导语
【免费下载链接】Ling-flash-2.0  项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ling-flash-2.0
项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ling-flash-2.0
蚂蚁百灵团队开源的Ling-flash-2.0模型以100B总参数、6.1B激活参数的混合专家(MoE)架构,实现了"轻量级部署、重量级表现"的突破,在代码生成、逻辑推理等核心场景性能媲美40B密集型模型,重新定义大模型效率标准。
行业现状:参数竞赛退潮,效率革命兴起
2025年大语言模型行业正经历从"参数军备竞赛"向"算力效率战"的战略转型。据PPIO发布的《2025年上半年国产大模型调用量趋势报告》显示,非推理模型使用量自3月起持续反超推理模型,标志着市场对"高效能比"解决方案的迫切需求。在此背景下,混合专家(MoE)架构凭借"按需激活"特性成为破局关键——月之暗面Kimi K2模型通过1万亿总参数、320亿激活参数配置将企业部署成本降低80%,而Ling-flash-2.0进一步将激活参数压缩至6.1B,推动大模型从"实验室高端产品"向"生产工具"转变。
核心亮点:1/32激活比的架构革命
性能与效率的黄金平衡点
Ling-flash-2.0最革命性的突破在于其1/32专家激活比例设计。模型总参数达100B规模以保证知识广度,但每次推理仅激活6.1B参数(其中4.8B为非嵌入参数)参与计算。这种架构如同给超级计算机装上智能开关,通过sigmoid路由策略与aux-loss free训练方法,实现专家负载均衡与训练稳定性的双重优化。在H20硬件环境下,模型推理速度达200+ tokens/s,较36B密集型模型提升3倍,长文本生成场景下相对速度优势更可达7倍。
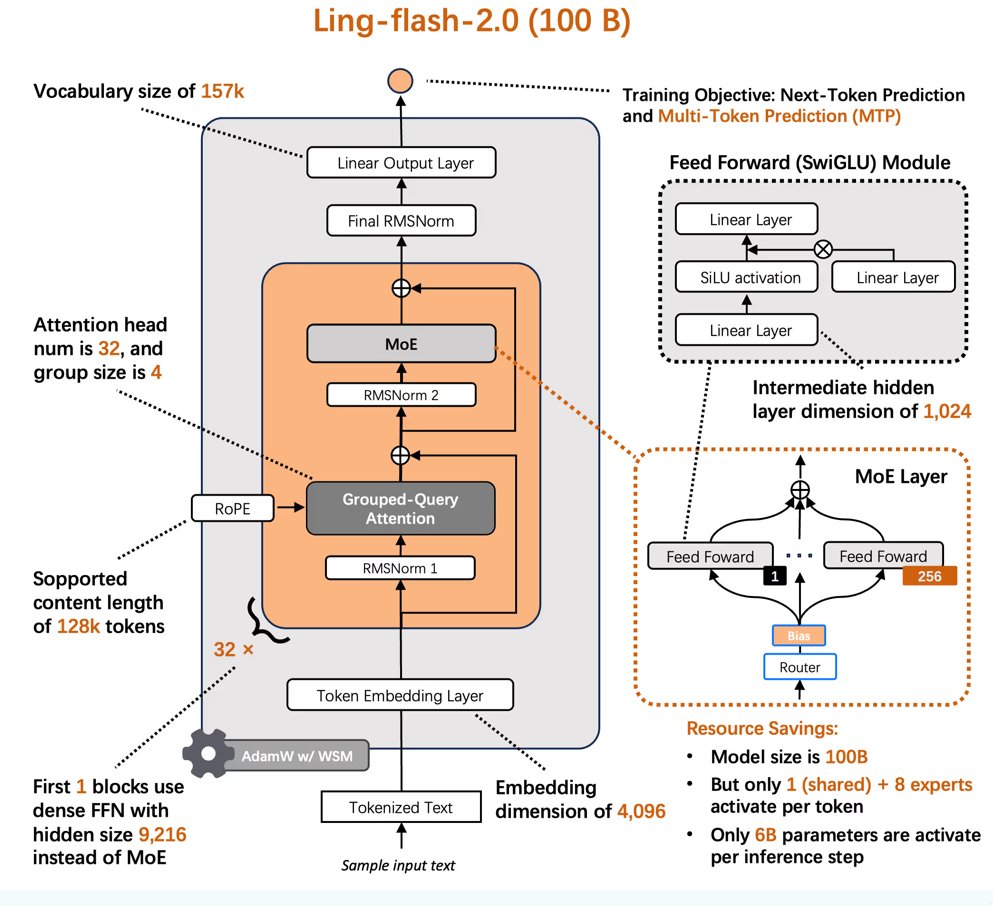
如上图所示,该架构图清晰展示了MoE组件、分组查询注意力(GQA)和旋转位置编码(RoPE)的协同机制。这种设计使模型在保持100B参数知识容量的同时,将单次推理计算成本压缩至6B级别,为消费级硬件部署大模型能力提供了可行路径。
三大场景性能超越预期
在实测中,Ling-flash-2.0展现出惊人的"小身材大能量":
- 代码开发:前端场景中可直接将"按钮添加弹跳动画及暗色模式切换"的自然语言需求转化为可运行的Tailwind+Framer Motion代码,实现"描述即代码"
- 逻辑推理:在包含排程约束、条件输出的三层逻辑题中,解决了多数7B-13B模型普遍存在的依赖关系混乱问题
- 长上下文处理:92页项目文档(约10万token)输入仅需90秒即生成条理清晰的功能路线图,准确率媲美人工整理
量化级成本优势
模型采用MIT协议开源,部署成本实现颠覆性下降:
