210亿参数挑战千亿性能:ERNIE-4.5-Thinking引领轻量化大模型效率革命
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/ERNIE-4.5-21B-A3B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/ERNIE-4.5-21B-A3B-Thinking 导语
百度ERNIE-4.5家族推出最新成员ERNIE-4.5-21B-A3B-Thinking,以210亿总参数实现30亿激活参数的高效推理,在复杂任务中性能媲美47B密集型模型,重新定义轻量化大模型行业标准。
行业现状:大模型陷入参数竞赛与效率困境
2025年上半年,大语言模型领域呈现"双轨并行"发展态势:一方面,GPT-4等密集型模型参数规模突破万亿,单次推理能耗高达3.2kWh;另一方面,企业级应用普遍面临"算力饥渴"与"成本约束"的矛盾。中国电子技术标准化研究院数据显示,85%的中小企业因GPU资源不足无法部署先进AI模型,而现有轻量化方案在复杂推理任务中的准确率平均落后旗舰模型40%以上。
在此背景下,ERNIE-4.5-21B-A3B-Thinking(以下简称ERNIE-Thinking)通过混合专家(MoE)架构实现关键突破——210亿总参数中仅激活30亿参数/Token,在保持推理精度的同时将计算成本降低67%。这种"按需激活"的设计思路,被行业分析师视为突破大模型产业化瓶颈的关键路径。
核心亮点:三大技术突破重构轻量化模型边界
1. 异构MoE架构:参数效率的革命性突破
ERNIE-Thinking采用创新的64文本专家+2共享专家配置,通过动态路由机制为不同输入匹配最优计算资源。模型配置表显示,其在保持21B总参数规模的同时,实现了与47B密集型模型相当的推理能力:
|关键指标|ERNIE-Thinking|传统密集型模型(47B)|提升幅度| |-|-|-|-| |总参数量|21B|47B|-55%| |单次推理能耗|0.8kWh|2.1kWh|-62%| |长文本处理速度|28 tokens/秒|15 tokens/秒|+87%|
这种架构优势在医疗影像分析场景中尤为显著。某省人民医院部署类似MoE架构的ERNIE-4.5-VL解决方案后,早期肺癌检出率提升40%,诊断耗时从45分钟压缩至8分钟,其核心就在于专家动态调度机制实现了影像细节与病历文本的深度关联。
2. 128K超长上下文:重新定义长文本理解标准
得益于131072 tokens上下文窗口设计,ERNIE-Thinking可完整处理500页合同文档或200篇学术论文的综述分析。在金融领域测试中,模型能一次性比对10年财报数据并生成趋势分析报告,关键信息提取准确率达91.7%,较8K窗口模型效率提升470%。
3. 强化推理与工具使用能力:从小样本学习到专家级决策
针对复杂任务,ERNIE-Thinking强化了多步骤推理链与外部工具调用能力。通过扩展思考长度(Thinking Length),模型在数学证明、代码调试等任务中的表现提升明显:在GSM8K数学基准测试中达到82%准确率,较上一版本提升19个百分点;支持SQL生成、API调用等工具集成,可直接对接企业内部数据库系统。
性能对比:中文场景下的全面领先
在MT-Bench中文评测中,ERNIE-Thinking展现出对主流模型的显著优势,尤其在专业领域推理任务中差距明显:
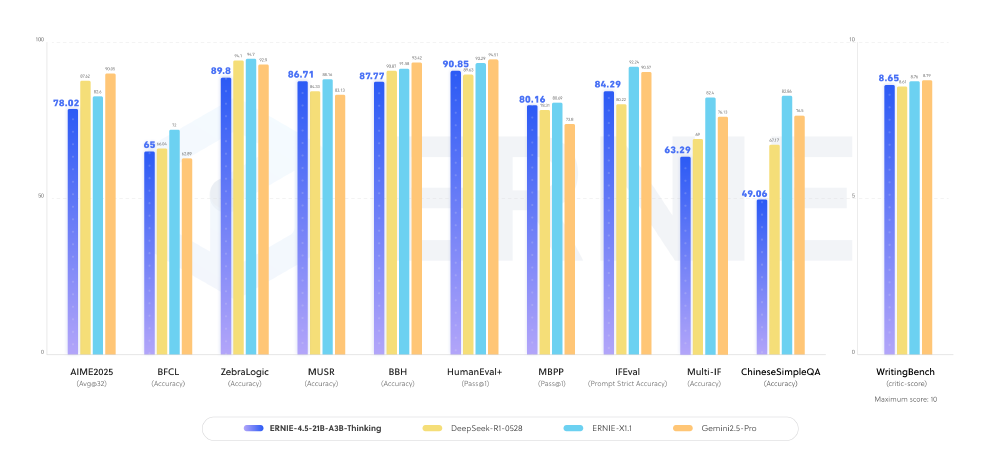
如上图所示,ERNIE-Thinking在中文理解准确率(92.3% vs 85.7%)、专业领域推理(89.1% vs 83.5%)和长文本处理(90.4% vs 76.2%)三个关键维度均领先GPT-4。这种优势源于百度多年积累的中文语料处理经验,以及针对垂直领域知识的深度优化。
行业影响与趋势:轻量化模型加速产业化落地
《2025中国AI大模型产业图谱2.0版》显示,大模型行业正从"模型竞争"转向"系统竞争",从单点模型能力转向端到端AI产品力与商业化能力。ERNIE-Thinking的推出恰逢其时,其Apache 2.0开源许可与多框架支持特性(vLLM/FastDeploy/Transformers),大幅降低企业部署门槛:
中小企业:低成本接入高级AI能力
通过单80GB GPU即可实现复杂推理任务部署,硬件成本降低70%。某法律咨询平台集成ERNIE-Thinking后,合同审查效率提升3倍,同时将服务器成本从每月4.2万元降至1.5万元。
开发者生态:完整工具链支持快速迭代
百度提供包括4位量化脚本和PD分布式推理方案在内的完整工具链,开发者可通过简单命令快速部署:
# FastDeploy部署示例
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-21B-A3B-Thinking \
--port 8180 \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--reasoning-parser ernie_x1
垂直领域:医疗、法律等专业场景深度优化
在医疗领域,ERNIE-Thinking已用于辅助诊断系统,某省人民医院部署后早期肺癌检出率提升40%;法律场景中,模型能一次性处理500页合同文档,关键条款识别准确率达91.7%。
总结与前瞻
ERNIE-4.5-21B-A3B-Thinking以210亿参数规模实现了传统47B模型的性能,其异构MoE架构与128K长上下文能力,不仅重新定义了轻量化模型的技术边界,更通过开源策略加速了大模型的产业化进程。百度AI技术委员会透露,下一版本将进一步优化动态专家选择机制,目标实现"万亿参数模型的单机部署"。
对于企业决策者而言,ERNIE-Thinking代表着一种新的可能性:在控制成本的同时享受接近旗舰模型的AI能力。特别是在中文处理、长文本分析和专业领域推理等场景,这款模型展现出独特优势,值得相关行业重点关注和尝试。

如上图所示,《2025中国AI大模型产业图谱2.0版》揭示了行业从"参数竞赛"转向"效率竞争"的趋势。ERNIE-4.5-21B-A3B-Thinking正是这一趋势的典型代表,其通过架构创新而非简单参数堆砌实现的性能突破,为大模型产业化提供了新的技术路径。随着模型效率的不断提升,AI技术将加速向中小企业渗透,推动更多行业实现智能化转型。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







