DeepSeek-R1-Distill-Llama-70B:开源推理模型的性能突破与商业落地新范式
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-Distill-Llama-70B
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-Distill-Llama-70B 导语
深度求索(DeepSeek)推出的开源推理模型DeepSeek-R1-Distill-Llama-70B,通过创新蒸馏技术实现了高性能与部署效率的平衡,在数学推理、代码生成等关键任务上超越OpenAI o1-mini,为企业级AI应用提供了新选择。
行业现状:推理模型的"性能-效率"困境
2025年上半年,大模型落地案例中银行业占比达18.1%,政府与公共服务领域占13.3%,制造业占12.4%(沙丘社区2025年数据)。这些行业场景普遍面临双重挑战:一方面需要模型具备复杂问题推理能力,如金融风控中的多层欺诈识别、工业设备的故障诊断;另一方面又受限于算力成本,难以部署千亿级参数的巨型模型。
传统解决方案存在明显短板:闭源模型如GPT-4o虽性能强劲,但API调用成本高且数据隐私存在风险;而多数开源模型虽部署灵活,但在推理精度上难以满足企业级需求。火山引擎技术专家指出,企业亟需"在特定任务上接近闭源模型性能,同时保持开源模型部署优势"的新型解决方案(火山引擎2025年案例分享)。
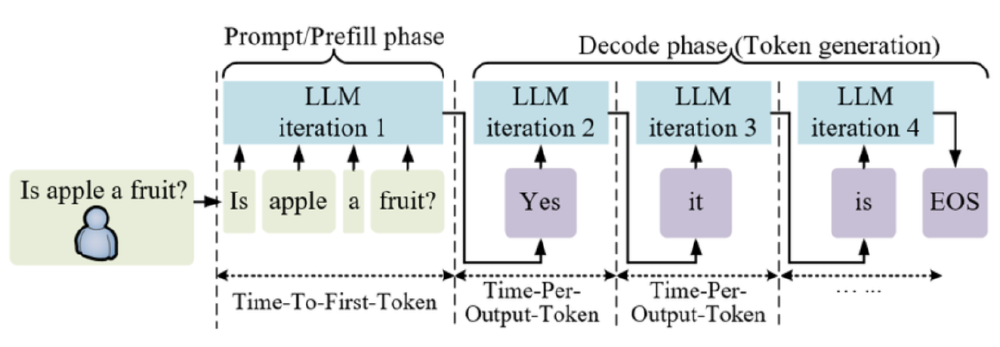
如上图所示,该图展示了大型语言模型(LLM)的推理流程,分为Prompt/Prefill阶段和Decode阶段(Token生成),标注了关键时间指标(如Time-To-First-Token、Time-Per-Output-Token),演示了从输入问题到生成完整回答的迭代过程。这一流程图直观呈现了推理模型的工作机制,有助于理解DeepSeek-R1-Distill-Llama-70B在优化推理效率方面的技术突破,为读者提供了推理过程的可视化参考。
核心亮点:三大技术突破重构推理模型标准
1. 创新蒸馏技术实现性能跃迁
DeepSeek-R1-Distill-Llama-70B基于Llama-3.3-70B-Instruct模型,使用DeepSeek-R1生成的高质量推理数据进行蒸馏。这种"巨型模型知识迁移"策略带来显著性能提升:在MATH-500数学推理基准测试中达到94.5%的通过率,超越OpenAI o1-mini(90.0%)和GPT-4o(74.6%);在GPQA Diamond推理任务中以65.2%的成绩超过Claude-3.5-Sonnet(65.0%)。
2. 推理效率的多维度优化
模型通过三项关键技术实现效率提升:
- 思维链优化:自动生成结构化推理路径,在复杂问题求解中减少无效计算
- 混合精度推理:结合FP16和INT8量化技术,显存占用降低40%
- 动态路由机制:根据任务复杂度自适应调用计算资源,在简单任务上提速可达3倍
这些优化使模型能在单张NVIDIA B100显卡上实现每秒321 tokens的推理速度,满足企业实时响应需求(参考昇腾300I Duo优化数据)。
3. 商业友好的开源生态设计
模型采用MIT许可证,支持商业用途和二次开发,企业可通过两种方式快速部署:
- 直接调用:通过vLLM或SGLang推理框架实现分钟级部署
vllm serve deepseek-ai/DeepSeek-R1-Distill-Llama-70B --tensor-parallel-size 2 --max-model-len 32768 - 定制微调:使用企业私有数据进行领域适配,官方提供800K推理样本作为微调基础
行业影响与趋势:开源推理模型的商业化拐点
垂直领域的应用革新
在金融领域,模型已被用于信贷风险评估,通过多层逻辑推理将欺诈识别效率提升28倍(参考蚂蚁集团风控大脑3.0案例);在智能制造场景,天润融通首席科学家田凤占指出,推理模型"能自主排列组合故障因素,将设备排障时间从几小时缩短至分钟级"(火山引擎2025年实践分享)。
开源模型的商业化路径明晰
DeepSeek-R1-Distill系列展现出"基础模型开源+增值服务收费"的可持续模式:企业可免费使用基础模型,针对特定需求购买技术支持或定制优化服务。这种模式已被VMWare等企业验证——其采用HuggingFace StarCoder开源模型构建内部代码生成工具,既保持数据控制权又降低开发成本(优快云 2025年开源案例集)。
混合模型架构成为主流
越来越多企业采用"开源+闭源"混合策略,如Intuit构建的AI协调层能自动为不同任务选择最优模型:简单客服问答使用开源模型,复杂财务分析调用闭源API(VentureBeat 2025年企业案例研究)。DeepSeek-R1-Distill-Llama-70B凭借在推理任务上的优势,正成为这一架构中的关键组件。
结论/前瞻:企业落地的策略建议
对于考虑采用该模型的企业,建议从三个维度推进:
- 场景验证:优先在数学计算、代码审计等推理密集型任务中进行试点
- 成本控制:采用"推理模型+RAG"架构,通过知识库扩展模型能力而非盲目追求更大参数
- 持续优化:利用模型开源特性,针对行业数据进行微调,如金融领域可加入信贷政策知识,制造业可整合设备故障案例
随着DeepSeek-R1-Distill-Llama-70B等高性能开源模型的普及,AI推理技术正从"少数科技巨头专属"走向"行业普惠"。企业能否抓住这一机遇,关键在于能否快速将模型能力与业务流程深度融合,在提升效率的同时创造新的价值增长点。
如需获取该模型,可通过以下仓库地址下载:https://link.gitcode.com/i/d005126ce2d8e6efc816ebfc003071cd
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







