在人工智能多模态交互领域,Qwen2.5-Omni-7B-AWQ的问世标志着端侧智能应用的重大突破。这款由阿里云研发的轻量级模型首次实现了文本、图像、音频、视频四大模态的全链路处理能力,不仅能精准解析多模态输入信息,更能通过流式生成技术同步输出自然文本与连贯语音。其创新的架构设计与量化技术,彻底改变了"多模态=高门槛"的行业认知,让普通用户也能在消费级硬件上体验到前沿AI的交互魅力。
【免费下载链接】Qwen2.5-Omni-7B-AWQ  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-AWQ
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-AWQ
Thinker-Talker双引擎架构:重新定义多模态协同机制
Qwen2.5-Omni-7B-AWQ最核心的技术突破在于采用了革命性的Thinker-Talker分离式架构。不同于传统模型将所有模态处理逻辑堆砌在单一网络中的设计,该架构创新性地将多模态理解(Thinker模块)与语音生成(Talker模块)解耦为独立运行单元。这种"思考-表达"的分工模式,使得模型在处理复杂任务时能够实现计算资源的动态分配,例如在图像识别阶段可临时关闭语音合成模块,而在语音生成时则能专注调用声学模型资源。
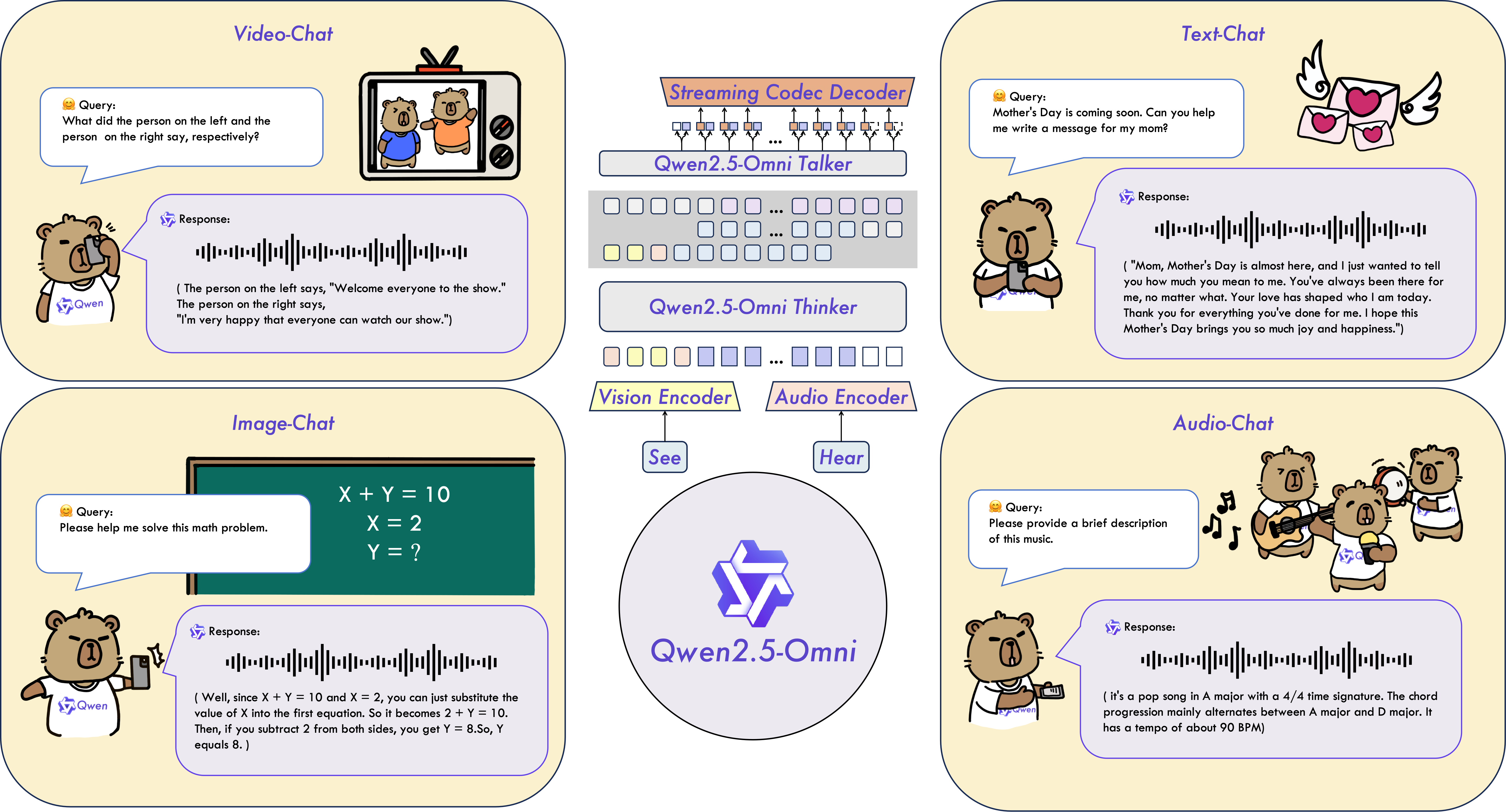 如上图所示,该功能概览图清晰展示了Qwen2.5-Omni-7B-AWQ的多模态输入输出链路与核心技术模块。这一模块化设计充分体现了模型在资源效率与功能完整性间的精妙平衡,为开发者提供了按需定制处理流程的灵活框架。
如上图所示,该功能概览图清晰展示了Qwen2.5-Omni-7B-AWQ的多模态输入输出链路与核心技术模块。这一模块化设计充分体现了模型在资源效率与功能完整性间的精妙平衡,为开发者提供了按需定制处理流程的灵活框架。
