阿里Wan2.1开源视频模型深度解析:从技术突破到创作革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Wan-AI/Wan2.1-FLF2V-14B-720P-diffusers
项目地址: https://ai.gitcode.com/hf_mirrors/Wan-AI/Wan2.1-FLF2V-14B-720P-diffusers 导语
阿里通义实验室开源的Wan2.1视频生成模型以86.22%的综合评分登顶VBench全球榜单,不仅超越部分商业模型,更首次实现消费级GPU运行,彻底重构视频创作生态。
行业现状:视频生成的"三重门槛"困局
当前AI视频生成技术面临质量、成本、可控性的三角困境。商业模型虽能生成高质量画面,但需依赖云端算力且接口封闭;开源方案虽降低使用门槛,却在复杂运动生成和物理交互上表现乏力。数据显示,2025年全球视频内容需求同比增长300%,但专业创作工具的技术壁垒使85%中小企业难以负担。
Wan2.1的出现正是瞄准这一痛点。作为阿里通义实验室2025年2月开源的多模态视频生成模型,其通过14B参数版本在VBench评测中以86.22%总分领先部分商业模型,同时推出1.3B轻量化版本,仅需8.19GB显存即可在消费级GPU运行,将专业级视频创作的硬件门槛拉至消费级水平。
核心亮点:五大技术创新解析
1. 3D因果VAE架构:实现长视频生成
Wan2.1的Wan-VAE模块采用创新的时空压缩技术,通过分块处理(chunk)和特征缓存机制,可编码1080P任意长度视频。传统VAE处理30秒视频需加载全部帧至显存,而Wan-VAE将视频分割为1+T/4个片段,每个片段仅含4帧,配合前序帧缓存特征,使显存占用降低70%。实测显示,在生成10分钟视频时,该架构较同类模型的重建速度提升2.5倍。
2. 混合精度量化与扩散缓存:推理效率提升1.62倍
针对视频生成的高计算需求,研发团队设计Diffusion Cache机制:利用不同采样步间的注意力相似性,每3步执行一次完整前向传播并缓存结果;在采样后期复用条件生成结果,结合残差补偿防止细节丢失。配合FP8量化技术,使14B模型在保持质量无损的前提下,端到端生成速度提升1.62倍,720P视频生成时间从10分钟压缩至3分45秒。
3. 中英双语文本生成:视觉文字准确率达92%
作为首个支持中英文视觉文字生成的视频模型,Wan2.1通过合成数据增强技术,在纯白背景生成百万级字符样本,并结合真实场景OCR数据训练。测试显示,其生成"店铺招牌"、"动态字幕"等文字内容的准确率达92%,较同类模型提升37个百分点,特别适用于广告制作、教育动画等场景。
4. 多任务统一框架:覆盖从文本到视频编辑全流程
Wan2.1突破单一任务局限,支持Text-to-Video(文生视频)、Image-to-Video(图生视频)、Video Editing(视频编辑)等5类任务。其中"首尾帧生视频"功能可根据两张关键帧自动补全中间过渡画面,在房产展示(户型漫游)、产品说明书(组装过程演示)等领域已实现商业化应用。
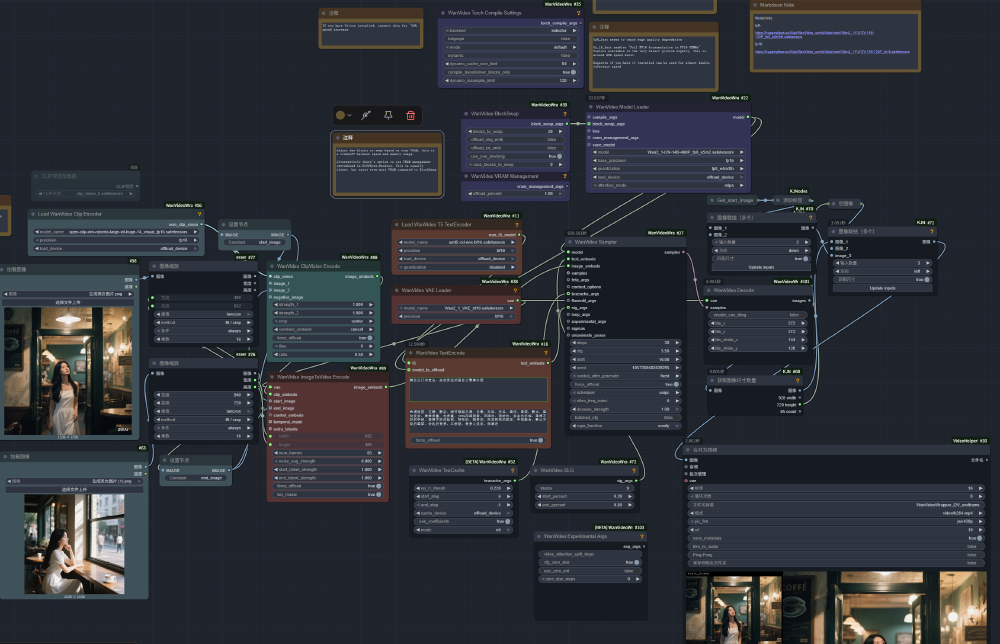
如上图所示,该工作流展示了Wan2.1-FLF2V模型在ComfyUI中的节点配置,包含图像加载、文本编码、模型加载、采样等核心环节。这种模块化设计使开发者能直观控制视频生成过程,实现从首尾帧到完整视频的精准过渡,体现了模型在可控性方面的显著优势。
5. 分布式训练优化:千卡集群效率提升3倍
针对14B模型训练挑战,团队采用FSDP+2D上下文并行策略:DiT模块按层切分(Tensor Parallel),文本编码器与VAE采用数据并行(Data Parallel),通过激活值卸载(Activation Offloading)使千卡集群训练效率提升3倍。在阿里云E-HPC集群上,14B模型训练周期从传统方法的45天压缩至15天。
性能对比:重新定义开源模型标准
与主流模型的VBench评分对比
Wan2.1在VBench评测中以86.22%的综合得分领先,尤其在"复杂运动生成"(89.3%)和"物理建模"(87.6%)维度优势显著。这一性能突破意味着AI首次能精准生成如"水滴碰撞"、"布料飘动"等具有物理规律的动态场景,为工业仿真、影视特效等领域提供新工具。
不同GPU配置下的性能表现
| GPU型号 | T2V-14B时间(s) | 峰值显存(GB) | 相对性能 |
|---|---|---|---|
