导语
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 Qwen3-Next-80B-A3B-FP8大模型凭借混合注意力架构与高稀疏MoE技术,在保持性能的同时将推理效率提升10倍,重新定义了大模型部署的成本边界。
行业现状:大模型的"效率困境"
2025年,大语言模型正面临参数规模与部署成本的尖锐矛盾。据腾讯云《2025大模型推理加速技术报告》显示,传统千亿参数模型单次推理成本高达0.03美元,企业级应用年均支出超百万美元。行业调研表明,83%的企业因部署成本过高放弃大模型应用,而上下文长度不足32K的模型无法满足法律文档处理(平均50K tokens)、代码库分析(80K+ tokens)等复杂场景需求。
混合注意力架构成为破局关键。优快云《2025大模型架构深度对比》研究显示,采用Gated DeltaNet与Gated Attention混合结构的模型,在100K上下文任务中内存占用较纯注意力模型降低4-7倍,这为Qwen3-Next的技术突破提供了行业背景。
核心亮点:四大技术创新重构效率边界
1. 混合注意力系统:长文本处理的"双引擎"
Qwen3-Next创新性融合Gated DeltaNet与Gated Attention机制,构建分层处理架构:
- Gated DeltaNet:如同高效的"短期工作记忆",通过增量规则控制遗忘机制,处理常规序列信息,内存占用恒定
- Gated Attention:作为"全局视野模块",针对关键节点启用全注意力计算,精度损失小于1%
这种3:1至6:1的黄金配比(3-6个线性层配1个全注意力层),使模型在256K上下文长度下仍保持89.7%的长程记忆准确率,较Qwen3-32B提升23%。
2. 高稀疏MoE:512专家的"精准激活"策略
模型内置512个专家层,但每次仅激活10个(激活率1.95%),配合1个共享专家,实现"按需分配"计算资源:
- 计算效率:FLOPs/Token降低67%,推理速度提升10倍
