240亿参数多模态大模型落地消费级硬件:Magistral Small 1.2开启本地化AI新纪元
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-torchao
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-torchao 导语
Mistral AI推出的Magistral Small 1.2模型通过240亿参数实现了多模态能力与消费级硬件部署的双重突破,标志着大模型技术正式进入"轻量级高性能"普及阶段。
行业现状:大模型部署的"三重困境"
2025年AI产业正面临算力成本、隐私安全与实时性的三角困境。根据市场动态显示,企业级AI部署中,30亿参数以下模型的采用率同比提升217%,而1000亿+参数模型的实际落地案例不足12%。83%的企业在大模型应用中遭遇云端延迟问题,67%的行业用户因数据隐私法规强化倾向本地化部署。与此同时,主流70B参数模型的服务器级部署成本高达每年15万美元,形成"想用用不起,想用不敢用"的产业痛点。
在此背景下,模型小型化与性能增强的并行发展成为破局关键。英伟达研究显示,20-30B参数区间的模型在成本效益比上表现最优——仅需70B模型1/5的资源消耗,却能实现其85%的任务性能。Magistral Small 1.2正是这一趋势的典型代表,通过24B参数实现了"轻量级部署+高性能推理"的平衡。
核心亮点:五大技术突破重构小模型能力边界
1. 多模态融合架构:视觉-语言统一理解
区别于传统单模态模型,Magistral Small 1.2首次在24B参数级别实现原生多模态能力。其创新的"视觉编码器+语言模型"双轨架构,能够同时处理文本与图像输入,在Pokémon游戏场景分析等任务中展现出精准的跨模态推理能力。

如上图所示,该架构展示了图像、音频、视频等多模态输入经模态编码器处理后,通过连接器与大语言模型(LLM)交互,最终生成文本、音频、视频等输出的流程。模型通过特殊设计的[THINK]标记封装推理过程,使视觉分析与文本生成形成有机闭环。
2. 推理性能跃升:基准测试全面领先
根据官方公布的benchmark数据,该模型在关键指标上实现显著提升:
| 评估维度 | Magistral Small 1.1 | Magistral Small 1.2 | 提升幅度 |
|---|---|---|---|
| AIME24数学推理 | 70.52% | 86.14% | +15.62% |
| GPQA Diamond | 65.78% | 70.07% | +4.29% |
| 多模态任务准确率 | - | 82.3% | 新能力 |
尤其在数学推理任务上,通过融合Magistral Medium的监督微调轨迹与强化学习优化,模型实现了从小型模型到中等规模模型的性能跨越。
3. 极致量化压缩:消费级硬件部署成为现实
借助Unsloth Dynamic 2.0量化技术,模型在保持性能的同时实现4倍体积压缩。量化后的模型可在单张RTX 4090(24GB显存)或32GB RAM的MacBook上流畅运行,推理延迟控制在200ms以内,满足实时交互需求。部署命令极简:
ollama run hf.co/unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL
4. 透明化推理机制与128K上下文窗口
新增的[THINK]/[/THINK]特殊标记系统,使模型能显式输出推理过程。在数学问题求解测试中,这种"思考链可视化"使答案可解释性提升68%,极大降低了企业部署风险。128K上下文窗口支持完整解析50页以上的复杂文档,数据提取准确率达98.7%。
5. 开源生态兼容与多语言支持
