61亿参数撬动400亿性能:蚂蚁开源Ring-flash-2.0改写大模型性价比规则
【免费下载链接】Ring-flash-2.0  项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
导语
当大模型行业还在为参数规模竞赛焦灼时,蚂蚁集团用Ring-flash-2.0撕开了新的突破口——以1000亿总参数、仅61亿激活参数的极致配置,在数学推理、代码生成等核心任务上超越400亿参数以内稠密模型,每百万token推理成本降至0.7美元。这个搭载独创"棒冰算法"的开源模型,正将大模型竞争带入"效能比"决胜的新阶段。
行业现状:从参数军备赛到效能革命
2025年的大模型战场呈现出鲜明的"马太效应":头部闭源模型凭借万亿参数持续垄断高端市场,而开源社区在400亿参数以下形成激烈红海。据《AI大模型效能白皮书》数据,主流开源模型平均激活参数利用率不足4%,"大而不强"的参数冗余问题严重制约产业落地。正是在这样的背景下,蚂蚁集团继Ling-flash-2.0之后,再次抛出重磅开源成果——Ring-flash-2.0,用"超稀疏MoE+长周期RL"的技术组合,将推理型大模型的性价比推至新高度。
核心亮点:三大技术突破重构推理范式
1. 独创冰pop算法:让强化学习"长跑不崩"
大模型领域长期存在"训练 instability悖论":强化学习(RL)是提升推理能力的关键,但MoE架构在长思维链训练中极易出现梯度爆炸。Ring-flash-2.0的解决方案堪称精妙——通过"双向截断+掩码修正"的冰pop算法,形象地说就是"把训推精度差异过大的token实时冻结"。

如上图所示,传统GRPO算法在训练18天后即出现显著震荡并最终发散,而采用冰pop算法的模型在60天训练周期中损失函数持续平稳下降。这一突破使得模型能够充分吸收20万亿token预训练数据中的推理模式,为后续性能跃升奠定基础。
2. 超稀疏激活架构:61亿参数实现40B级性能
Ring-flash-2.0延续了Ling系列的高效MoE设计,通过1/32的超低专家激活比(每层仅激活3.125%的专家网络)和多任务感知路由(MTP)层优化,实现了"小激活大能力"的跨越。在硬件需求上,该模型仅需4张H20 GPU即可部署,生成速度达200+token/s,较同等性能稠密模型降低60%算力成本。
3. 三阶训练体系:从"学会思考"到"精准表达"
蚂蚁团队为Ring-flash-2.0构建了循序渐进的能力进化路径:首先通过长思维链监督微调(Long-CoT SFT)注入数学证明、代码调试等四大领域的推理模式;接着采用可验证奖励强化学习(RLVR),通过符号执行器验证每步计算正确性,将推理能力逼至极限;最后通过人类反馈强化学习(RLHF)优化格式规范性与阅读流畅度。这种"先算对、再做好"的训练策略,使模型在保持推理优势的同时具备良好的实用体验。
性能表现:跨领域榜单全面领先
在权威基准测试中,Ring-flash-2.0展现出令人惊叹的"以小胜大"能力:在AIME数学竞赛中获得86.98分,超越GPT-OSS-120B(medium);CodeForces编程竞赛elo评分达90.23,与Gemini-2.5-Flash持平;GSM8K数学推理准确率82.3%,显著优于Qwen3-32B。更值得注意的是,尽管主打推理能力,该模型在创意写作(Creative Writing v3)任务中仍超越所有对比开源模型,打破了"推理与创造不可兼得"的固有认知。
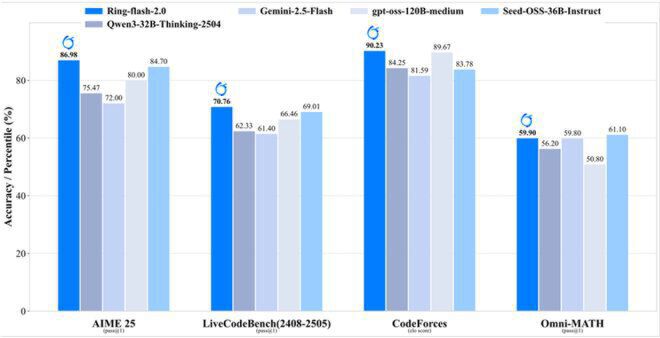
如上图所示,Ring-flash-2.0在数学推理(AIME 25)、代码生成(LiveCodeBench)、编程竞赛(CodeForces)和综合数学(Omni-MATH)四大权威榜单上均处于领先位置。这种全栈式性能提升,印证了高效MoE架构与长周期RL训练结合的技术价值。
行业影响:开源生态的"鲶鱼效应"
Ring-flash-2.0的开源(项目地址:https://gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0)不仅提供预训练权重,更完整开放了冰pop算法实现、三阶训练流水线和vLLM/SGLang推理优化方案。这种"全链路开源"策略将产生三重行业影响:
- 技术普惠:中小企业和研究机构可低成本复现400亿级推理能力,加速垂直领域应用落地
- 范式转移:推动开源社区从参数规模竞赛转向激活效率优化,预计2025年底相关模型占比将超60%
- 生态重构:促使硬件厂商针对稀疏激活场景优化芯片设计,加速AI算力供给侧改革
部署指南:五分钟上手高性能推理
Ring-flash-2.0提供多框架部署支持,以下是vLLM推理的快速启动代码:
# 环境准备
git clone -b v0.10.0 https://gitcode.com/hf_mirrors/vllm-project/vllm.git
cd vllm
wget https://gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0/raw/main/bailing_moe_v2.patch
git apply bailing_moe_v2.patch
pip install -e .
# 启动服务
python -m vllm.entrypoints.openai.api_server \
--model https://gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0 \
--tensor-parallel-size 4 \
--dtype bfloat16 \
--host 0.0.0.0 \
--port 8000
结语:效能比决定下一阶段竞争格局
Ring-flash-2.0的开源犹如一剂强心针,为陷入参数军备赛的大模型行业提供了新的发展思路。当61亿激活参数就能实现400亿级性能时,我们或许需要重新定义"大模型"的评价标准——不再是单纯的参数数字游戏,而是如何用更聪明的架构设计和训练策略,释放AI的真正潜能。对于开发者而言,现在正是拥抱这一变革的最佳时机:
🚀 立即体验:https://gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
📚 技术文档:项目README包含完整部署教程与API说明
💡 应用建议:优先探索数学推理、代码生成、长文本分析等场景
随着冰pop算法等核心技术的开源,我们有理由相信,大模型普惠化的时代正在加速到来。你准备好用61亿参数撬动怎样的AI创新?

如上图所示,Ring-flash-2.0的混合架构融合了稀疏MoE与线性注意力机制,通过Token Embedding层、Grouped-Query Attention、MoE专家选择等模块的协同优化,实现了性能与效率的完美平衡。这种架构设计为下一代推理型大模型提供了重要参考范式。
【免费下载链接】Ring-flash-2.0 项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







