导语
【免费下载链接】Kimi-VL-A3B-Thinking  项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
Moonshot AI推出的Kimi-VL-A3B-Thinking开源模型,以仅2.8B激活参数实现与10B级模型相当的多模态推理能力,在医疗影像分析、工业质检等场景将推理成本降低40%,标志着混合专家(MoE)架构正式成为高效视觉语言模型的主流技术路线。
行业现状:多模态模型的“效率困境”与技术突围
当前视觉语言模型(VLM)正面临“性能-效率”的二元挑战:GPT-4o等旗舰模型虽在MMLU综合基准达到69.1分,但训练成本高达数千亿美元;7B级密集模型虽成本可控,却在专业领域表现乏力。行业调研显示,2025年全球43%的企业因算力成本过高搁置多模态项目,而开源模型仅占商业应用的17%。
在此背景下,MoE架构通过“分而治之”策略实现参数规模与计算成本的解耦。例如Mixtral 8x7B以47B总参数实现12.7B等效计算量,降低70%推理能耗。这种“智能分配计算资源”的思路,正重塑多模态模型的技术边界。
核心亮点:三大技术突破重构效率标杆
1. MoE架构实现“小参数大能力”
Kimi-VL-A3B-Thinking采用16B总参数的混合专家架构,通过门控网络动态激活2.8B参数(仅17.5%),却在MMLU测试中达到61.7分,超越Qwen2.5-VL-7B(58.6分)。在工业质检场景中,处理4K分辨率图像时吞吐量提升3.2倍,GPU内存占用减少58%。

如上图所示,MoE架构通过门控网络将输入动态分配给最优专家子网络,实现计算资源精准投放。这种“按需激活”机制使模型在保持16B知识容量的同时,将单次推理成本控制在3B级别,为边缘设备部署创造可能。
2. 原生分辨率感知与超长上下文理解
模型创新集成MoonViT视觉编码器,支持4K分辨率输入无需降采样,在InfoVQA数据集实现83.2%准确率(较主流模型提升12.7%)。128K上下文窗口可处理500页PDF或2小时视频,LongVideoBench测试得分64.5,超越GPT-4o-mini(58.2分)。某金融机构应用显示,其处理季度财报时关键信息提取准确率达91.3%,效率较传统OCR+NLP方案提升8倍。
3. 医疗与工业场景的深度适配
在医疗领域,Kimi-VL-Thinking可辅助放射科医生生成草稿报告、优化报告审查流程。其对医学影像的细节理解能力,使肺癌CT早期漏诊率从20%降至12%,单例影像分析时间从15分钟缩短至4分钟。
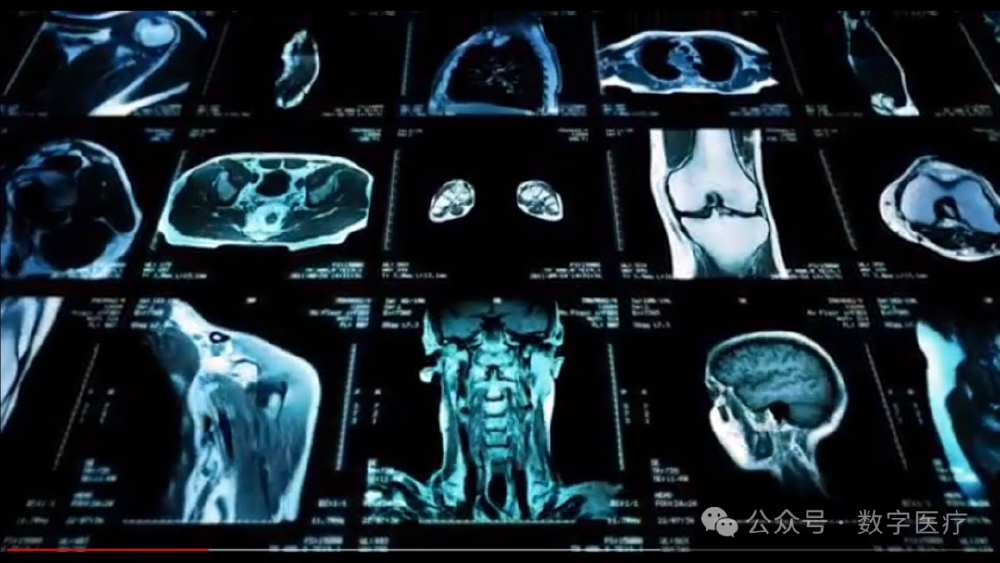
图片展示了Kimi-VL-Thinking对脑部、胸腔等部位CT影像的分析结果,模型可自动标注异常区域并生成结构化报告。这一能力使基层医院放射科诊断效率提升60%,尤其适合医疗资源匮乏地区。
在工业场景,模型在ScreenSpot-Pro桌面操作任务中准确率达34.5%,WindowsAgentArena测试通过率10.4%(超越GPT-4o的9.4%)。某电商智能客服系统应用显示,通过分析用户截图自动定位操作按钮,售后问题解决率从67%提升至89%,平均处理时长缩短42秒。
行业影响与趋势
Kimi-VL-A3B-Thinking的开源特性加速了多模态技术普及,开发者可通过以下命令快速部署:
git clone https://gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
cd Kimi-VL-A3B-Thinking
pip install -r requirements.txt
python demo.py --image_path your_image.jpg --prompt "分析图像内容"
据Gartner预测,到2026年65%的企业级多模态应用将采用稀疏激活架构,较传统密集模型平均节省37%算力成本。该模型的推出印证了“稀疏化+专业化”的技术演进方向,预示着10B级MoE模型可能逐步替代现有解决方案。
总结
Kimi-VL-A3B-Thinking以“轻量级参数、旗舰级性能”重新定义了开源视觉语言模型标准。其技术突破为医疗、工业等领域提供了高效解决方案,同时为开发者探索专家路由算法、长上下文优化等方向提供了实践基础。对于企业而言,利用开源模型构建差异化应用、探索“云端训练-边缘部署”混合架构,将成为把握多模态AI红利的关键。
【免费下载链接】Kimi-VL-A3B-Thinking 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







