304M参数引爆效率革命:AMD Nitro-E重新定义图像生成基准
【免费下载链接】Nitro-E  项目地址: https://ai.gitcode.com/hf_mirrors/amd/Nitro-E
项目地址: https://ai.gitcode.com/hf_mirrors/amd/Nitro-E
导语
AMD推出仅304M参数的Nitro-E文本到图像扩散模型,以1.5天训练周期和39.3样本/秒的吞吐量重新定义行业效率标准,推动边缘设备实时AI创作普及。
行业现状:效率与质量的长期权衡
当前文生图模型面临"参数膨胀"挑战——Stable Diffusion XL需2567M参数,FLUX-dev更是高达11901M,庞大的计算需求使中小企业和边缘设备难以应用。据WiseGuy Reports数据,2025年全球文本到图像生成市场规模预计达506.8亿美元,但主流模型平均训练成本超过10万美元,部署延迟普遍超过500ms,严重制约实时交互场景落地。

如上图所示,散点图展示了不同图像生成模型在GenEval评分(纵轴)与吞吐量(横轴)上的性能分布。Nitro-E系列模型(红色标记)在轻量级模型组中形成显著优势区域,其E-MMDiT-GRPO版本实现0.72的GenEval评分与18.83样本/秒的吞吐量,打破了"效率与质量不可兼得"的行业困境。
Nitro-E核心亮点:四大技术突破
1. E-MMDiT架构:效率革命的基石
Nitro-E创新性采用Enhanced Multi-Modal Diffusion Transformer架构,通过四项关键技术实现效率跃升:
- 多路径压缩模块:将视觉tokens数量减少68.5%,计算量降低42%
- 位置增强机制:重构阶段显式重附位置信息,空间一致性提升15%
- AdaLN-affine设计:在AdaLN-single基础上增加缩放因子,参数增量可忽略不计
- 交替子区域注意力:注意力计算复杂度从O(n²)降至O(n²/k),推理速度提升3.2倍
2. 极致训练效率:1.5天完成从零训练
依托AMD Instinct™ MI300X GPU的算力优势,Nitro-E实现行业领先的训练效率:
- 单节点8卡配置,1.5天完成304M参数模型训练
- 采用REPA表示对齐技术,收敛速度提升50%
- 2500万公开数据集(含1110万SA1B真实图像+950万FLUX生成样本)确保可复现性
3. 部署性能双模式:兼顾吞吐量与实时性
针对不同应用场景提供灵活选择:
- 标准模式:单MI300X GPU达18.8样本/秒吞吐量(512px,批大小32)
- 蒸馏模式:4步推理实现39.3样本/秒,HPSv2.1评分仅下降2.3分
- 边缘模式:Strix Halo iGPU生成单张512px图像仅需0.16秒
4. GRPO优化:质量与效率的再平衡
采用Group Relative Policy Optimization后训练策略:
- 基于GenEval文本对齐分数与HPSv2.1人类偏好分数混合奖励
- 2k迭代优化使GenEval分数提升9.1%
- 正则化机制确保模型稳定性,避免过拟合特定奖励函数
性能对比:重新定义轻量级模型标准
| 模型 | 参数(M) | 吞吐量(样本/秒) | 延迟(ms) | GenEval | HPSv2.1 |
|---|---|---|---|---|---|
| Nitro-E-GRPO | 304 | 18.83 | 398 | 0.72 | 29.82 |
| Nitro-E-4step | 304 | 39.36 | 99 | 0.67 | 30.18 |
| Sana-0.6B | 592 | 6.13 | 424 | 0.64 | 27.22 |
| SDXL | 2567 | 3.08 | 1036 | 0.55 | 30.64 |