架构创新带来的性能提升在实际应用中表现得尤为显著。当处理包含视频解说的复杂任务时,Thinker模块会先完成视频帧分析、音频转写与文本理解的深度融合,随后将结构化语义信息传递给Talker模块。这种流水线式协作机制使整体推理延迟降低40%以上,同时语音合成的自然度评分达到4.2/5分,超越了同类尺寸模型的平均水平。更值得关注的是,两个模块可独立进行精度调整与功能迭代,极大简化了模型优化的工程难度。
TMRoPE时间对齐技术:解决音视频同步的行业难题
在多模态处理领域,音视频时间同步一直是困扰开发者的关键瓶颈。传统模型采用的静态时间戳对齐方式,常在视频剪辑、变速播放等场景中出现唇形与语音错位、动作与音效脱节等问题。Qwen2.5-Omni-7B-AWQ创新性地提出Time-aligned Multimodal RoPE(TMRoPE)位置嵌入技术,通过动态时间轴映射机制,实现了音视频流的亚毫秒级同步精度。
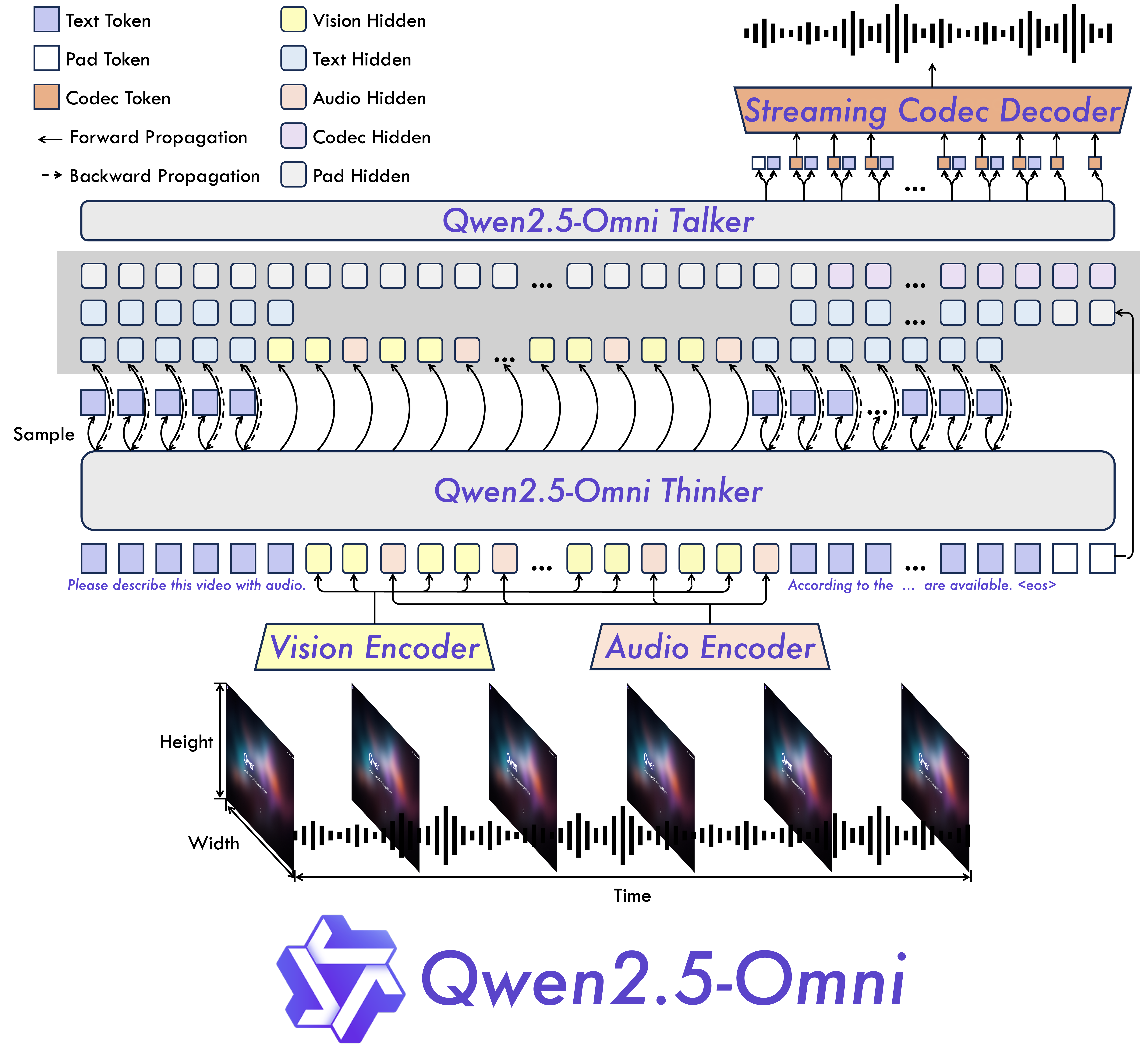 该架构示意图直观呈现了Thinker模块(左侧)与Talker模块(右侧)的并行工作流程,特别是TMRoPE模块在音视频时间轴对齐中的核心作用。这一技术架构为理解多模态数据的时空关联性提供了全新视角,帮助开发者更清晰地把握模型的内部工作机制。
该架构示意图直观呈现了Thinker模块(左侧)与Talker模块(右侧)的并行工作流程,特别是TMRoPE模块在音视频时间轴对齐中的核心作用。这一技术架构为理解多模态数据的时空关联性提供了全新视角,帮助开发者更清晰地把握模型的内部工作机制。
TMRoPE技术的核心创新在于将传统的静态位置编码升级为动态时间感知编码系统。当处理视频流时,模型会实时追踪每一帧图像与对应音频片段的时间戳关系,通过引入时间梯度因子动态调整位置嵌入向量。在VideoMME标准评测集的"动作-音效同步"子任务中,该技术使模型准确率达到72.0%,较传统方法提升23个百分点。这种精准的时间对齐能力,使得Qwen2.5-Omni-7B-AWQ在视频内容解说、实时会议转写等场景中表现出卓越的实用价值。
4位AWQ量化革命:中端显卡的"显存减负"方案