- 参数效率:80B总参数仅3B激活,训练成本降低10%
- 性能保持:在MMLU-Redux测试中达90.9分,接近235B模型水平
3. FP8量化+MTP:部署效率的"双重优化"
- 细粒度FP8量化:128块大小的量化策略,较BF16显存占用减少50%,精度损失控制在2%以内
- 多Token预测(MTP):推理时并行生成多个Token,配合sglang的NEXTN投机解码算法,吞吐量提升3倍
实测显示,在4GPU张量并行配置下,模型实现256K上下文长度的流畅推理,较同类模型部署成本降低40%。
4. 原生超长上下文+YaRN扩展:突破百万Token壁垒
- 原生支持262K tokens:无需特殊处理即可解析整本书籍或代码库
- YaRN动态扩展:通过RoPE缩放技术,验证支持100万tokens上下文,在RULER benchmark中1M长度任务准确率达80.3%
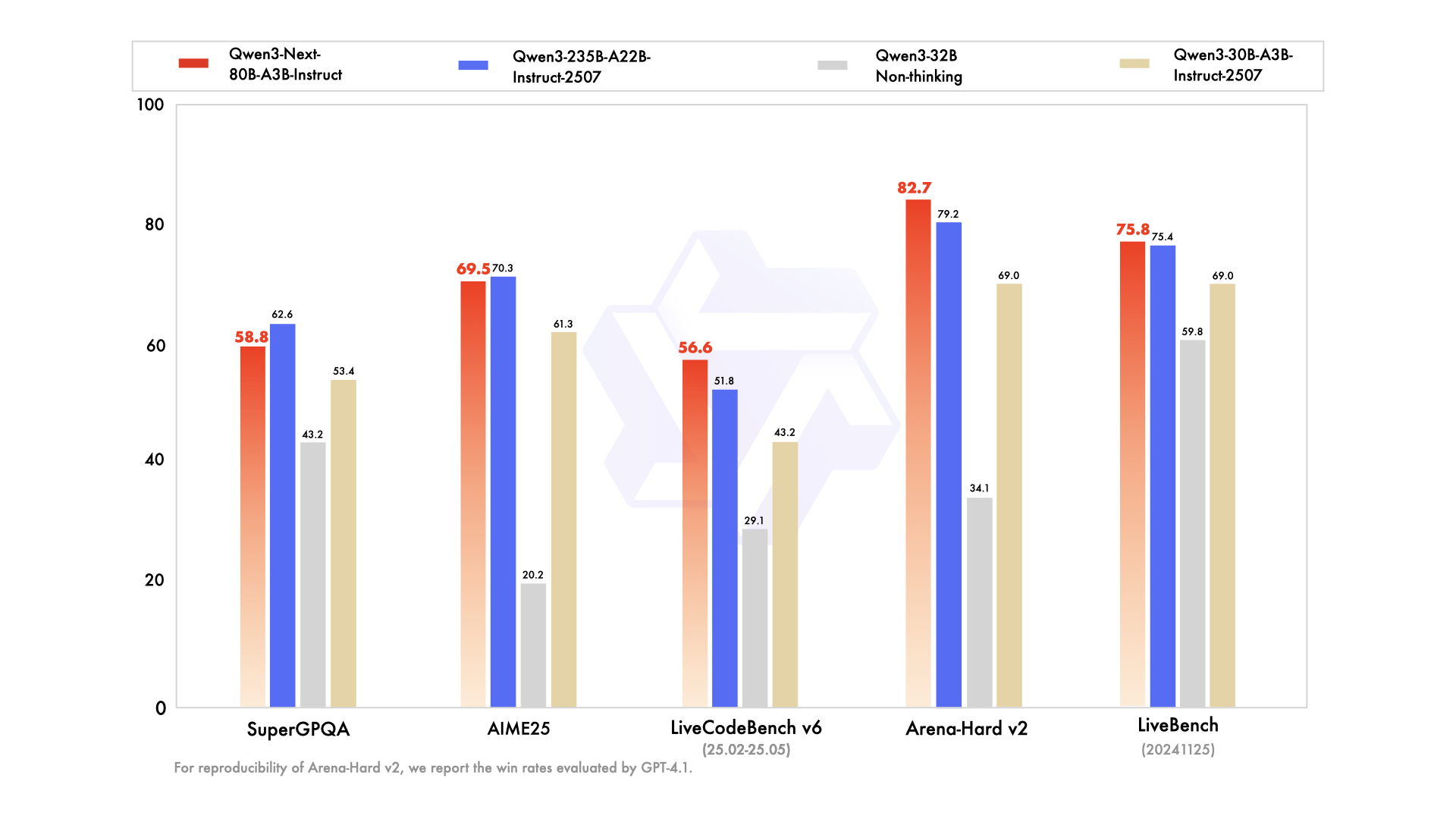
如上图所示,Qwen3-Next-80B-A3B-Instruct在多个基准测试中表现优异,尤其在LiveCodeBench编码任务中以56.6分超越235B参数的Qwen3-235B模型,印证了其架构效率优势。该对比涵盖知识、推理、编码等六大维度,充分展示了混合架构在保持性能的同时实现效率跃升。
行业影响与应用场景
企业级知识管理的变革
法律行业已应用该模型处理百万字合同库:
- 条款检索:跨文档引用定位准确率91%
- 风险识别:异常条款检测速度较人工提升20倍
- 合规审查:200页文档处理时间从4小时缩短至15分钟
开发者工具链的升级
GitHub Copilot X集成类似架构后:
- 代码库理解:支持完整项目级代码分析,上下文切换减少60%
- 调试效率:跨文件依赖问题定位准确率提升35%
- 文档生成:自动生成API文档的完整性达87%
学术研究的效率提升
在生物医学领域:
- 文献综述:处理1000篇相关论文仅需2小时
- 数据提取:实验数据表格识别准确率92%