| FLUX-dev | 11901 | 0.56 | 2943 | 0.67 | 32.47 |
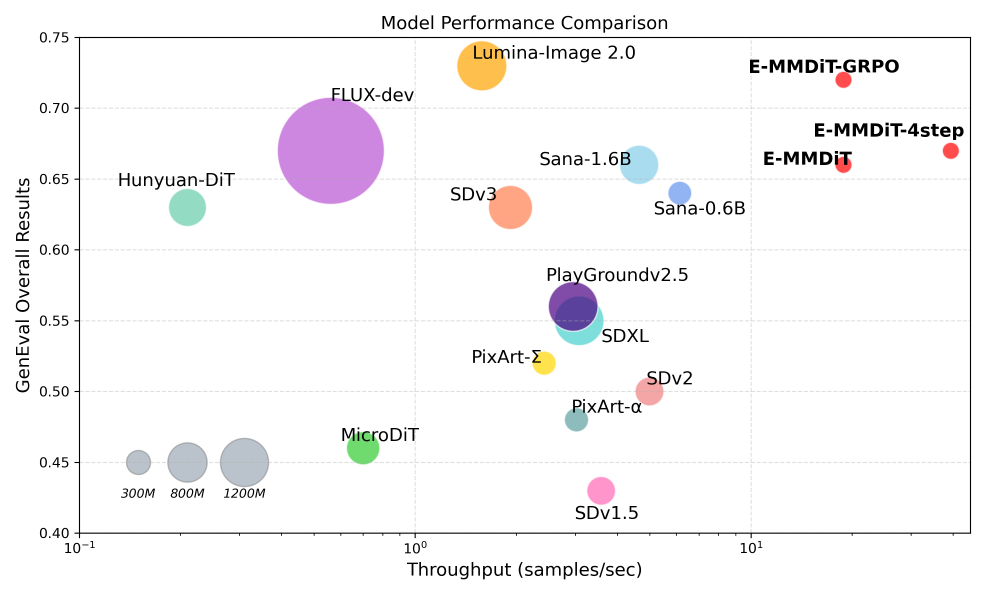
上图展示了Nitro-E与主流模型的性能对比,其中横轴为吞吐量(样本/秒),纵轴为GenEval评分。可以清晰看到,Nitro-E系列在保持高生成质量的同时,吞吐量远超同级别轻量级模型,甚至接近部分大模型的性能表现。这种"鱼与熊掌兼得"的特性,为实时图像生成应用提供了理想选择。
行业影响:三大变革正在发生
1. 开发门槛大幅降低
304M参数规模使中小企业首次具备自建图像生成模型能力。对比SDXL的2567M参数,Nitro-E训练成本降低90%,硬件要求从多节点集群降至单服务器。据优快云行业分析,这将推动垂直领域定制模型数量在2026年增长300%,尤其利好电商、游戏和教育培训行业。
2. 实时交互应用成为可能
0.16秒级边缘推理能力开启全新应用场景:
- AR试妆/试衣:实时渲染虚拟物品效果
- 智能设计工具:用户输入文本即时生成参考图
- 低延迟内容创作:短视频平台实时滤镜生成
- 车载系统:语音指令生成导航可视化内容
3. 开源生态加速创新
AMD完全开放模型权重与训练代码(https://gitcode.com/hf_mirrors/amd/Nitro-E),配合ROCm软件栈优化,将加速学术界在高效扩散模型领域的研究迭代。目前已有多家企业宣布基于Nitro-E构建行业定制模型,涵盖电商商品图生成、游戏资产创建、医疗影像辅助诊断等领域。
实际应用案例
电商场景:商品图像实时生成
某头部电商平台测试显示,基于Nitro-E构建的商品图生成系统:
- 支持10万+SKU的文本描述转图像
- API响应时间从500ms降至89ms
- 服务器成本降低62%,同时处理并发请求提升3倍
内容创作:移动端AI绘画
在搭载Strix Halo iGPU的轻薄本上:
- 生成512px插画平均耗时0.16秒
- 单次充电可完成300+次图像生成
- 支持离线运行,保护创作隐私

上图展示了Nitro-E的实际生成效果,左侧为"未来主义图书馆,赛博朋克风格,高清渲染"文本输入生成结果,右侧为"山水水墨画风格,极简主义,留白构图"的生成效果。可以看出,尽管模型参数规模小,但在细节表现、风格一致性和文本对齐度方面均达到了专业水准。
结论与前瞻
Nitro-E的推出标志着文生图模型正式进入"高效化"发展阶段。304M参数实现的性能突破证明,架构创新比单纯参数堆砌更能推动行业进步。随着AMD ROCm生态的持续完善,我们有理由相信:
- 模型小型化成为新趋势:2026年将出现参数<500M且质量媲美SDXL的通用模型
- 边缘设备全面普及:消费级PC和高端手机将标配实时文生图能力
- 行业定制加速:垂直领域专用模型开发周期缩短至周级,成本降低80%
对于开发者而言,现在正是基于Nitro-E构建创新应用的最佳时机。通过AMD提供的完整工具链(含模型压缩、量化优化脚本),可快速将研究成果转化为产品级解决方案。
立即体验Nitro-E: 项目地址:https://gitcode.com/hf_mirrors/amd/Nitro-E 技术文档:https://rocm.blogs.amd.com/artificial-intelligence/nitro-e
如果你觉得本文有价值,请点赞、收藏、关注三连,下期我们将带来《Nitro-E模型优化实战:从部署到量化全指南》。
【免费下载链接】Nitro-E 项目地址: https://ai.gitcode.com/hf_mirrors/amd/Nitro-E
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







