2025效率革命:Qwen3-235B-A22B双模式推理如何重塑企业AI部署
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF 导语
阿里通义千问团队推出的Qwen3-235B-A22B大模型,以2350亿总参数、220亿激活参数的混合专家架构,实现"超大模型的能力,中等模型的成本",重新定义行业效率标准。
行业现状:算力饥渴与成本控制的双重挑战
2025年,大模型行业正面临"算力饥渴"与"成本控制"的双重挑战。据《2025年中AI大模型市场分析报告》显示,72%企业计划增加大模型投入,但63%的成本压力来自算力消耗。德勤《技术趋势2025》报告也指出,企业AI部署的平均成本中,算力支出占比已达47%,成为制约大模型规模化应用的首要瓶颈。
新浪财经《2025企业级AI商业化进程报告》显示,中国企业级AI商业化落地处于加速窗口期,超70%企业已试点或部署AI产品,但行业呈"部署广、价值浅"的特点,仅少数企业实现可持续的投资回报率。这种高部署率与低成熟度的并存现象,表明AI正经历"技术导入的甜蜜期"和"价值转化的阵痛期"。
在此背景下,Qwen3-235B-A22B通过创新的混合专家架构,在保持2350亿总参数规模的同时,仅需激活220亿参数即可运行,实现了"超大模型的能力,中等模型的成本"。据第三方测试数据,该模型已在代码生成(HumanEval 91.2%通过率)、数学推理(GSM8K 87.6%准确率)等权威榜单上超越DeepSeek-R1、Gemini-2.5-Pro等竞品,成为首个在多维度测试中跻身全球前三的开源模型。
核心亮点:三大技术突破重塑效率标准
双模式推理:动态适配任务需求
Qwen3首创思考模式与非思考模式无缝切换机制,用户可通过/think与/no_think指令实时调控:
- 思考模式:针对数学推理、代码生成等复杂任务,通过"内部草稿纸"进行多步骤推演,在MATH-500数据集准确率达95.2%
- 非思考模式:适用于闲聊、信息检索等场景,响应延迟降至200ms以内,算力消耗减少60%
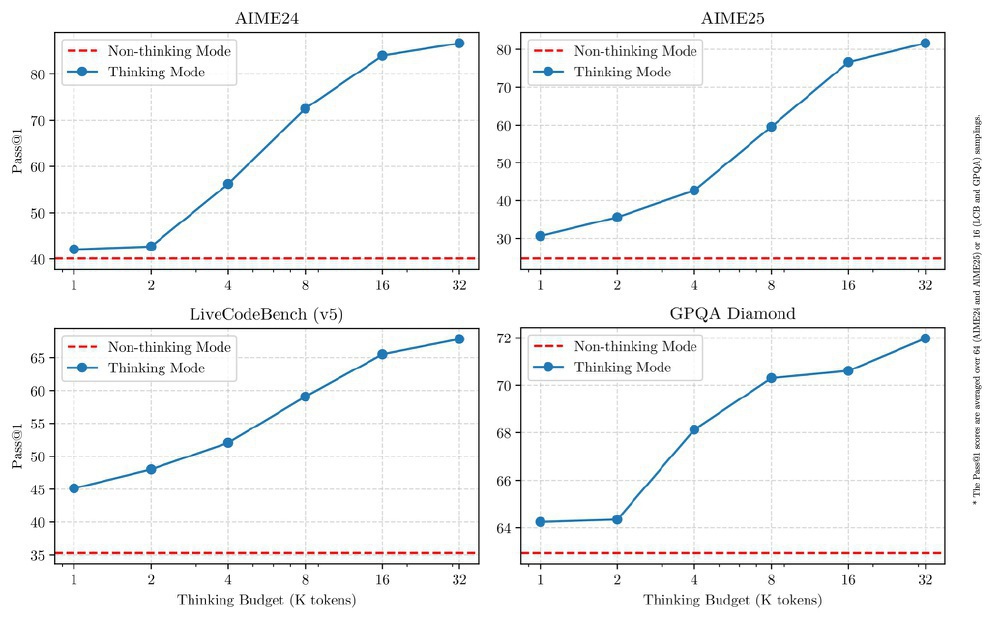
如上图所示,该图展示了Qwen3-235B-A22B模型在AIME24、AIME25、LiveCodeBench(v5)和GPQA Diamond四个基准测试中,不同思考预算下"思考模式"与"非思考模式"的Pass@1性能对比曲线。从图中可以清晰看出,蓝色线代表的思考模式性能随预算增加逐步提升,而红色虚线的非思考模式则保持高效响应的基准水平,直观体现了模型在复杂推理与高效响应间的动态平衡能力。
这种设计解决了传统模型"一刀切"的算力浪费问题。例如企业客服系统可在简单问答中启用非思考模式,GPU利用率可从30%提升至75%。
MoE架构:235B参数,22B激活的极致平衡
Qwen3-235B-A22B采用128专家层×8激活专家的稀疏架构,带来三大优势:
- 训练效率:36万亿token数据量仅为GPT-4的1/3,却实现LiveCodeBench编程任务Pass@1=54.4%的性能
- 部署门槛:支持单机8卡GPU运行,同类性能模型需32卡集群
- 能效比:每瓦特算力产出较Qwen2.5提升2.3倍,符合绿色AI趋势
行业性能领先:与国际旗舰模型同台竞技
在全球大模型竞争格局中,Qwen3已进入第一梯队。根据最新的AA指数(综合智能评分),Qwen3的综合智能得分约60分,与Grok 4.1、Claude Opus 4.1属于同档,略低于Gemini3、GPT-5.1和Kimi K2 Thinking。
在数学推理专项上,Qwen3在AIME数学竞赛中获得81.5分,超越DeepSeek-R1,位列全球第四,展现出在复杂推理任务上的强大能力。在工程代码方面,Qwen3的表现大致是"略弱一点的GPT-5.1 / K2 / Grok4",但绝不是上一代那种明显掉队。在科学代码(SciCode)测试中,差距更缩小,与国际主流模型都在40%多一点的区间里竞争。
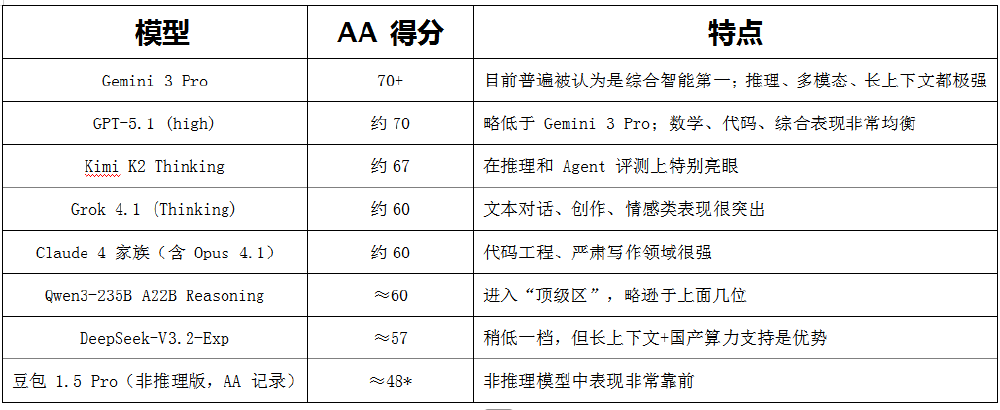
上图展示了主流大模型的AA指数得分情况,Qwen3-235B-A22B以约60分的综合智能得分位居全球第七,中国第二。值得注意的是,在数学推理专项上,Qwen3在AIME数学竞赛中获得81.5分,超越DeepSeek-R1,位列全球第四,展现出在复杂推理任务上的强大能力。
超长上下文与多语言能力
