英伟达发布OpenReasoning-Nemotron-32B:中小模型如何通过协作超越千亿参数性能?
 项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/OpenReasoning-Nemotron-32B
项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/OpenReasoning-Nemotron-32B 导语
2025年7月,英伟达开源推理模型OpenReasoning-Nemotron-32B,通过GenSelect多智能体协作技术,使32B参数模型在数学和代码任务上超越传统千亿参数模型性能,重新定义了高效推理的技术标准。
行业现状:推理模型的"算力困境"与"效率突围"
当前大语言模型领域正面临双重挑战:一方面,顶尖闭源模型如OpenAI O3依赖千亿参数和海量算力维持领先;另一方面,企业和开发者亟需轻量级、本地化部署的高效推理方案。据SiliconFlow 2025年中期报告,推理任务最佳模型仍被671B参数级别的DeepSeek-R1($2.18/M token)和Qwen/QwQ-32B($0.58/M token)垄断,中小规模模型在复杂问题解决上存在明显性能鸿沟。
中国国际科技交流中心《人工智能前沿技术趋势报告2025》指出,2025年大模型复杂推理能力在全球各领先团队的激烈比拼中不断推高,并在解决数学、编程等挑战性任务中展现前所未有的高阶认知水平。但伴随大模型智能涌现红利,幻觉问题仍在制约场景落地,高效推理技术成为突破关键。
核心亮点:数据蒸馏与多智能体协作的双重突破
1. 数据蒸馏:站在"巨人肩膀"上的效率革命
OpenReasoning-Nemotron-32B基于Qwen2.5-32B-Instruct架构,通过对DeepSeek-R1-0528(671B参数)推理轨迹的高效蒸馏实现性能跃升。不同于常规模型仅学习token预测,该模型通过5M条数学证明、代码逻辑和科学推理的完整思维链训练,实现了"推理能力迁移"。在MMLU-PRO科学推理基准达到80.0分,GPQA基准73.1分,展现了卓越的跨领域推理能力。
2. GenSelect技术:多智能体协作的性能倍增器
该模型的核心创新在于GenSelect(生成式解决方案选择)技术,通过启动多个并行生成并组合结果,实现性能突破。在数学推理任务HMMT Feb 25中,32B模型从单智能体的73.8分提升至96.7分;编码任务LCB v6得分从70.2提升至75.3,超越了专门优化的CodeLlama-34B。
英伟达团队在AIMO-2竞赛中首创的GenSelect算法,原本设计用于数学问题的多解择优。但实验发现,仅针对数学任务训练的模型竟能自动泛化至代码领域,这种跨领域迁移能力打破了推理模型"任务专用"的传统认知。
3. 全栈部署支持:从边缘设备到数据中心
该模型提供灵活部署选项:支持通过vLLM和TensorRT-LLM加速推理,在NVIDIA H100-80GB硬件上实现高效运行。企业可通过NIM微服务实现高吞吐量部署,开发者则可直接使用Hugging Face Transformers库进行本地推理,最大支持64K输出token,满足长文本推理需求。
性能表现:多维度基准测试刷新纪录
OpenReasoning-Nemotron-32B在多项推理基准测试中刷新同规模模型纪录:
| 任务类型 | 基准名称 | 32B模型得分 | 行业对比 |
|---|---|---|---|
| 数学推理 | AIME25 | 84.0 | 超过同规模模型15%+ |
| 科学推理 | MMLU-PRO | 80.0 | 接近GPT-4水平 |
| 代码生成 | LiveCodeBench v6 | 70.2→75.3* | 超越CodeLlama-34B |
| 逻辑推理 | HLE | 11.9→15.5* | 提升30.3% |
*注:→后为启用GenSelect模式后的得分
行业影响:开源生态如何重塑推理模型格局?