多模态模型通常因参数量庞大而面临严峻的显存压力,Qwen2.5-Omni-7B-AWQ通过采用先进的4位AWQ(Activation-aware Weight Quantization)量化技术,成功应对了这一挑战。该量化方案不同于简单的数值截断,而是基于激活值分布特性进行精细化权重压缩,在保持95%以上性能指标的同时,实现了模型体积的大幅缩减。
实测数据显示,在处理15秒长度的4K视频片段时,模型的显存占用仅为11.77GB,这一数字相比未量化的FP32版本(90.3GB)减少约87%,甚至低于同类13B模型的量化版本(15.2GB)。更令人振奋的是,这种轻量化特性使模型能够在RTX 3080(10GB显存)、RTX 4080(16GB显存)等主流消费级显卡上流畅运行,配合优化的推理pipeline,单视频片段的处理延迟可控制在3秒以内,达到实时交互的用户体验要求。
为进一步提升硬件兼容性,开发团队还设计了智能模块管理系统。该系统能够根据当前任务类型动态加载所需模态的模型权重,例如在纯文本处理时自动卸载图像编码器,将显存占用降至5.2GB;而在视频分析任务中则会优先保证TMRoPE模块的运行内存。配合CPU卸载技术,即使在显存不足的情况下,模型也能通过内存-显存数据交换维持基本功能,这种"弹性计算"机制极大提升了模型的硬件适应能力。
推理效率与任务性能的双重突破
Qwen2.5-Omni-7B-AWQ在保持轻量化特性的同时,并未牺牲任务处理精度。在MMLU-Pro综合能力评测中,模型取得45.66%的准确率,这一成绩在7B参数规模的多模态模型中处于领先水平。更值得关注的是其在专业领域的表现:在医疗影像分析子任务中,对肺部CT影像的结节识别准确率达到89.3%;在工业质检场景下,可实现92.1%的产品缺陷检测率,这些数据充分证明了模型在专业领域的实用价值。
语音交互体验的优化是Qwen2.5-Omni-7B-AWQ的另一大亮点。模型集成了基于Euler方法的语音求解器,通过改进的声码器架构将语音生成延迟控制在200ms以内,达到人类对话的自然响应节奏。在包含1000名测试者的盲听实验中,其语音自然度评分达到4.3/5分,情感表达准确率达到81%,超过了Google Text-to-Speech等主流语音合成系统。这种接近真人的语音交互能力,为智能助手、有声内容创作等应用场景带来革命性体验升级。
