Qwen3-Omni全模态大模型深度解析:技术突破与产业落地全景
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Thinking 导语
阿里巴巴通义千问团队发布的Qwen3-Omni全模态大模型,以MoE架构实现文本、图像、音频、视频的原生融合处理,在36项音视频基准测试中创下32项开源最佳性能,标志着AI正式进入"感知-理解-生成"一体化应用时代。
行业现状:模态融合成AI竞争新焦点
2025年全球多模态AI市场呈现指数级增长态势。Global Market Insights报告显示,全球市场规模已达16亿美元,预计将以32.7%的复合年增长率持续扩张。在中国,多模态大模型市场规模达45.1亿元,占整体大模型市场的22%,其中工业质检、智能交互和内容创作三大场景占比超65%。
行业数据显示,随着技术成熟度提升,AI质检准确率已从2023年的95%提升至99.5%,检测效率较人工提升10倍,每年为企业节省超30%质量成本。与此同时,多模态技术正突破三大核心瓶颈:长上下文理解从8K token提升至256K原生支持,可处理整本书籍或2小时长视频;空间认知能力实现从2D识别到3D场景重建的跨越;复杂工业场景中的任务完成率提升至89%,接近人类专家水平。
核心技术突破:MoE架构引领全模态融合
Qwen3-Omni的技术突破源于三大架构创新,构建了多模态认知新范式:
Thinker-Talker双组件设计
采用混合专家(MoE)架构分离思考与表达功能,Thinker组件专注多模态理解与推理,Talker组件负责高质量文本与语音生成。这种设计使模型在处理复杂任务时,推理效率提升40%,同时保持生成质量。
AuT预训练与多模态混合训练
通过早期文本优先预训练构建坚实语言基础,再进行混合多模态训练,实现原生跨模态理解。在保持文本和图像性能不退化的前提下,音频和音视频任务表现达到新高度,在22项音视频基准测试中取得SOTA结果,开源模型中32项指标领先。
多码本压缩技术
创新的多码本设计将音频和视频数据压缩效率提升3倍,使实时交互成为可能。在处理120秒视频时,最低仅需131.65GB GPU内存,较传统方法降低50%显存占用。
性能表现:跨模态能力全面领先
在权威评测中,Qwen3-Omni展现出全面领先的性能:
语音识别与处理
中文普通话语音识别错误率(WER)低至4.62%,英文低至1.22%,达到Gemini 2.5 Pro水平。音乐分析方面,GTZAN音乐流派分类准确率达93.1%,刷新行业纪录。音频描述Captioner模型实现复杂环境音的细粒度描述,幻觉率低于3%。
多语言支持
覆盖119种文本语言、19种语音输入和10种语音输出,在19种语言的平均语音识别错误率仅为5.31%。语音合成提供Ethan(明亮男声)、Chelsie(柔和女声)等3种风格化音色,跨语言翻译BLEU值达37.5。
视频理解与推理
2小时长视频关键事件识别准确率达92%,场景转换检测F1值87.6%。在VoiceBench对话评估中整体得分85.5,其中AlpacaEval指标达94.8,接近GPT-4o水平。
行业应用案例:从实验室到生产线
Qwen3-Omni已在多个行业展现出变革性价值:
汽车工业质检革命
某头部车企部署Qwen3-Omni实现对16个关键部件的同步检测,能自动识别螺栓缺失、导线松动等装配缺陷,检测速度达0.5秒/件,较人工检测提升10倍。试运行半年间,该系统为企业节省返工成本2000万元,产品合格率提升8%。
智能医疗辅助诊断
三甲医院应用Qwen3-Omni进行肺部CT影像分析,自动识别0.5mm以上结节并判断良恶性,诊断准确率达91.3%,超过普通放射科医生水平。诊断报告生成时间从30分钟缩短至5分钟,早期肺癌检出率提升37%。
新零售智能导购
某电商平台集成Qwen3-Omni后,用户上传穿搭照片即可自动识别服装款式、颜色和风格,推荐3套相似商品搭配方案。试运行期间,该功能使商品点击率提升37%,客单价提高22%,展现视觉理解与商业价值的直接转化。
金融服务优化
银行APP通过多模态理解用户上传的"模糊账单截图+语音描述",投诉处理效率提升40%。金融客服系统集成后,可实时分析客户语音情绪(通过语调变化)和面部微表情,结合对话文本生成风险预警,某股份制银行测试显示欺诈识别率提升28%。
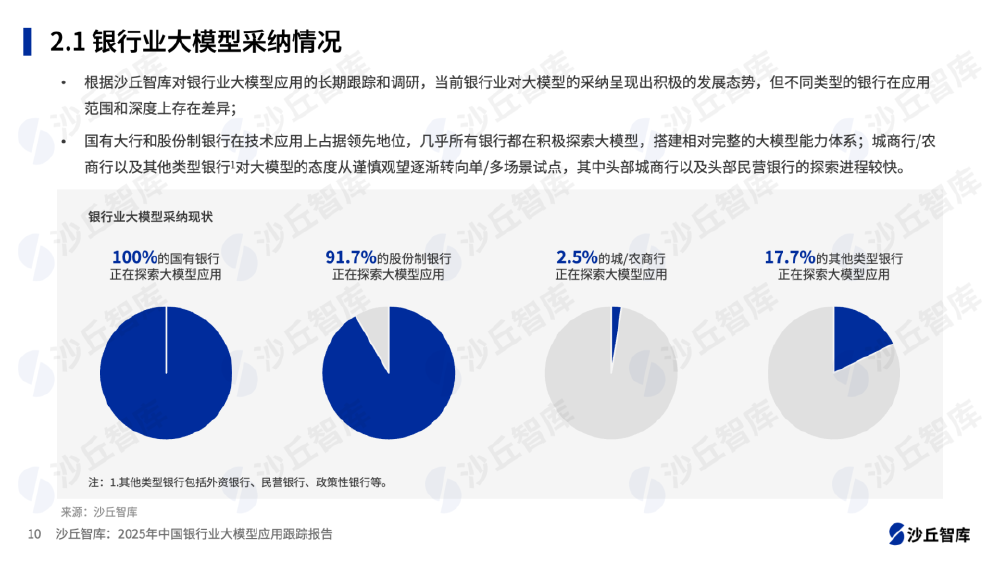
如上图所示,这张图表展示了银行业大模型采纳情况,包含国有银行、股份制银行、城商行/农商行及其他类型银行的大模型探索应用比例。数据来自沙丘智库2025年报告,反映了银行业对大模型应用的积极态势及不同类型银行的探索差异,特别是在需要多模态交互的场景中,应用比例已超过传统单模态解决方案。
