腾讯HunyuanVideo 1.5开源:轻量级视频生成模型如何重塑内容生产生态
【免费下载链接】HunyuanVideo  项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanVideo
项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanVideo
导语
腾讯混元团队于2025年11月20日正式开源轻量级视频生成模型HunyuanVideo 1.5,以83亿参数实现消费级显卡部署,将专业视频创作能力从昂贵的GPU集群解放至普通开发者手中。
行业现状:视频生成技术的普惠化临界点
2025年全球AI视频生成市场规模预计达422.92亿美元,但中小企业长期面临"三重困境":专业级视频生成需负担5-7美元/分钟的API调用成本,开源模型多停留在20B参数规模,需要超过50GB显卡方可部署。此前主流开源SOTA旗舰模型至少有20B参数,而HunyuanVideo 1.5的出现大幅降低了硬件部署门槛,以极低的门槛就可以获得旗舰模型的体验。
中金研报指出,近期多个AI视频模型发布进展,基座/垂类模型升级、头部厂商投入有望推动传媒应用层发展。开源方面,阿里巴巴、昆仑万维等模型开源或加速中小厂商二次开发,推动技术进步。
产品亮点:轻量却旗舰的技术突破
硬件门槛大幅降低
HunyuanVideo 1.5支持生成5-10秒(129-257帧)的高清视频,同时在硬件需求上进行了优化,可在消费级显卡上运行。相比上一代旗舰版(13B+参数)需要超过50GB显卡方可部署,新版本以8.3B参数实现了硬件门槛的显著下降。
创新的双流Transformer架构
HunyuanVideo采用创新的"双流到单流"混合Transformer设计:在双流阶段,视频令牌与文本令牌通过独立Transformer块处理,保留各自模态特性;在单流阶段,融合后的令牌序列进入共享Transformer层,实现跨模态信息交互。这种设计使模型能同时处理图像生成(2D)和视频生成(3D)任务,参数共享率达70%,显著提升训练效率。
多模态文本理解能力
不同于主流模型采用的CLIP或T5编码器,HunyuanVideo创新性地使用多模态大语言模型(MLLM)作为文本理解核心。特别设计的双向令牌优化器解决了MLLM因果注意力导致的文本特征单向性问题,使扩散模型的文本引导精度提升15%。
高效视频压缩技术
HunyuanVideo设计的3D VAE通过三维因果卷积实现高效视频压缩,时间维度4倍、空间维度8倍、通道维度16倍的压缩比,将720p 129帧视频从1.3亿像素压缩至256个令牌,较传统方案节省60%显存。
实用的提示词重写机制
针对用户输入提示词质量参差不齐的问题,HunyuanVideo提供两种重写模式:Normal模式优化语义表达,增强模型对用户意图的理解;Master模式强化构图、光照、相机运动描述,提升视觉质量。通过微调Hunyuan-Large模型实现的提示词重写器,可将生成视频的文本对齐度从48.4%提升至61.8%。
平台体验与应用场景
直观的操作界面
腾讯混元AI视频平台提供了用户友好的"图生视频"功能界面,支持上传图片、输入动作/镜头描述、选择模型与参数设置等功能,降低了普通用户的使用门槛。
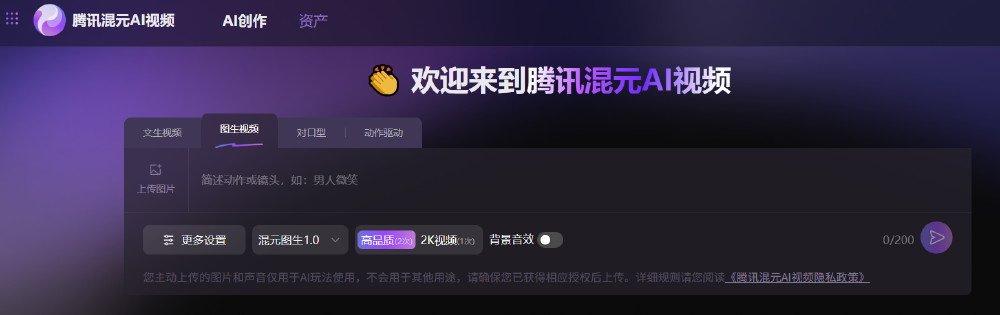
如上图所示,该界面展示了上传图片、输入动作/镜头描述、选择模型与参数设置等区域。这一设计充分体现了HunyuanVideo对用户体验的重视,为普通创作者提供了直观易用的视频生成工具。
多样化的应用场景
HunyuanVideo 1.5已在腾讯元宝App中集成,支持直接通过文字或图片生成视频。其应用场景广泛,包括:
- 创意短视频创作:个人创作者可快速生成高质量短视频内容,降低制作门槛
- 电商营销内容:商家可批量生成产品展示视频,提升营销效率
- 教育培训内容:教师和培训机构可将静态教材转化为动态视频,增强教学效果
- 数字人视频生成:结合HunyuanVideo-Avatar模型,实现语音驱动数字人视频创作
行业影响与趋势意义
推动开源生态发展
HunyuanVideo的开源不仅提供了可复现的模型权重,更重要的是分享了完整的工程化框架,包括2000万+高质量视频的清洗与标注流程、图像-视频联合训练的损失函数设计、CPU卸载与流式生成技术等,为中小团队和研究者提供了从0到1构建百亿级视频模型的完整蓝图。
促进技术普惠
随着HunyuanVideo等开源模型的出现,视频生成技术正从专业领域向大众普及。降低的硬件门槛和易用的工具链,使更多个人创作者和中小企业能够利用AI视频技术提升内容生产效率。
加速商业化落地
多家AI视频公司已开放会员付费、API服务等多种商业化模式。快手可灵AI视频模型已实现商业化流水,单月流水超千万元。HunyuanVideo 1.5的推出,有望进一步推动AI视频技术在各行业的商业化应用。
未来发展方向
HunyuanVideo的出现为开源视频生成领域指明了清晰的发展路径:模型小型化与效率提升、专业化垂直领域模型开发、多模态交互能力增强,以及训练数据与伦理规范的完善。预计2025年将出现10亿参数级、消费级GPU可运行的开源视频模型,进一步推动视频生成技术的普及。
总结
HunyuanVideo 1.5的开源标志着视频生成技术进入了新的发展阶段。通过创新的架构设计和工程优化,腾讯混元团队成功降低了高质量视频生成的技术门槛,为开发者和创作者提供了强大而灵活的工具。随着开源生态的不断完善和应用场景的持续拓展,我们有理由相信,视频生成技术将在内容创作、教育培训、广告营销等领域发挥越来越重要的作用,为行业带来新的机遇与挑战。
对于开发者而言,现在正是探索HunyuanVideo潜力的最佳时机,通过参与模型迭代、共享训练经验和探索创新应用,共同推动视频生成技术的发展。对于企业和创作者来说,应积极关注这一技术趋势,探索AI视频生成在自身业务中的应用可能性,以提升效率、降低成本、创造更丰富的内容体验。
【免费下载链接】HunyuanVideo 项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanVideo
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