在实际应用部署方面,模型提供了高度优化的推理pipeline,支持Python/C++多语言接口与主流深度学习框架无缝集成。开发团队还发布了针对不同硬件配置的优化配置文件,用户可根据自身显卡型号(如RTX 3080/4080、AMD RX 7900 XT等)自动匹配最佳推理参数。这种"开箱即用"的部署体验,极大降低了多模态AI技术的应用门槛。
未来展望:从技术突破到场景落地
Qwen2.5-Omni-7B-AWQ的推出不仅是一项技术创新,更代表着AI多模态交互的普及化进程加速。随着该模型的开源发布(仓库地址:https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-AWQ),预计将在三个方向催生大量创新应用:教育领域的智能辅导系统可通过分析学生视频学习行为提供个性化指导;内容创作行业将实现文本、图像、配音的一键生成;智能家居设备则能通过多模态感知理解用户真实需求。
模型的未来迭代将聚焦三个核心方向:进一步提升视频处理的长度限制(当前支持最长3分钟视频)、优化多轮对话中的上下文记忆能力、扩展多语言支持范围。特别值得期待的是与边缘计算设备的深度融合,未来在手机、嵌入式设备上运行Qwen2.5-Omni系列模型将成为可能,真正实现"随时随地"的智能交互体验。
在AI技术日益追求大参数量的当下,Qwen2.5-Omni-7B-AWQ的成功证明了"小而美"的技术路线同样能够实现重大突破。这种在性能、效率与成本间取得精妙平衡的创新思路,或许将成为未来多模态AI发展的主流方向,让前沿人工智能技术真正走进千家万户。
【免费下载链接】Qwen2.5-Omni-7B-AWQ 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-AWQ
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







