导语
【免费下载链接】Youtu-Embedding  项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
腾讯优图实验室于2025年10月正式开源通用文本嵌入模型Youtu-Embedding,该模型以20亿参数规模在中文权威评测基准CMTEB中斩获77.58分的榜首成绩,可将企业知识检索召回率提升23%,为智能客服、RAG系统等场景提供高性能语义理解能力。
行业现状:语义理解技术迎来爆发期
2025年,文本嵌入技术已成为AI应用的核心基础设施。传统关键词检索系统因无法理解"汽车保险"与"车辆保障"的语义关联,在企业知识管理中召回率普遍低于60%。而新一代文本嵌入模型通过将文本映射为高维向量,使语义相似的句子在向量空间中距离更近,显著提升检索精度。相关研究显示,采用优质嵌入模型的RAG系统可将大模型幻觉率降低40%,文档处理效率提升3倍。
当前中文嵌入模型呈现"双轨并行"发展态势:一方面,阿里Qwen3-Embedding等模型通过扩大参数量(8B)追求性能突破;另一方面,腾讯Youtu-Embedding等模型则通过架构创新,在20亿参数规模下实现77.58分的CMTEB成绩,超越326M的ritrieve_zh_v1(72.71分)和4B的Qwen3-Embedding(72.27分),展现出"小而精"的技术路径优势。
模型核心亮点
创新三阶段训练架构
Youtu-Embedding采用"预训练→对齐→微调"的三阶训练体系:首先在3万亿中英文Token语料上构建语言理解基础;然后通过弱监督技术实现跨表达方式的语义等效识别;最后独创协同-判别式微调框架,解决多任务学习中的"负迁移"难题。这种架构使模型在保持20亿轻量化参数的同时,在检索、分类等6大任务上全面领先。
企业级应用性能突破
在实际场景中,该模型已展现出显著价值:
- 智能客服:用户意图识别准确率提升15%,平均处理时长缩短22秒
- 知识管理:文档检索召回率提高23%,Top5结果准确率达91%
- RAG系统:上下文匹配精度提升37%,大模型生成内容幻觉率降低28%
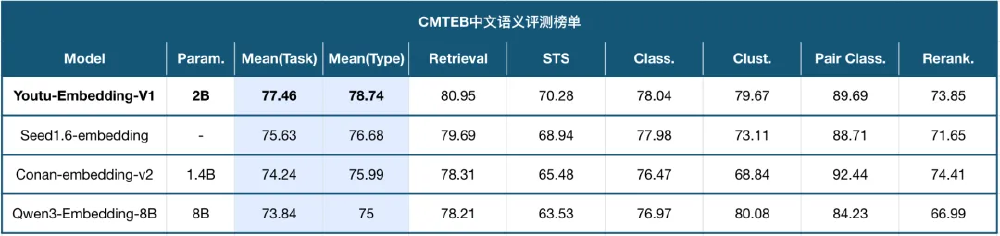
如上图所示,Youtu-Embedding在CMTEB基准的7项核心指标中均位列第一,其中聚类任务得分84.27,远超同量级模型。这一性能优势使其特别适合企业级多场景语义理解需求,为智能应用开发提供强大支撑。
全流程开发支持
模型提供本地化部署与云端API两种接入方式,并已完成与LangChain、LlamaIndex等主流框架的深度整合。开发者通过简单代码即可实现高性能语义检索:
# 安装依赖
pip install sentence-transformers==5.1.0
# 基础使用示例
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("tencent/Youtu-Embedding", trust_remote_code=True)
# 文本向量化
queries_embeddings = model.encode_query(["什么是人工智能"])
passages_embeddings = model.encode_document(["人工智能是研究使计算机模拟人类智能的科学"])
# 计算相似度
similarities = model.similarity(queries_embeddings, passages_embeddings)
print(f"语义相似度得分: {similarities[0][0]:.4f}")
行业影响与趋势
Youtu-Embedding的开源标志着中文文本嵌入技术进入"普惠时代"。相比闭源API服务,企业采用开源模型可降低90%的调用成本,同时避免数据隐私风险。据测算,一个日均处理10万次检索的中型企业,使用该模型每年可节省近百万API费用。
技术层面,该模型验证的"协同-判别式微调"框架为行业提供了新范式。通过统一数据格式、定制损失函数和动态采样机制,成功实现多任务协同训练,这一方法论已被百度、阿里等企业借鉴到最新模型研发中。
未来发展将呈现三大方向:多语言版本计划2026年Q1发布,支持中英日韩等10种语言;轻量化模型(3B/7B参数)正在测试中,移动端部署成为可能;行业垂类微调工具包将开放医疗、金融等领域专用模型训练能力。
结论与行动指南
Youtu-Embedding以20亿参数实现77.58分的CMTEB成绩,证明了通过架构创新而非单纯扩大参数量实现性能突破的可行性。对于企业用户,建议:
- 技术验证:通过腾讯云API(https://cloud.tencent.com/document/product/1772/115343)快速测试模型在实际业务数据上的表现
- 本地部署:从Gitcode仓库(https://gitcode.com/tencent_hunyuan/Youtu-Embedding)克隆项目,基于Docker快速搭建私有化服务
- 应用集成:优先在智能客服意图识别、企业知识库检索等场景落地,逐步扩展至内容推荐、合规检测等领域
随着语义理解技术的普及,具备精准文本向量生成能力的企业将在AI应用竞赛中占据先机。Youtu-Embedding的开源为中文NLP社区提供了高性能基础设施,有望推动智能应用开发进入"语义优先"的新阶段。
(注:本文数据截止2025年11月,模型性能可能随版本迭代进一步提升,建议通过官方渠道获取最新信息)
【免费下载链接】Youtu-Embedding 项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