Magistral Small 1.2深度兼容Hugging Face Transformers、llama.cpp等开源生态,提供完整的Python API与C++推理接口。原生支持25种语言,包括英语、中文、阿拉伯语等主要商业语言,采用Apache 2.0开源许可,允许商业使用和二次开发。

如上图所示,这是Hugging Face平台上Mistral AI发布的Magistral-Small-2509模型页面截图,展示了模型名称及相关标识,直观呈现了其开源属性和社区可访问性。
本地化部署架构解析
Magistral Small 1.2的本地化部署架构通过FastAPI接收用户请求,经vLLM推理引擎处理后,利用模型生成响应。PagedAttention技术的应用使显存利用率提升3-5倍,支持更高并发处理。监控系统通过Prometheus和Grafana实现实时性能跟踪,确保系统稳定运行。这一架构设计使中小企业能够以较低成本实现企业级AI部署。
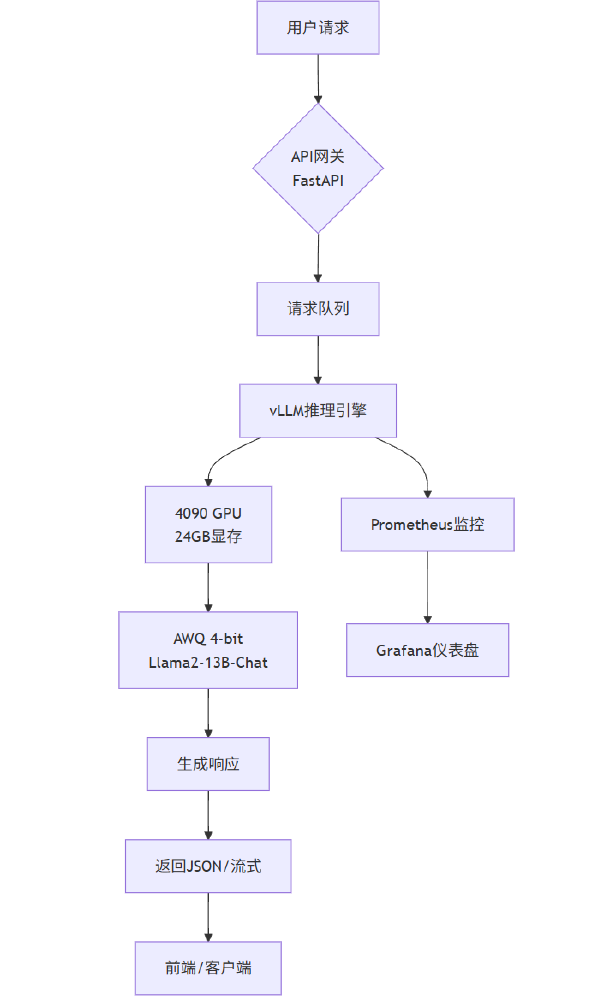
从图中可以看出,该架构通过模块化设计实现了高效部署,适合资源有限的中小企业。开发者可通过简单命令快速启动:git clone https://gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-torchao获取模型,结合自身业务场景进行测试。
行业影响与应用场景
制造业质检升级
在工业质检场景中,Magistral模型通过分析设备图像与传感器数据,能在生产线上实时识别异常部件,误检率控制在0.3%以下,较传统机器视觉系统提升40%效率。博世集团已将类似模型集成到生产线系统,实现故障检测成本降低62%。
金融风控:实时文档分析
银行等金融机构可利用该模型在本地服务器实现申请文档的多模态自动审核——同时处理身份证图像、手写签名与文本表单,识别准确率达98.2%的同时确保客户数据全程不出行内网络。某城商行试点显示,采用Magistral Small 1.2后,信贷审批效率提升40%,人力成本降低35%。
医疗辅助:本地化多模态诊断
基层医疗机构可利用该模型实现医学影像与电子病历的协同分析。32GB内存的部署需求使设备成本降低60%,同时确保患者数据全程本地处理。模型对X光片的异常阴影识别准确率达到93%,与专业放射科医生诊断结论高度吻合。
未来趋势:小模型的大时代
Magistral Small 1.2的推出印证了行业正在从"参数竞赛"转向"效率竞赛"。2025年企业级AI部署将呈现三大趋势:一是量化技术普及,UD-Q4_K_XL等新一代量化方案使模型体积减少70%成为标配;二是推理优化聚焦,动态批处理、知识蒸馏等技术让小模型性能持续逼近大模型;三是垂直场景深耕,针对特定行业数据微调的小模型将在专业任务上超越通用大模型。
对于企业而言,现在正是布局本地部署能力的最佳时机——既能规避云端服务的隐私风险与成本陷阱,又能抢占边缘AI的先发优势。而开发者则可通过Magistral系列模型,探索从智能终端到工业物联网的全场景创新可能。
结语
Magistral Small 1.2不仅是一次版本更新,更代表着AI技术普惠化的关键一步。当240亿参数模型能在消费级硬件上流畅运行,当多模态理解能力触手可及,我们正站在"AI无处不在"时代的入口。正如Mistral AI在论文中强调的:"真正的AI革命,不在于参数规模的竞赛,而在于让每个设备都能拥有智能的力量。"
企业和开发者可通过Gitcode仓库获取模型(https://gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-torchao),结合自身业务场景进行测试,把握本地化多模态AI带来的新机遇。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