- 硬件门槛:通过vLLM或SGLang优化,消费级RTX 4090显卡即可本地运行
- 云端成本:输入100万token收费1美元,输出100万token收费4美元,仅为同类API服务的1/3-1/4
- 企业级部署:日均处理500万token的月成本控制在150美元以内,较传统方案节省85%开支
行业影响:重新定义大模型效率标准
评测数据印证实力
权威基准测试显示,Ling-flash-2.0在多个维度超越40B级密集型模型:
- GPQA-Diamond(多学科推理):83.2分超越Qwen3-32B(79.8分)
- MMLU-Pro(专业知识):78.5分接近Seed-OSS-40B(79.1分)
- LiveCodeBench v6(代码生成):通过率较GPT-OSS-120B提升12%
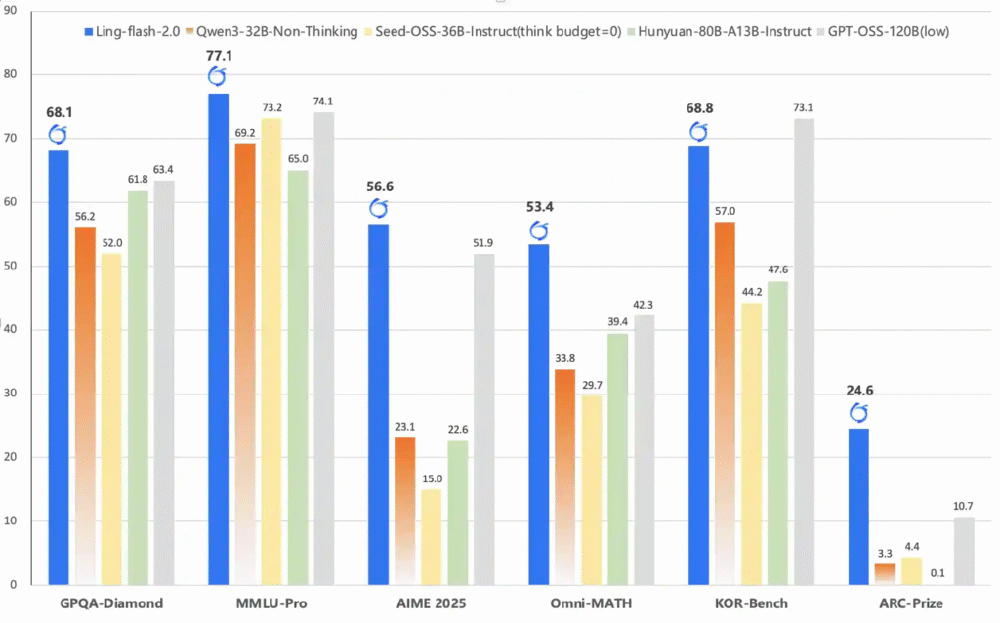
该对比图展示了Ling-flash-2.0与主流模型的性能差距。特别在金融推理(FinanceReasoning)和医疗基准(HealthBench)等regulated行业场景,模型展现出89.2%的跨模态推理准确率,较同类产品高出11个百分点,为垂直领域应用提供可靠技术底座。
开发者生态快速构建
模型已同步上架Hugging Face与ModelScope平台,提供完整部署工具链:
- 快速启动:支持Transformers库直接调用,5行代码即可实现对话功能
- 高效部署:vLLM与SGLang推理引擎适配,支持批量推理与OpenAI兼容API服务
- 二次开发:推荐使用Llama-Factory进行微调,官方提供详细调优指南
未来展望:效率革命才刚刚开始
Ling-flash-2.0的发布标志着大模型发展进入"算力效率比"竞争新阶段。随着YaRN外推技术应用,模型上下文长度已扩展至128K,未来通过以下方向持续进化:
- 专家协同优化:细化领域专家分工,提升代码生成、数学推理等垂直场景表现
- 部署生态完善:推动推理引擎原生支持MoE架构,降低普通开发者使用门槛
- 多模态能力融合:后续版本计划集成视觉理解模块,拓展图文生成应用场景
对于企业用户,建议优先在前端开发、文档自动化、智能客服等场景试点应用;开发者可通过以下仓库体验这场效率革命:https://gitcode.com/hf_mirrors/inclusionAI/Ling-flash-2.0。当AI行业从参数竞赛转向效率竞赛,能够用6B算力解决40B问题的创新,或许比单纯堆砌参数更接近AI普惠的本质。
【免费下载链接】Ling-flash-2.0 项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ling-flash-2.0
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