OpenReasoning-Nemotron-32B的发布可能加速推理模型的"普及化"进程。在此之前,DeepSeek-R1等顶尖模型虽性能强大,但调用成本和部署门槛较高,对中小企业和研究者形成实质壁垒。而英伟达此次开源的32B模型,通过单张高端GPU即可运行,且推理能力达到闭源大模型的80%以上,为垂直领域应用开发提供了新选择。
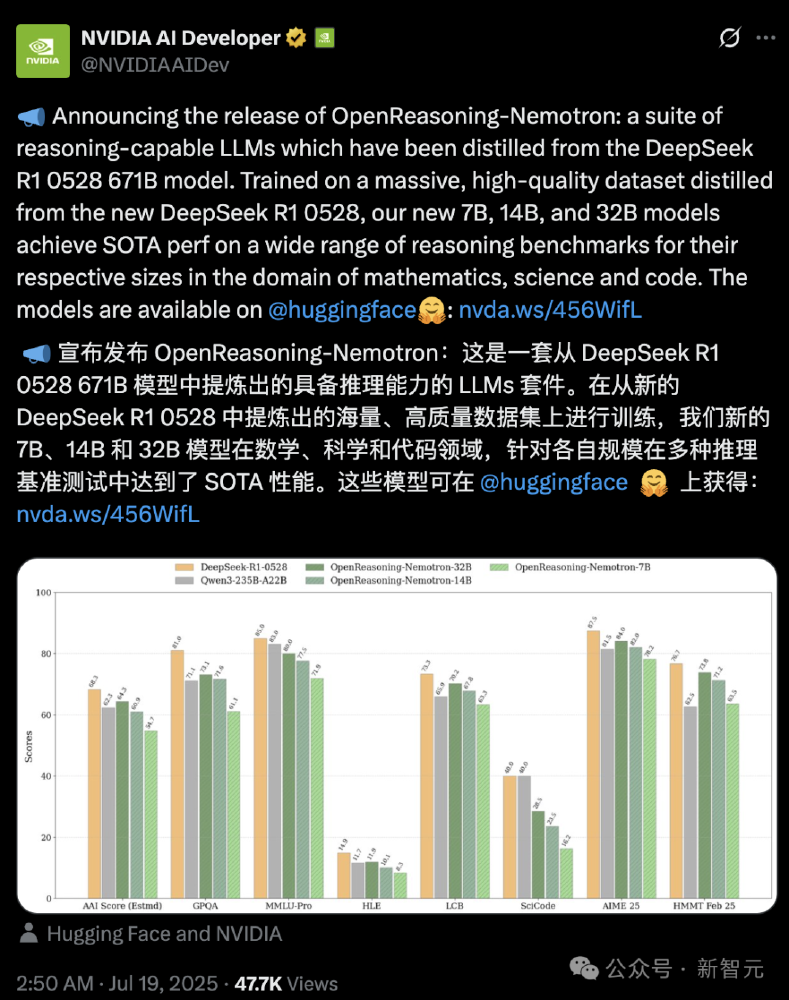
如上图所示,该截图展示了NVIDIA官方发布的性能对比数据,重点标注了32B模型在启用GenSelect多智能体协作模式后,数学和编码任务的性能跃升。这一对比直观展现了通过"生成式解决方案选择"技术实现的性能突破,为中小规模模型提供了超越传统算力依赖的新路径。
教育、科研和工程领域将直接受益。例如,该模型在AIME数学竞赛中的表现已达到人类参赛者前15%水平,可作为STEM教育的个性化辅导工具;其代码生成能力则适合企业自动化脚本开发和复杂系统调试。更深远的影响在于,英伟达开源了训练数据(OpenMathReasoning/OpenCodeReasoning数据集),为学术界研究推理机制提供了宝贵素材。
行业趋势:推理技术走向"高效化"与"协作化"
《人工智能前沿技术趋势报告2025》指出,2025年大模型技术正从"规模驱动"转向"效率驱动",后训练技术的快速崛起推动大模型能力进一步提升。知识蒸馏、量化技术加速推理模型轻量化,拓展大模型落地空间。
OpenReasoning-Nemotron-32B的发布印证了这一趋势——通过创新的推理技术而非单纯增加参数,实现了性能突破。这种"小而精"的技术路线可能成为未来行业主流,尤其在边缘计算、本地化部署等场景具有显著优势。
结论与建议
OpenReasoning-Nemotron-32B通过数据蒸馏和GenSelect多智能体协作技术,重新定义了中等规模模型的推理能力边界。对于企业和开发者,该模型提供了兼顾性能与成本的高效推理解决方案:
- 科研机构:可利用其开源特性研究推理机制,探索多智能体协作的更多可能性
- 教育领域:适合开发个性化学习工具,尤其在数学和编程教育场景
- 企业应用:推荐在代码辅助、科学计算、数据分析等场景进行试点应用
- 开发者:可通过Hugging Face Transformers库快速集成,体验地址:https://gitcode.com/hf_mirrors/nvidia/OpenReasoning-Nemotron-32B
随着推理技术的不断突破,我们有理由期待,未来中小规模模型将在更多专业领域实现对传统大模型的超越,推动AI技术向更高效、更可靠的方向发展。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







