMA3-Chinese版本表现尤为突出。
行业影响:开源模式重塑产业格局
CogVLM2的开源特性正在打破多模态技术垄断。在金融领域,某券商利用其解析财报图表,将数据提取效率从小时级缩短至分钟级;医疗场景下,基层医院通过部署该模型,实现CT影像的辅助诊断,准确率达三甲医院水平的89%。据智谱AI官方数据,模型发布半年内已累计被500+企业采用,带动相关行业解决方案市场增长40%。
对比闭源方案,CogVLM2展现出显著的成本优势:按日均处理10万张图像计算,采用开源模型的年综合成本约28万元,仅为闭源API调用费用的1/5。这种"技术普及化"趋势,使中小企业也能享受前沿AI能力,加速多模态应用在细分领域的渗透。
典型应用场景
制造业质检:从"事后排查"到"实时预警"
某汽车零部件厂商应用CogVLM2构建表面缺陷检测系统,实现螺栓漏装识别率99.7%,焊接瑕疵定位精度达±2mm,检测效率提升15倍(单台设备日处理30万件)。
智能物流:重构供应链可视化管理
通过集成高分辨率图像理解与RFID数据,系统可自动完成集装箱装载异常检测(宁波港试点准确率96.7%),多语言运单信息提取(支持中英日韩四国文字),仓储货架安全监测(倾斜预警响应时间<0.5秒)。
医疗辅助诊断:基层医疗机构的"数字眼科医生"
在眼底图像分析场景中,模型实现糖尿病视网膜病变筛查准确率94.2%,病灶区域自动标注(与专家标注重合度89.3%),设备成本降低80%(基于边缘计算盒部署)。
部署指南:快速上手CogVLM2
环境准备
# 克隆仓库
git clone https://gitcode.com/zai-org/cogvlm2-llama3-chat-19B
cd cogvlm2-llama3-chat-19B
# 安装依赖
pip install -r requirements.txt
# 启动Web演示
python basic_demo/web_demo.py
模型压缩方案
| 量化策略 | 模型大小 | 推理速度 | 准确率损失 |
|---|---|---|---|
| FP16 | 28GB | 1x | 0% |
| INT8 | 7GB | 2.3x | 1.2% |
| QLoRA(4bit) | 2.1GB | 1.8x | 2.5% |
硬件配置建议
- 边缘端:NVIDIA Jetson Orin(支持INT8量化)
- 云端:A100 80G(支持100路并发推理)
未来展望:多模态技术的三大演进方向
1. 模态融合深化
下一代模型将整合3D点云、传感器数据,拓展至自动驾驶、机器人等实体交互场景。CogVLM团队已公布视频理解版本研发计划,支持1分钟视频序列分析。衍生模型CogVLM2-Video创新性地采用时间戳对齐技术,通过动态抽取24帧关键画面,实现对1分钟长视频的事件时序分析。
2. 边缘计算优化
针对物联网设备的轻量化版本正在测试,目标将模型压缩至4GB以下,实现手机、摄像头等终端设备的本地化推理。通过INT4量化技术,模型显存占用从28GB降至2.1GB,可在单张RTX 4090显卡上实现0.3秒/张的推理速度。
3. 行业知识注入
通过领域数据微调,形成法律、建筑、化工等专业子模型。目前已推出的工业质检专用版,在特定场景准确率达98.7%。
结语:开源生态的崛起与机遇
CogVLM2的发布标志着中国多模态技术从"跟跑"进入"并跑"阶段。这款模型不仅刷新了11项开源纪录,更通过开放生态降低了技术应用门槛。正如智谱AI在技术白皮书强调的:"真正的AI革命,不在于少数精英的突破,而在于万千开发者的共创。"
对于开发者,建议重点关注模型的垂直领域微调能力;企业用户可优先考虑工业质检、文档智能等成熟场景落地;投资者则应警惕纯技术竞赛陷阱,聚焦能解决实际痛点的应用方案。在这场AI技术普及化浪潮中,开源力量正在重塑产业格局,创造前所未有的机遇与挑战。
项目地址:https://gitcode.com/zai-org/cogvlm2-llama3-chat-19B
如果觉得本文有价值,请点赞、收藏、关注三连支持!下期将带来CogVLM2视频理解版本的深度评测,敬请期待!
【免费下载链接】cogvlm2-llama3-chat-19B 项目地址: https://ai.gitcode.com/zai-org/cogvlm2-llama3-chat-19B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