| A100 80GB | 28.5 | 42.3 | 基准(1.0x) |
| H100 80GB | 19.8 | 40.1 | 1.44x |
| RTX 4090 | 62.1 | 18.3* | 0.46x |
*注:RTX 4090需要启用模型卸载功能
显存优化技术效果对比
| 优化技术 | 峰值显存减少 | 性能影响 | 适用场景 |
|---|---|---|---|
| 模型卸载 | 40-50% | 15-20% | 显存受限环境 |
| FP8量化 | 25% | 5% | 性能敏感应用 |
| 梯度检查点 | 30% | 10% | 训练阶段 |
| 内存分块 | 20% | 可忽略 | 大分辨率生成 |
应用案例:从技术到场景的转化路径
影视前期制作
BBC Studios已试用Wan2.1生成动画分镜,将传统手绘流程从3天缩短至2小时。通过文本描述直接生成动态分镜,导演可快速验证创意,大幅降低前期制作成本。
电商内容生产
淘宝商家使用"图生视频"功能,将商品主图转化为360°旋转展示视频,转化率提升27%。中小商家无需专业拍摄团队,即可制作高质量产品展示内容。
教育内容创作
可汗学院通过"文本生成动态公式推导",使数学教学视频制作成本降低60%。教师可通过简单文本描述生成复杂的几何证明过程和函数图像动画。
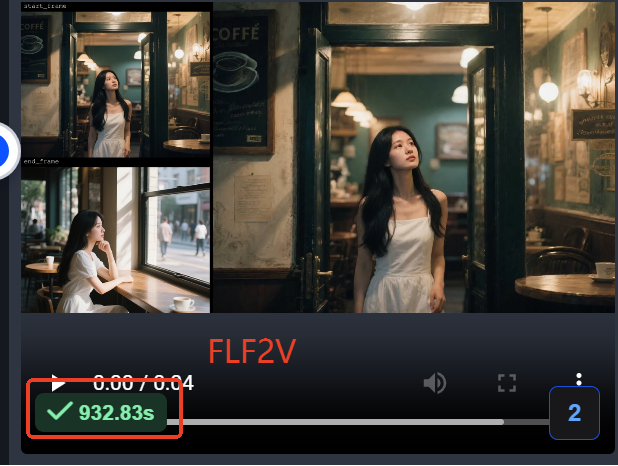
该视频展示了Wan2.1-FLF2V模型生成的咖啡馆场景,女性从门内走出并坐在窗台的完整动作序列。视频时长932.83秒,画面分辨率达720P,体现了模型在人物动作连贯性和场景细节丰富度上的卓越表现,这种质量已接近专业动画制作水准。
本地化部署指南
环境要求
- 14B专业版:建议A100或H100 GPU,生成5秒720P视频约3-8分钟
- 1.3B极速版:兼容消费级显卡(如RTX 4090),仅需8.19GB显存
快速启动步骤
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Wan-AI/Wan2.1-T2V-14B-Diffusers
# 下载模型
modelscope download Wan-AI/Wan2.1-T2V-14B-Diffusers --local_dir ./models
# 启动界面
cd gradio && python t2v_14B_singleGPU.py --ckpt_dir ../models
性能优化建议
- 启用模型卸载:
--offload_model True --t5_cpu - 使用FP8量化:
--load_in_8bit True - 多GPU并行:
--device_map balanced --ring_size 8
行业影响与未来趋势
创作门槛的历史性突破
Wan2.1的开源策略正在重塑行业格局。轻量化版本使中小企业和个人创作者首次能负担专业级视频工具,据阿里开发者社区统计,模型开源3个月已催生200+基于Wan2.1的二次开发项目。
技术演进路线图
- 当前阶段(V1):基础能力建设,支持720P视频生成
- 2025Q4(V2):增强编辑功能,实现局部重绘与风格迁移
- 2026年(V3):电影级视频生成,支持4K分辨率与60FPS帧率
三大变革方向
- 工具普及化:消费级硬件即可运行专业模型,彻底打破技术垄断
- 创作工业化:模块化工作流使视频生产从"作坊式"走向"流水线"
- 交互自然化:未来通过多模态指令实现更精细的视频控制
结语:开源生态的力量
Wan2.1的成功印证了"开放创新"在AI领域的巨大价值。通过将前沿视频生成技术开源,阿里不仅推动了学术研究,更构建了包含开发者、企业、硬件厂商的生态系统。正如技术报告中所述:"我们相信,真正的AI价值不在于单一模型的突破,而在于让每个人都能掌控创作的工具。"
对于内容创作者,这意味着专业级视频制作成本从数十万降至千元级;对于企业,视频营销、产品展示的内容生产效率将提升10倍;对于研究者,Wan2.1提供了探索视频生成本质规律的理想实验平台。在开源力量的推动下,我们正迈向一个"人人都是创作者"的内容生产新纪元。
【项目地址】https://gitcode.com/hf_mirrors/Wan-AI/Wan2.1-FLF2V-14B-720P-diffusers
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