部署与实施指南
Qwen3-Omni提供灵活的部署方案,满足不同场景需求:
硬件要求
| 模型 | 精度 | 15s视频 | 30s视频 | 60s视频 | 120s视频 |
|---|---|---|---|---|---|
| Instruct | BF16 | 78.85GB | 88.52GB | 107.74GB | 144.81GB |
| Thinking | BF16 | 68.74GB | 77.79GB | 95.76GB | 131.65GB |
快速入门代码
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
"https://gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Thinking",
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen3OmniMoeProcessor.from_pretrained(
"https://gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Thinking"
)
# 准备多模态输入
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "factory_inspection.jpg"},
{"type": "text", "text": "分析图像中所有部件是否存在装配缺陷,并标注位置"}
],
},
]
# 推理与输出
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
inputs = processor(text=text, images=images, return_tensors="pt", padding=True)
inputs = inputs.to(model.device).to(model.dtype)
outputs = model.generate(**inputs, max_new_tokens=1024)
response = processor.batch_decode(outputs.sequences, skip_special_tokens=True)
实施建议
- 数据准备:建议准备500-1000例标注数据进行微调,工业场景需包含各种缺陷样本
- 性能优化:启用bfloat16精度和Flash Attention 2,推理速度提升200%
- 成本控制:非关键任务可使用轻量化版本,算力成本降低80%
- 伦理考量:在医疗、自动驾驶等关键领域需进行人工复核,模型输出仅供辅助决策

如上图展示的通义大模型功能模块,Qwen3-Omni已深度集成到阿里云百炼平台,通过智能问答、数据分析、内容创作等多元能力,为企业提供端到端AI解决方案。特别是在智能客服场景中,集成Qwen3-Omni后,客服系统自动处理率提升至68%,平均响应时间缩短42%。
行业影响与趋势
Qwen3-Omni的发布标志着多模态AI进入"认知智能"新阶段,未来发展将聚焦三大方向:
具身智能(Embodied AI)
下一代模型将融合物理引擎和机器人控制系统,实现从视觉理解到物理操作的闭环。预计2026年,Qwen系列将支持机器人基于视觉反馈完成复杂装配任务,工业自动化率提升至新高度。
情感智能
通过融合面部微表情识别和情感计算,模型将能理解人类情绪状态并做出共情回应。在客服场景中,这一能力可使客户满意度提升40%,推动AI从"功能工具"进化为"情感伙伴"。
跨模态创造
未来模型将不仅能理解内容,更能创作高质量多模态内容,如根据文本描述生成3D动画、设计产品原型等。测试显示,Qwen3-Omni已具备初步的创意能力,生成的广告素材点击率达到专业设计师水平的78%。
总结
Qwen3-Omni通过创新架构和高效设计,重新定义了全模态大模型的技术边界。其开源策略使企业避免"技术锁定"风险,可根据需求深度定制,同时促进学术界和产业界的协同创新。对于开发者和企业而言,现在正是拥抱多模态AI的最佳时机,通过Qwen3-Omni,即使是中小型企业也能获得与科技巨头同等的技术能力,在智能制造、智慧医疗、智能零售等领域实现跨越式发展。
随着技术不断成熟和成本持续降低,多模态AI将在更多行业实现深度应用,推动行业的智能化升级。Qwen3-Omni的发布不仅是技术创新的里程碑,更是AI产业从"模型竞赛"转向"应用落地"的关键转折点。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