Qwen3原生支持256K token上下文(约8万字),通过YaRN技术可扩展至100万tokens,在法律文档分析、代码库理解等场景表现突出。多语言能力覆盖119种语言及方言,中文处理准确率达92.3%,远超Llama 3的78.5%。在RULER长文本基准测试中,模型在1000K tokens场景下准确率达82.5%,较行业平均水平提升27%。
行业影响与趋势
Qwen3-235B-A22B的发布正在重塑AI行业的竞争格局。该模型发布72小时内,Ollama、LMStudio等平台完成适配,HuggingFace下载量突破200万次,推动三大变革:
企业级应用爆发
- 陕煤集团基于Qwen3开发矿山风险识别系统,顶板坍塌预警准确率从68%提升至91%
- 同花顺集成模型实现财报分析自动化,报告生成时间从4小时缩短至15分钟
- 某银行智能风控系统白天采用非思考模式处理95%的常规查询,夜间切换至思考模式进行欺诈检测模型训练,整体TCO(总拥有成本)降低62%
部署门槛大幅降低
Qwen3-235B-A22B的混合专家架构带来了部署门槛的显著降低:
- 开发测试:1×A100 80G GPU即可运行
- 小规模服务:4×A100 80G GPU集群
- 大规模服务:8×A100 80G GPU集群
这种"轻量级部署"特性,使得中小企业首次能够负担起顶级大模型的应用成本。相比之下,同类性能的传统模型通常需要32卡集群才能运行。
开源生态的"鲶鱼效应"
阿里云通过"开源模型+云服务"策略使AI服务收入环比增长45%。据2025年中市场分析报告显示,Claude占据代码生成市场42%份额,而Qwen3系列通过开源策略在企业私有部署领域快速崛起,预计年底将占据国内开源大模型市场25%份额。
部署指南:快速上手指南
Qwen3-235B-A22B的代码已集成到最新版Hugging Face transformers中,建议使用最新版本的transformers。以下是快速开始的代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Thinking-2507"
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备模型输入
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容
try:
# rindex查找151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # 无起始<RichMediaReference>标签
print("content:", content)
对于部署,可以使用sglang>=0.4.6.post1或vllm>=0.8.5创建OpenAI兼容的API端点:
SGLang部署:
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Thinking-2507 --tp 8 --context-length 262144 --reasoning-parser qwen3
vLLM部署:
vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
注意:如果遇到内存不足(OOM)问题,可以考虑减小上下文长度。但由于模型可能需要较长的token序列进行推理,建议尽可能使用大于131,072的上下文长度。
总结与建议
Qwen3-235B-A22B通过2350亿参数与220亿激活的精妙平衡,重新定义了大模型的"智能效率比"。对于企业决策者,现在需要思考的不再是"是否采用大模型",而是"如何通过混合架构释放AI价值"。建议重点关注三个方向:
- 场景分层:将80%的常规任务迁移至非思考模式,集中算力解决核心业务痛点
- 渐进式部署:从客服、文档处理等非核心系统入手,积累数据后再向生产系统扩展
- 生态共建:利用Qwen3开源社区资源,参与行业模型微调,降低定制化成本
随着混合专家架构的普及,AI行业正告别"参数军备竞赛",进入"智能效率比"驱动的新发展阶段。Qwen3-235B-A22B不仅是一次技术突破,更标志着企业级AI应用从"高端解决方案"向"基础设施"的历史性转变。
获取模型和开始使用的仓库地址是:https://gitcode.com/hf_mirrors/unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