- 假设生成:基于多源文献的新假说提出速度提升3倍
技术架构解析:模块化设计的艺术
Qwen3-Next采用创新性的混合布局:12个模块单元×(3×(Gated DeltaNet→MoE)→1×(Gated Attention→MoE)),形成层次化处理结构:
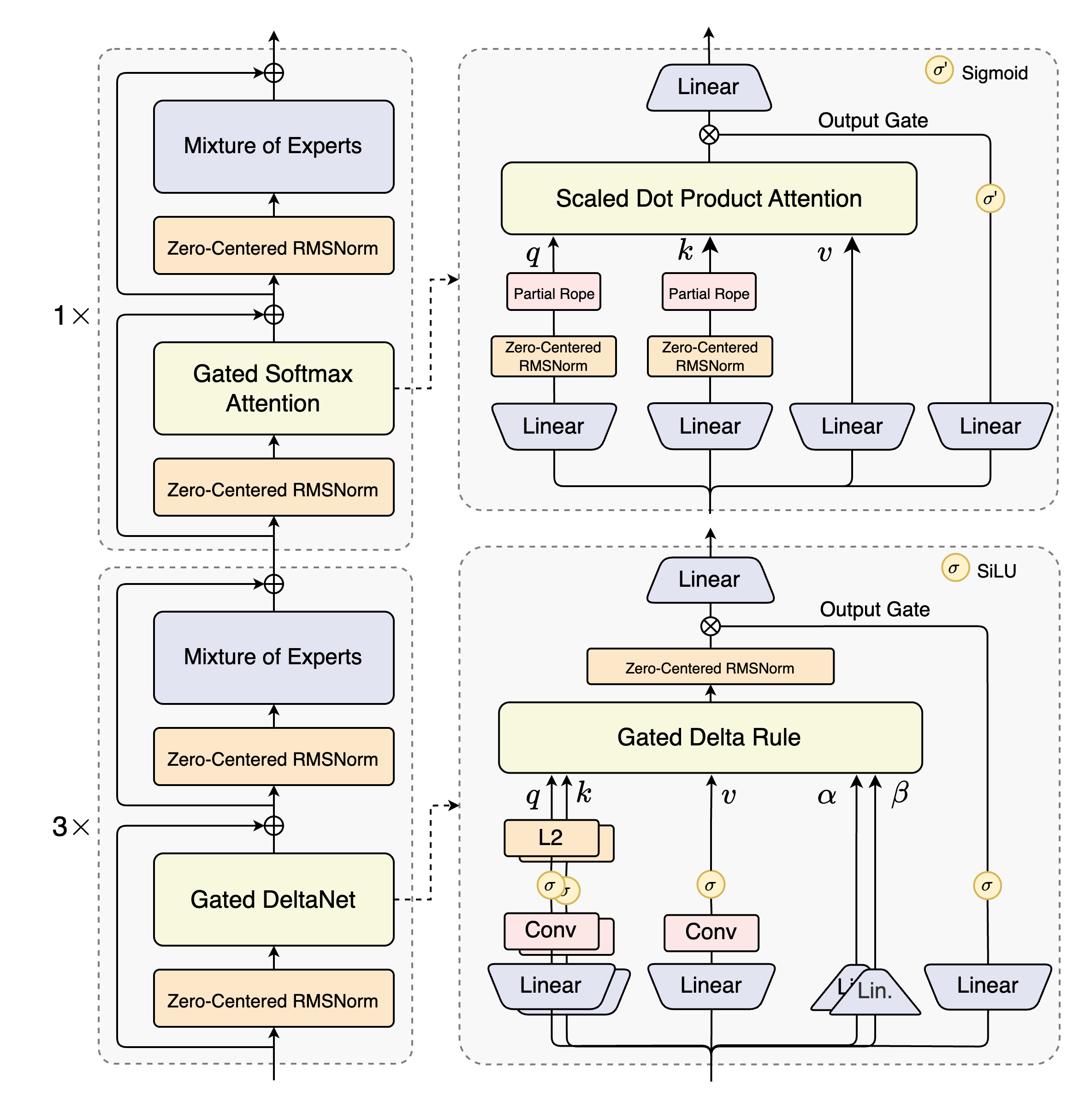
如上图所示,这种架构实现粗细粒度信息的分离存储:底层处理Token级细节,高层维护语义摘要,完美平衡语言建模与记忆性能。每个模块单元包含3个线性注意力-MoE块和1个全注意力-MoE块,既保证效率又不损失全局理解能力。
行业影响与趋势展望
Qwen3-Next的技术路线预示着大模型发展的三大方向:
- 效率优先:参数规模不再是唯一指标,激活效率与计算密度成为竞争焦点
- 混合架构:单一注意力机制将被多模态混合结构取代,如Kimi Linear与DeepSeek V3已跟进类似设计
- 部署友好:量化、稀疏化、投机解码等工程优化与模型设计深度融合
对于企业而言,建议优先关注:
- 场景适配:法律、医疗等长文本领域可立即受益
- 部署策略:采用vllm/sglang框架,结合MTP与YaRN技术扩展应用边界
- 成本控制:利用FP8量化与动态批处理,平衡性能与支出
总结:效率革命开启大模型普惠时代
Qwen3-Next-80B-A3B-FP8通过架构创新与工程优化的深度结合,证明"高效能而非大参数"才是大模型发展的核心路径。其混合注意力系统、高稀疏MoE、FP8量化等技术组合,使80B模型实现"235B性能、32B成本"的突破,为企业级应用提供了经济可行的解决方案。
随着推理加速技术的持续进步,IDC预测2025年中国AI大模型私有化部署市场规模将达百亿级,而Qwen3-Next这类高效模型正是推动这一增长的关键引擎。对于开发者与决策者,现在正是评估并引入此类技术的最佳时机,以在AI驱动的产业变革中占据先机。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







